数据库理论(六)——数据库恢复
数据库理论(六)——数据库恢复
在数据库的数据操作过程中,通常会经过两个部分,一个是经过数据文件,对数据进行读写,还有一个部分会进入日志文件对数据库的操作行为进行记录
数据库操作的组织模式
事物(Transaction)
- 一个数据库操作序列
- 一个不可分割的工作单元
- 恢复和并发控制的基本单元
事物定义的sql语句
1 | -- 显式定义 |
数据库故障
事物内部的故障
比如:运算溢出,发生死锁,违反某些完整性限制
发生事物故障时,事物中的操作一部分已经发生,一部分还没有开始,因此需要对发生的操作进行撤销(UNDO)
系统故障
造成系统停止运转的任何事件:
1. 系统要重新启动
2. 所有正在运行的事物都非正常终止
3. 没有破坏数据库
4. 内存中数据库缓冲区的信息全部丢失
典型的系统故障:
1. 特定类型的硬件错误(CPU故障)
2. 操作系统故障
3. DBMS代码错误
4. 系统断电
系统故障可能导致的现象
- 事物未执行完成
- 恢复策略:强行撤销(UNDO)所有未完成事物
- 事物已执行完成(提交),但缓冲区中的数据尚未完全写回到磁盘上
- 恢复策略:重做(REDO)所有已提交的事物。
介质故障
硬故障,指外存故障
- 磁盘损坏
- 磁盘碰撞
- 操作系统的某种潜在错误
- 瞬时强磁场干扰
介质故障的恢复策略:装入数据库发生介质故障前某个时刻的数据副本,重做自此时开始的所有成功事物,将这些事物已提交的结果重新写入数据库
数据库恢复技术
**数据库恢复:**把数据库从错误状态恢复到某一已知的正确状态(亦称为一致状态或完整状态)
恢复机制涉及的关键问题:
1. 如何建立冗余数据
2. 如何利用这些冗余数据实施数据库恢复
建立冗余数据的基本技术
- 数据转储(数据备份)
- 数据转存是指DBA将整个数据库复制到磁带或另一个磁盘上,保存起来的过程,备用的数据成为后备副本或后援副本
- 登录日志文件
- 日志文件:记录事物对数据库进行更新的操作(包括操作类型,操作时间,操作用户,操作结束等)的文件。
- begin transaction表示各个事物的开始标记
- commit和rollback表示各个事物的结束标记
在事物的执行过程中,必须先写日志文件,然后再写入数据库中
事物故障:事物在运行至终止点被终止
恢复方法:数据库恢复子系统利用日志文件撤销(undo)此事物已对数据库进行的修改
系统故障恢复
- 未完成事物对数据库的更新已经写入数据库
- 已提交事物对数据库的更新还留在缓冲区没来得及写入数据库
恢复方法:
1. undo故障发生时未完成的事物
2. redo已完成的事物
系统故障的恢复由系统在冲洗启动时自动完成,无需用户干预
讲了这么多举个例子吧
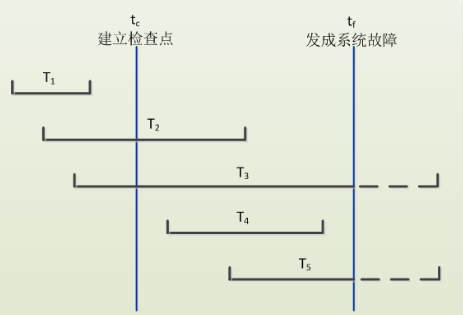
事物T1在检查点之前就完成了,不在考虑范围内
T2在检查点开始前就执行了,并且在发生故障之前就commit了,所以需要redo
T3在检查点之前执行,在发生故障前还没有commit,要进行撤销(undo)
T4在检查点之后故障之前执,并且在发生故障之前commit,所以要进行重做(redo)
T5在检查点之后故障之前执行,故障发生后还没有commit所以要进行撤销(undo)
简单总结一下吧,反正在检查点之后,故障之前commit都要是
上面的图太直接了,我们来看个复杂一点的:
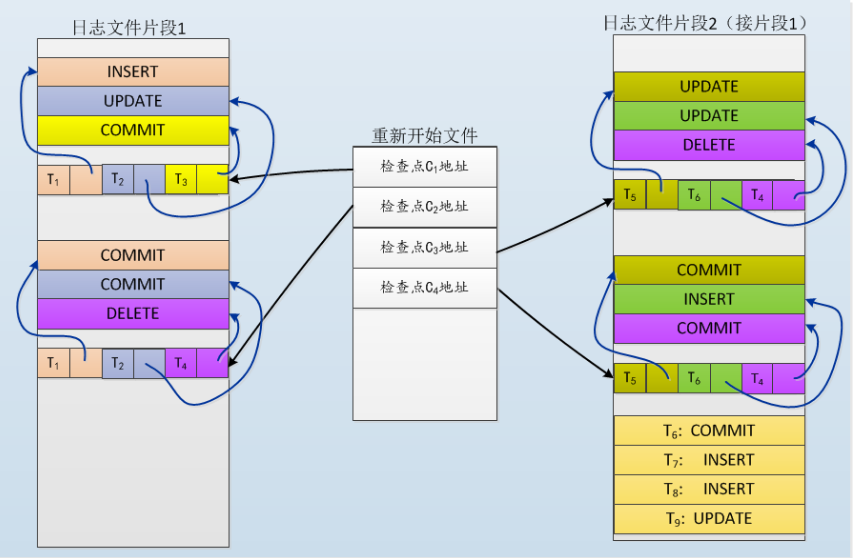
假设,我们的故障发生在T6(日志文件片断2的右下角)结束后,那么我们应该怎么对数据库进行恢复呢?
首先我们要找到故障发生前最近的检查点,从中间的文件中可以看出,最近的检查点应该在T5开始前(C4检查点,日志文件片断2的右下角),通过这个检查点将上图转化成我们认识的图像:
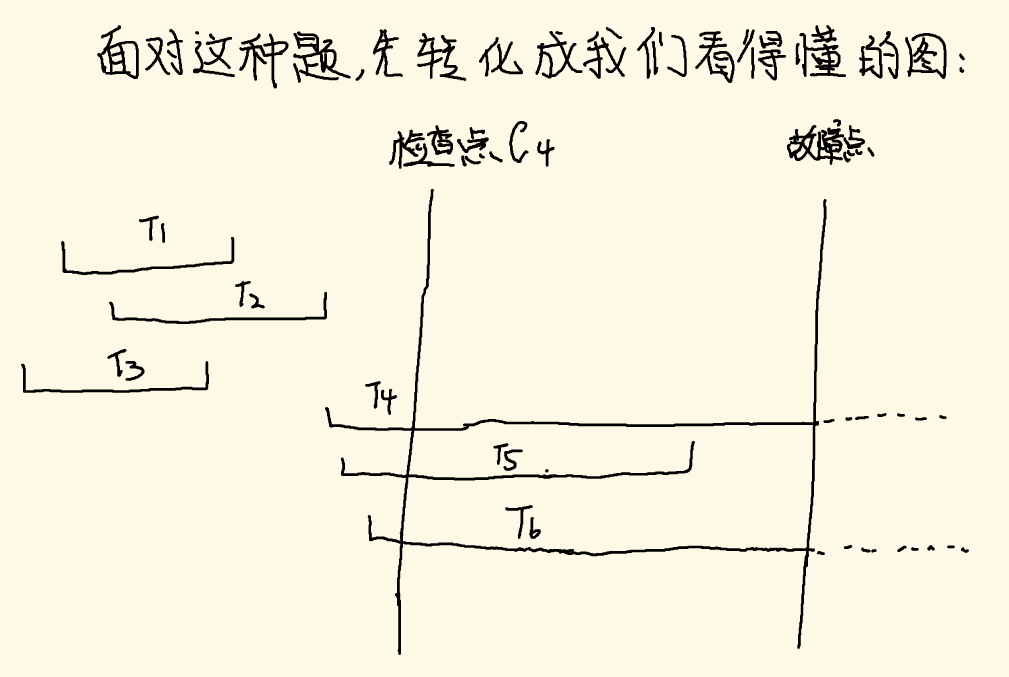
从图像中可以看出在检查点C4之前,T1,T2,T3已经完成了commit,这个我们就不用管了;
然后在C4前,开始了T3,T5,T6;
在C4后故障前只有,T5完成了commit;
因此真正需要redo的只有T5,而T4,T6都要undo










