Global Aggregation then Local Distribution in Fully Convolutional Networks
Global Aggregation then Local Distribution in Fully Convolutional Networks
论文:Global Aggregation then Local Distribution in Fully Convolutional Networks
作者:Xiangtai Li, Li Zhang, Ansheng You, Maoke Yang, Kuiyuan Yang, Yunhai Tong
期刊:BMVC 2019
原文摘要
It has been widely proven that modelling long-range dependencies in fully convolutionalnetworks (FCNs) via global aggregation modules is critical for complex scene under-standing tasks such as semantic segmentation and object detection. However, globalaggregation is often dominated by features of large patterns and tends to oversmoothregions that contain small patterns (e.g., boundaries and small objects). To resolve thisproblem, we propose to first useGlobal Aggregationand thenLocal Distribution, whichis called GALD, where long-range dependencies are more confidently used inside largepattern regions and vice versa. The size of each pattern at each position is estimated inthe network as a per-channel mask map. GALD is end-to-end trainable and can be easilyplugged into existing FCNs with various global aggregation modules for a wide range ofvision tasks, and consistently improves the performance of state-of-the-art object detec-tion and instance segmentation approaches. In particular, GALD used in semantic seg-mentation achieves new state-of-the-art performance on Cityscapes test set with mIoU83.3%.
介绍
全局聚合通称会被大图形所主导,并倾向于过渡平滑包含小型图案的区域(例如,边界和小物体)。为解决这问题,本文首先使用全局聚合,然后使用局部分布(Global Aggregation and then Local Distribution),因此被称为GALD,其中长距离的依赖关系在大模式区域内更有信息,反之亦然。GALD是端到端可训练的,可以很容易地插入到现有的具有各种全局聚合模块的FCN中,用于广泛的视觉任务,并不断提高核心物体检测和实例分割方法的性能。如下图所示,在GA(全局聚合)处理后的图像,在大物体的边缘处会比较粗糙,在GA之后加入LD(局部分布)模块,就能细化物体分割的边缘。适应过程由一组掩码图(mask map)控制,其中每个掩码图都是由记录了整个图像上某些潜在模式的激活的特征图估计出来的。

Global Aggregation(全局聚合 GA)
为了计算每个位置的特征向量,GA模块会根据不同的GA设计,在一个大的窗口甚至整个特征图中提取F的特征向量。具体来说,对么一组的全局统计数据进行计算,并乘以同一组特征,形成。在我们的实现中,我们将F的取样率降低2倍,以节省内存和h计算成本,而i没有观察到性能下降,这也证明了全局聚合的粗略特性。
由于GA模块在大窗口计算中计算特征的全局统计数据,他们很容易偏向于大图案的特征,因为他们包含更多的样本。然后,分布在每个位置的全局信息也偏向于大的模式,这就造成了对小模式的过度平滑结果。
Local Distribution(局部分配 LD)
LD被提出去自适应地使用,考虑每个位置上的模式(patterns)。在没有明确监督的情况下,需要的模式是由中的C通道潜移默化地描述的。对于每个模式(pattern),在一张基于激活图的切片的图片上,重新计算模通过式(pattern)的空间范围学习一种空间操作。直观地说,大图的空间运算会缩小空间范围,而对小图案的空间运算符则缩得更少,甚至扩大。
每个图案/通道的空间运算被建模成i一组以为输入的depth-wise卷积,如下公式所示
其中包含每个模式的掩码图,并描述每个模式的重新计算的空间范围。是sigmoid激活函数,是那些深度滤波器卷积(depth-wised convolutional filters)的权重,d表示下采样率。输出的掩码M对空间和通道都很敏感,h他四用i双线性插值法进行上采样的。有了掩码图M,被细化为$F_{GALD}$1通过下面的公式
其中表示像素之间的乘法,而中的元素则根据每个位置上每个图案的估计空间范围进行加权。LD为GA特征图上的每个位置预测了局部权重M,避免了特征表示粗糙的问题。
原始特征F和全局聚合特征被压缩在一起,用于最终特定任务头。
M在全局信息和局部细节信息之间进行逐点权衡。u需要注意的是,由于GA中缺乏细节,LD模块只改变了GA中粗略特征的比例分布,导致了细粒度的特征表示输出
总体结构
GALD网络的结构如下图所示。对于语义分割,GLDA被添加到FCN之后,上面计算公式输出的特征被用于最终的预测。为了进一步提高性能,OHEM(Online Hard Example Mining)损失函数中被用于训练,在反向传播过程中,只使用根据损失排名前K的像素。
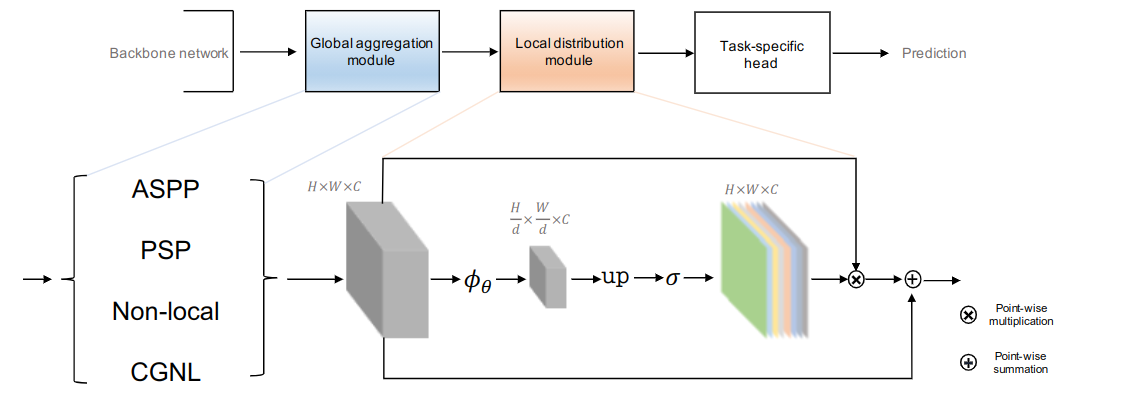
实施细节
使用FCNs作为baseline,ImageNet上预训练的ResNet被选为骨干网络,其设置与PSPNet相同,提出的GALD被附加到骨干上,并进行随机初始化,在优化方面,使用momentum=0.9,初始learning rate=0.01进行训练5万个iterations,使用mini-batch size=8,裁剪大小为769。在训练过程中使用poly学习率调整策略,其中power=0.9被用来调整学习率。







