Object-Contextual Representations for Semantic Segmentation
Object-Contextual Representations for Semantic Segmentation
论文名称:Object-Contextual Representations for Semantic Segmentation
作者:Yuhui Yuan, Xilin Chen, Jingdong Wang
期刊:ECCV2020
原文摘要
In this paper, we study the context aggregation problem in semantic segmentation. Motivated by that the label of a pixel is the category of the object that the pixel belongs to, we present a simple yet effective approach, object-contextual representations, characterizing a pixel by exploiting the representation of the corresponding object class. First, we learn object regions under the supervision of the ground-truth segmentation. Second, we compute the object region representation by aggregating the representations of the pixels lying in the object region. Last, we compute the relation between each pixel and each object region, and augment the representation of each pixel with the object-contextual representation which is a weighted aggregation of all the object region representations. We empirically demonstrate our method achieves competitive performance on various bench-marks: Cityscapes, ADE20K, LIP, PASCAL-Context and COCO-Stuff. Our submission “HRNet + OCR + SegFix” achieves the 1st place on the Cityscapes leader board by the ECCV 2020 submission deadline. Code is available at: https://git.io/openseg and https://git.io/HRNet.OCR.
摘要
在本文中,主要研究语义分割中的语义聚合(context aggregation)问题。由于像素的标签是该像素所属对象的类别,本文提出了一种简单而有效的方法,即对象语义表征(object-contextual representations),通过利用相应对象类别的表征来描述一个像素。首先,在ground truth分割的监督下学习对象区域,其次,通过聚合位于对象区域内的像素的表征来计算对象区域表征。最后,计算每个像素与对象区域之间的关系,并用对象背景表征来增加每个像素的表征,该表征是所有对象区域表征的加权聚合。
介绍
本文算法的目的是通过利用相应类别的对象区域的表示来增加一个像素的表示。
本文的方法包括三个主要步骤
- 将语义像素划分为一组软对象区域,每个区域对应一个类别,即由深度网络(ResNet或HRNet)计算的粗略的软分割。这样的分割是在ground-truth分割的监督下学习的。
- 通过汇总相应对象区域内的像素的表征来估计每个对象区域的表征
- 用对象语义表征(OCR)来增加每个像素的表征,OCR是所有对象区域表征的加权汇总,其权重根据像素对区域之间的关系计算
在OCR方法中将同一对象类别的语义像素与不同的物体类别的语义像素区分开来,而传统的多尺度上下文方法,如ASPP和PPM则没有区分,只区分不同空间位置的像素。下图是一个区分ASPP和OCR方法的例子,SPP的上下文是一组用橙色和蓝色标记稀疏采样像素,不同颜色的像素对应着不同的扩展率(dilated rates)。这些像素分布在物体区域和背景区域。OCR的上下文被认为是位于对象中的一组像素(用蓝色标记)。

多尺度上下文
ASPP模块通过以不同的扩张率执行几个平行的扩张卷积来捕捉多尺度背景信息。其公式可以表示为:
表示扩张率(dialation rate)为d的空洞卷积第s次在像素位置的采样,t是卷积位置的索引,是像素的表征,是第d个空洞卷积在像素输出的表征,是在t位置上用于第d次空洞卷积的卷积核参数。输出的多尺度语境表征是平行空洞卷积输出的表征拼接。
基于空洞卷积的多尺度上下文方案可以捕捉到多个尺度的上下文而不使其损失分辨率。PSPNet中的特征金字塔模块对不同尺度的表征进行常规卷积,也能捕捉到多个尺度的上下文,但对于大尺度的上下文来说会使其失去较多的分辨率。
关系上下文
关系上下文是通过考虑每个像素之间的关系来计算每个像素的上下文的。其公式可以表示为:
其中表示图像上的像素集合,表示和之间的关系,并且只能从或者与中计算预测。和是两个不同的转化函数,就像自注意力(self-attention)那样。全局上下文方案是关系上下文的案例,其可以表示为
实现方法
目的:
- 将图像I中的所有像素结构化为K个软对象区域
- 通过聚合第K个对象区域中所有像素的表示来表示每个对象区域
- 通过聚合K个对象区域的表示并考虑其与所有对象区域的关系来增加每个像素的表示
其可以用下面的公式进行表示:
其中是第k个对象区域的表征,是表示第i个像素与第k个对象区域之间的关系,和是两个不同的转化函数
软对象区域(Soft obeject regions)
本文将图片I分成K个软对象区域。对于每个对象区域对于第k个类别,并使用一个2D的特征图(或者粗分割特征图)表示,其上每一个点表示该像素属于这个类别k的程度。
从骨干网络输出的中间表示中计算1出物体区域,在训练过程中,对象区域生成器是在ground truth的语义基础上,使用交叉熵损失函数进行监督学习的。
对象区域表征(Object region representations)
我们将所有像素的表征按其属于第k个物体区域的程度加权汇总,形成第k个物体区域的表征,其可以用公式表示:
在这里,是像素的表征,是对像素点属于k对象区域的概率,使用softmax去归一化对象区域
对象语义表征(Object contextual representations)
计算每个像素和每个对象区域的公式如下:
其中是非规范化函数(unnormalized relation function),是两个转化函数,实现方式是:1x1Conv->BN->ReLU.受到self-attention的启发,这样计算能更好地对关系进行估计。
对象语义表征在每个像素上的计算方式如之前的公式所示,其中是两个转化函数,其实现方式是:1x1Conv->BN->ReLU,其参照了non-local的结构。
扩张表征(Augmented representations)
像素的最终表征更新分成两部分,一是原始的表征,二是对象语义表征,其计算可以使用公式表示:
其中是一个转化函数,用来融合原始表征和对象语义表征,其实现方式是1x1Conv->BN->ReLU,
结构图
其结构如下图所示:
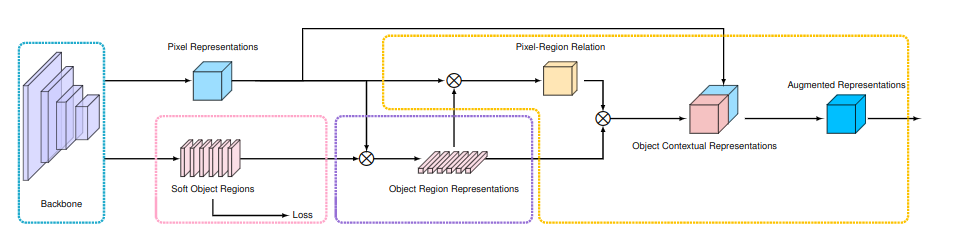
在backbone提取主要特征后,在粉色区域先生成软对象区域,接着结合原始表征(对应图中的Pixel Representations)在则色区域内生成物体区域表征,最后在橙色区域中计算对象语义表征和增强表征。
Backbone:使用空洞ResNet-101(输出步长为8)或HRNetW48(输出步长为4)作为骨干,对于空洞的ResNet-101。有两个表征,被输入到OCR模块中,第三阶段的第一关表征用于预测粗略的分割(对象区域)。来自第四阶段的另一个表征,经过3x3卷积(512个输出通道),然后被输入OCR模块中。对于HRNetW48,值使用最后的表征作为OCR模块的输入。
OCR module:如上图所示,图中表述的方法就是OCR模块的实现,使用一个线性函数(1x1卷积)来预测粗略的分割结果,用一个像素的交叉熵损失进行监督。所有的h转化函数都是使用1x1Conv->BN->ReLU的方式实现的,前三个输出256通道,后两个输出512的通道。使用一个线性函数从最终的表征中预测最终的分割。,我们还对最终的分割预测应用了一个像素交叉熵损失。







