Non-local Neural Networks
Non-local Neural Networks
论文名称:Non-local Neural Networks
作者:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He
期刊:CVPR2018
原文摘要
Both convolutional and recurrent operations are building blocks that process one local neighborhood at a time. In this paper, we present non-local operations as a generic family of building blocks for capturing long-range depen- dencies. Inspired by the classical non-local means method [4] in computer vision, our non-local operation computes the response at a position as a weighted sum of the features at all positions. This building block can be plugged into many computer vision architectures. On the task of video classification, even without any bells and whistles, our non-local models can compete or outperform current competition winners on both Kinetics and Charades datasets. In static image recognition, our non-local models improve object de-tection/segmentation and pose estimation on the COCO suite of tasks. Code is available athttps://github.com/facebookresearch/video-nonlocal-net
摘要重点抽取
在本文中,受到计算机视觉分类领域中的非局部均值方法的启发,本文提出的非局部操作为计算所有位置与当前位置的特征权重和作为当前位置的响应。
该结构可以插入到许多计算机视觉的网络架构中。在视频的分类任务中,non-local即使没有任何花里胡哨的成分,也在Kinetics和Charades数据集胜过最近的模型。
同时non-local模块还能模型在coco数据集的目标检测,分割以及姿势识别任务中的表现。
介绍
在神经网络中获取长距离依赖信息是非常重要的,比如循环神经网络中通过循环来获取长期的信息,在卷积神经网络中,通过不断地卷积堆叠来扩大图像的感受野。这些操作都依赖于重复计算,逐步传递i信息来获取长期数据。
这种通过重复本地操作获取长距离依赖信息有几个缺点:
- 计算效率低下
- 导致优化器对模型的优化困难,需要小心设计网络结构
- 当需要在远距离位置之间来回传递消息时,多跳跃连接建模变得困难
在本文中提出了一种有效,简洁并且通用的非本地操作组件,用于长距离依赖计算。该非本地操作是对在计算机视觉领域经典的非局部均值操作的概括。一种非局部操作计算的结果应该是输入的所有特征图的所有位置对一个位置的特征权重和。这一系列的位置可以是空间信息,也可以是时间信息,被应用与图像,序列和视频问题。
non-local操作的优点在于:
- 对比与卷积和循环操作,non-loacal操作经过计算任意两个位置的相互左右(不论位置的距离)获取的长距离依赖更加准确
- non-local只使用简单几层就可以实现高效及最佳效果。
- non-local可以保持输入的尺寸,能够轻易地与其他操作结合
Non-local Neural Networks
公式
在深度神经网络中通用的non-local操作公式如下所示
i表示当前要计算位置的索引,j是其他所有位置的索引,x是输入(图像,序列),y是尺寸与x相同的输出,二元函数f计算的是i与所有的j之间的一个标量,一元函数g计算的是输入在位置j的表示。计算结果会被因子归一化。
上述公式设计的愿意你是所有的位置在操作过程中都应该被考虑。一个non-local操作是一个灵活的构建块,可以和卷积层和循环层一起使用。他可以被添加在深度神经网络的前期部分。而不是向fc层一样用于网络的结束部分。这使得我们能够构建一个结合了局部与非局部信息的更丰富的层次结构。
实例
从简单出发,只把函数g考虑成线性embedding(这个词代表的技术,应该是将离散值转化成连续值的一种方法):,其中,是一个可学习的权重矩阵。其被使用的方式就像空间上的1x1卷积和1x1x1卷积在时空上。
下面介绍几种二元函数f的选择:
-
Gaussian(高斯函数)
其中是点积相似度,欧几里得距离也是可以使用的,但是在现在的深度学习平台中点积的更加容易实现。归一化的因子被设置为
-
Embedded Gaussian(嵌入高斯函数)
其中,是两个embedings。同上,归一化因子同样设置为
本文注意到最近提出的用在机器翻译上的自注意力模块是一种特殊的embedded Gaussian版本的non-loacal操作
-
Dot product(点积)
f被定义为点积相似度的形式:
这里采用了Embedded Gaussian版本。在这个实例上,设置归一化因数为其中N表示在x中的位置,而不是f的求和结果,因为他能简化梯度计算。
-
Concatenation(级联)
级联在视觉推理的关系网络中被用作二元函数,公式如下所示:
其中表示级联操作,表示将级联向量投影到标量的权重向量,同上设置归一化因数为,在这个例子中使用ReLU作为f函数
Non-local块
将上述公式中的non-local公式制作为Non-local块,使其能够嵌入到已有的结构中。本文定义Non-local块为:
其中是Non-local公式中的,""表示一个残差连接。残差连接的使用允许我们将新的non-local块插入到任何一个预训练模型中并且不会打破他的初始参数。一个non-local块的样例如下图所示:
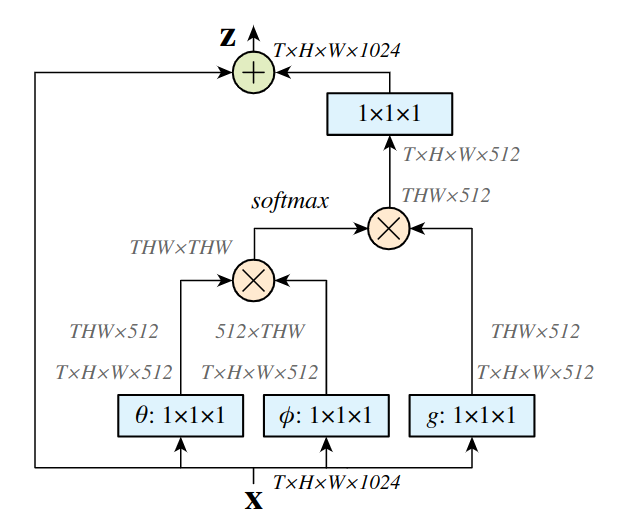
$\otimes \oplus $表示按元素求和,在每一行中都使用了softmax函数。蓝色的方块表示1x1x1的卷积。上图表示的是embedded Gaussian版本的non-local块。
实现:
设置的通道数为x通道数的一般,这种设计有利于减少块的计算,权重矩阵在上计算了二元embedding。二次采样技巧也h有助于减少计算。修改non-local的通用公式为:
其中是二采样版本的x,将这个公式使用在空间域上,可以减少大部分的二元计算,并且这个技巧不改变non-local的行为,但只会使得计算更加i稀疏,这个二次采样可以通过在之后使用最大池化实现。




