Hierarchical Multi-Scale Attention for Semantic Segmentation
Hierarchical Multi-Scale Attention for Semantic Segmentation
论文名称:Hierarchical Multi-Scale Attention for Semantic Segmentation
作者:Andrew Tao, Karan Sapra, Bryan Catanzaro
期刊:尚未查出(时间2020)
原文摘要
Multi-scale inference is commonly used to improve the results of semantic segmentation. Multiple images scales are passed through a network and then the results are combined with averaging or max pooling. In this work, we present an attention-based approach to combining multi-scale predictions. We show that predictions at certain scales are better at resolving particular failures modes, and that the network learns to favor those scales for such cases in order to generate better predictions. Our attention mechanism is hierarchical, which enables it to be roughly 4x more memory efficient to train than other recent approaches. In addition to enabling faster training, this allows us to train with larger crop sizes which leads to greater model accuracy. We demonstrate the result of our method on two datasets: Cityscapes and Mapillary Vistas. For Cityscapes, which has a large number of weakly labelled images, we also leverage auto-labelling to improve generalization. Using our approach we achieve a new state-of-the-art results in both Mapillary (61.1 IOU val) and Cityscapes (85.1 IOU test)
介绍
语义分割的预测结果通常容易受到推理图像尺度的影响,如下图所示
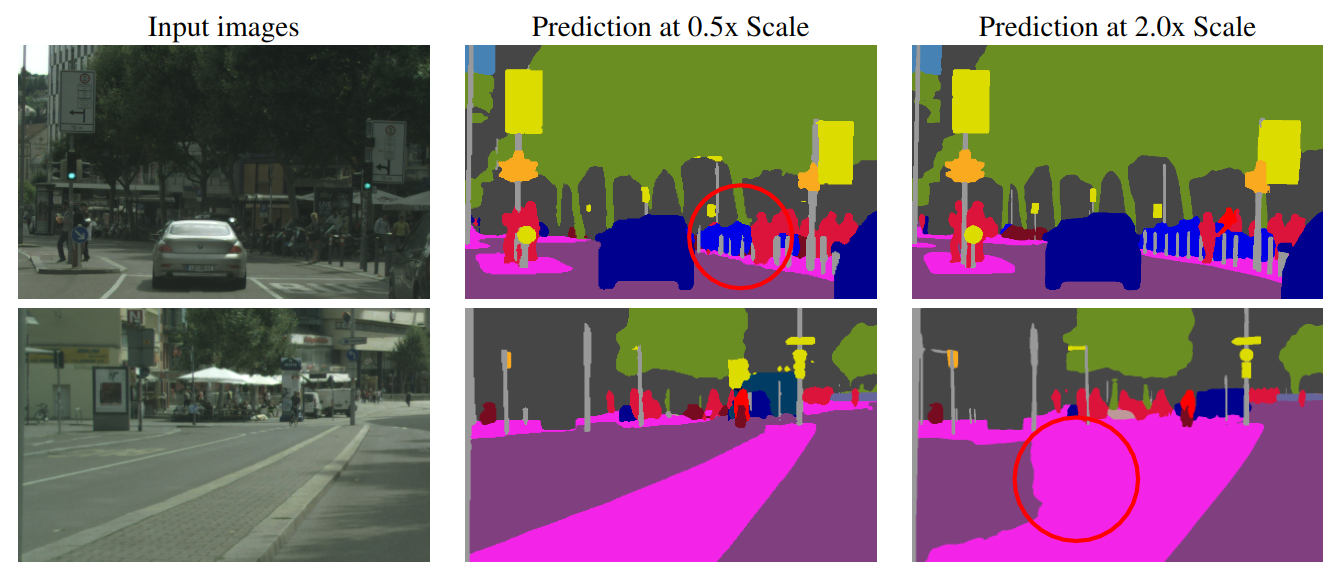
在第一行中我们可以看到在图片尺度为0.5x(缩放到一半)的尺度下,路障的柱子的粗细分割结果显然不一致,但是在2.0x(放大两倍)的尺度下,路障的分割结果显然更好一些。
在第二行中我们可以看到在图片尺度为0.5x尺度下,道路的分割结果明显较好,但是在2.0x的尺度下,道路的分割结果就会多出一部分的内容。
本文将这种问题称为类混淆(class confusion),使用多尺度推理(multi-scale inference),将结果使用平均池化或最大池化联合起来,使得预测结果在一定范围内是有效的。使用平均值组联合多尺度通常能够促进分割结果,但是其面临将最差的分割结果与最好的分割结果结合的问题。最好的分割结果通常是使用不同尺度结果的加权组合。为了增加数据集中的方差,从而提高泛化能力,本文采用了一种自动在粗糙图像上标记的策略。与软标签策略相反,本文采用的是硬标签,以便管理标签的存储大小,这有助于通过降低磁盘IO成本,从而提高训练吞吐量。
主要贡献:
- 一种有效的分层多尺度注意力机制,有茱萸解决类别混淆和细节问题
- 一种基于硬阈值的i自动标签策略,利用未标记的图像并提高IOU
分层多尺度注意力(Hierarchical multi-scale attention)
本文的注意力机制将从每一个维度学习密集的mask,这些多尺度的预测结果,h泽泻多尺度预测通过在mask之间进行像素a形成,然后在不同尺度之间进行像素求和来组合,以获取最终的结果。
在hierarchical方法中,不是为一个固定的尺度集合学习所有的注意力掩码(attention mask),而是学习向量尺度之间的相对注意力掩码。当训练网络是,只用相邻的尺度对进行训练。在训练中使用了图像缩放的数据增强方法,这允许网络学习预测一系列尺度图片的相对注意力,当进行推理时,可以层次分明地应用学习到的注意力,将N个尺度的预测结果结合在一起。在本文中,优先考虑低尺度的预测,然后逐步上升到高u尺度的预测,因为他们有更多的全局背景,可以选择那些预测需要由高尺度的预测来完善。
该注意力可以用如下公式来表示
其中r = 1表示对图像不做任何操作,r=0.5表示下采样到原图的0.5倍,r=2上采样到原图的2倍,u表示双线性上采样操作,和表示像素级别的乘法和加法,向网络主干中传递和两张图片,并由此产生每个尺度的语义逻辑(semantic logits)和注意力掩码,这两个用于生成最终的两个尺度之间的逻辑值(logits)
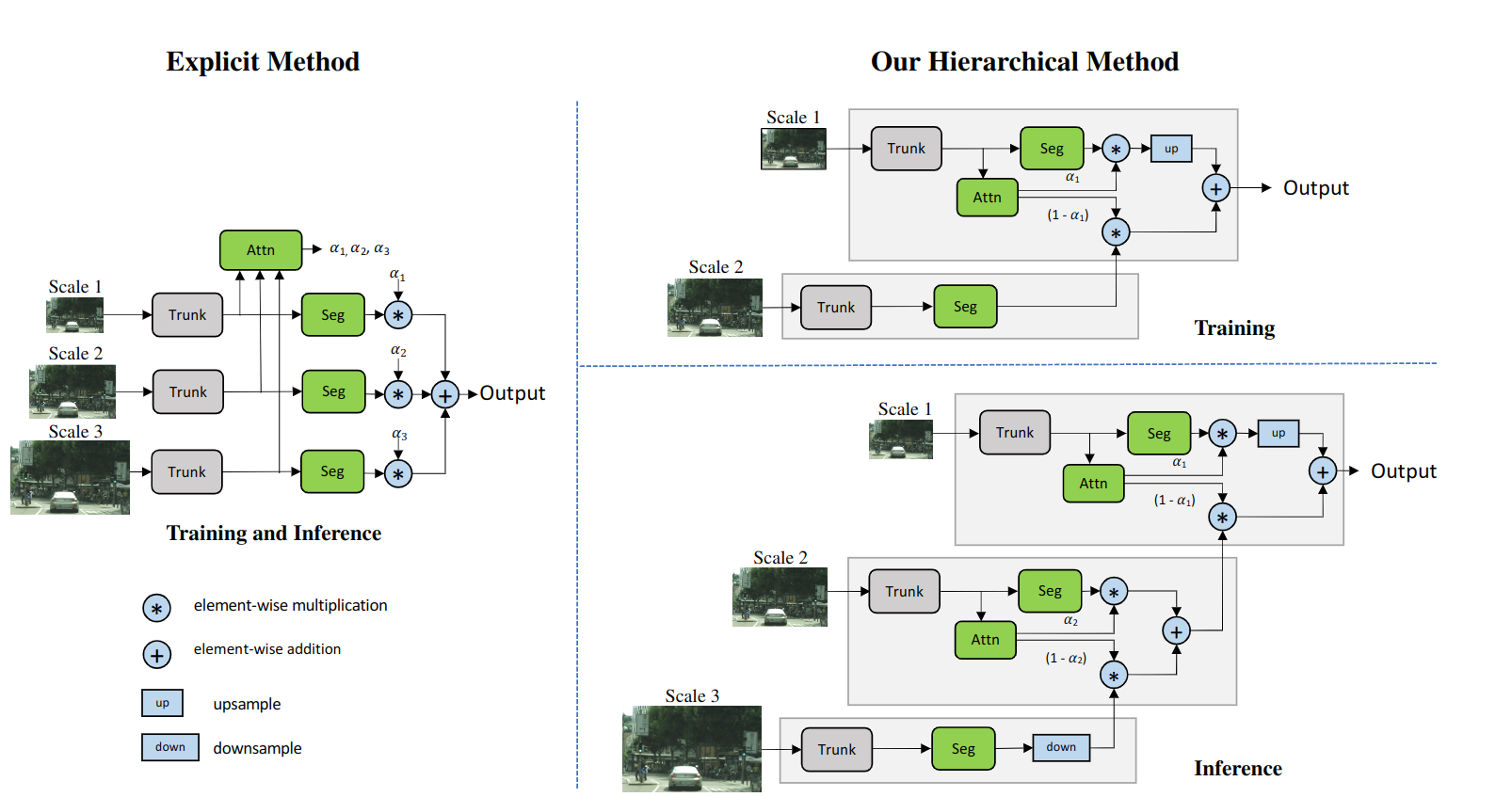
图中的Explicit方法出自论文Attention to scale: Scale-aware semanticimage segmentation,其主要过程就是明确学习每个尺度的注意力,在Hierarchical方法中右上角是训练方式,网络通过右上角的结构学习预测相邻尺度之间的注意力,右下角以连锁/分级(Chained/Hierarchical)的方式进行推理,以结合多个尺度的预测。低尺度的注意力决定了下一个高尺度的注意力的贡献。
使用分层注意力机制有两个优势:
- 在推理时,可以灵活地选择尺度,因此在用0.5x和1.0x训练的模型上增加新的尺度0.25x和2.0x,是可以通过之前提到的注意力机制链以分层的方式进行的,而在以前的方法中只限制与使用模型训练过哼中使用的相同比例。
- 与explicit方法相比,这种分层结构使我们能够提高训练效率,在explicit方法中,如果使用0.5,1.0,2.0的尺度,训练成本为,相对与但尺度训练,使用本文的分层方法,训练成本只有
结构(Architecture)
- 主干网络(Backbone):在进行消融实验的过程中,本文使用的是ResNet-50(配置为输出步长等于8)作为算法的网络主干。对于SOTA的结果,本文使用更大,更强的主干HRNet-OCR(出自2019年的论文Object-contextual representations for semantic segmentation)
- 语义头(Semantic Head):语义预测是由一个全卷积头进行的,其构成为:3x3Conv->BN->ReLU->3x3Conv->BN->ReLU->1x1Conv,最后一层卷积输出的通道数为数据集的类别数
- 注意力头(Attention Head):注意力预测是通过一个单独的头来完成的,该头在结构上与语义头相同,除了最后的卷积输出,他输出的是一个单通道的特征图。当使用ResNet-50作为主干时,语义头和注意力头的输入都是ResNet-50的最后阶段的特征图,当使用HRNet-OCR时,语义头和注意力头的输入是OCR块的特征图。在HRNetOCR中,还存在一个辅助语义头,他在OCR之前直接从HRNet主干中获取其特征。注意力头的结构可以表示为:1x1Conv->BN->ReLU->1x1Conv,在对语义逻辑生成注意力后,预测结果被双线性上采样至目标图像的尺寸。
Cityscapes上的自动标记(Auto Labelling on Cityscapes)
受到关于图像分类任务自动标记工作的启发,本文在Cityscapes上采用了自动标记策略,以提高有效数据集的规模和标记质量。在Cityscpaes中,用20000张粗略标记的图像,以及3500张精细标记的图像。粗略图像的标签质量非常一般,并且包含了大量的未标记元素。但是经过本文的自动标签方法,可以提高标签的质量,这反过来又有助于模型的IOU指标。如下图所示,左边表示原图,中间是粗糙的标记,右边是自动标记优化后的结果

在本文中,采用了硬标签策略(hard labelling strategy),即对于一个给定的像素,我们选择有teacher网络预测出的最高概率的类别。根据teacher网络的输出概率来确定标签的阈值。超过阈值的teacher网络预测结果将成为真正的标签,否则该像素被标记为ignore class,在实际使用过程中,本文使用的阈值为0.9
实现细节
训练细节
在Nvidia DGX服务器上使用pytorch进行训练,使用SGD作为优化其,在每个GPU上的BatchSize为1,momentum为0.9,权重衰减(weight decay)为。采用多项式(polynomial)学习率策略。使用RMI(出自论文Region mutual information loss for semantic segmentation)作为默认设置下的主要损失函数,并使用交叉熵作为辅助损失函数,对于Cityscapes,使用2.0的poly指数,初始学习率为0.01,在2DGX节点上训练了175个epoch。对于Mapillary数据集,使用1.0的poly指数,0.02的初始学习率,并在4个DGXn解嗲上训练了200个脉冲。在数据加载其中使用类的统一采用,从每个类中频均采样,这有助于在数据分布不均的情况下改善结果。
数据增强
在输入图像上采用高斯模糊(gaussian blur),颜色增强(color augmentation),随机水平翻转(random horizontal flip)和随机缩放(random scaling)(0.5x~2.0x)来增加训练过程中的数据集。对于cityscapes数据集,使用2048x1024的裁剪尺寸,对于Mapillary使用1856x1024的裁剪尺寸
cityscpaes结果

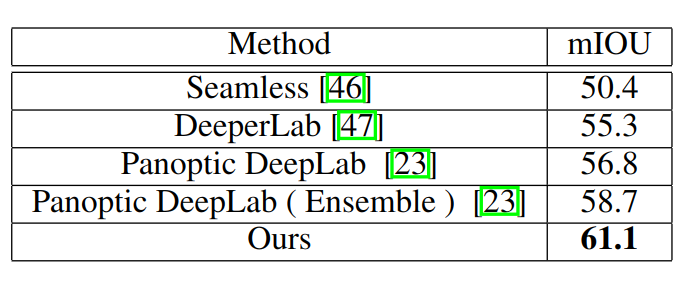
Mapillary Vistas结果