You Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for ObjectDetectors
You Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for ObjectDetectors
论文:[You Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for ObjectDetectors](You Cannot Easily Catch Me: A Low-Detectable Adversarial Patch for ObjectDetectors)
作者:Zijian Zhu, Hang Su, Chang Liu, Wenzhao Xiang, Shibao Zheng
期刊:2021年某期刊
代码:暂时没有
原文摘要
Blind spots or outright deceit can bedevil and deceive ma-chine learning models. Unidentified objects such as digital“stickers,” also known as adversarial patches, can fool facial recognition systems, surveillance systems and self-driving cars. Fortunately, most existing adversarial patches can be outwitted, disabled and rejected by a simple classification network called an adversarial patch detector, which distinguishes adversarial patches from original images. An object detector classifies and predicts the types of objects within an image, such as by distinguishing a motorcyclist from the motorcycle, while also localizing each object’s placement within the image by “drawing” so-called bounding boxes around each object, once again separating the motorcyclist from the motorcycle. To train detectors even better, however,we need to keep subjecting them to confusing or deceitful adversarial patches as we probe for the models’ blind spots. For such probes, we came up with a novel approach,a Low-Detectable Adversarial Patch, which attacks an object detector with small and texture-consistent adversarial patches, making these adversaries less likely to be recognized. Concretely, we use several geometric primitives to model the shapes and positions of the patches. To enhance our attack performance, we also assign different weights to the bounding boxes in terms of loss function. Our experiments on the common detection dataset COCO as well as the driving-video dataset D2-City show that LDAP is aneffective attack method, and can resist the adversarial patch detector
摘要
Blind spots(盲点)和outright deceit(彻头彻尾的欺骗)会使机器学习模型受到困扰(bedevil)和欺骗(deceive)。简单的攻击性补丁会被攻击补丁检测器(一种简易的分类网络)检测到,并将图像和补丁区分开来。
本文提出的低可探测性对抗补丁(Low-Detectable Adversarial Patch 简称LDAP),用小和纹理一致性(texture-consistent)的攻击补丁来攻击物体检测器,使得这些对抗不太可能被识别。具体来说就是使用了几个几何图元(geometric primitives)来模拟补丁的形状和位置。为了提高攻击性能,本文还在损失函数方面对边界框分配了不同的权重。
介绍
大多数的现有补丁式对抗实例可以很容易地从良性图像(benign image)中区分出来,这使得训练一个分类网络(对抗性补丁检测器 adversarial patch detector)来自动检测和拒绝这些对抗性补丁变得容易。这种简单的防御方法,也被称为仅检测的防御方法(detect-only defense approach)。
本文称向右补丁式对抗性攻击的这一确定称为高可检测性(high detectability)。
为使得对抗性补丁检测器更难识别对抗例子,本文把重点放在攻击方法的两个方面
1. 减少图像中对抗性补丁的面积
2. 增减与原始图像的纹理一致性
这两个方面都可以减少对抗性例子和原始图像之间的差异,使对抗性例子更不可能被对抗性补丁检测器识别。
减少对抗性补丁的面积困难的原因
对补丁形状进行参数化建模(Model the Patch Shapes Parametrically)
参数化建模是不容易的,因为他们的形状可以很灵活。一个简单的方法是将输入图像中的所有补丁建模为一个覆盖图像的二进制掩码,并针对其中的每个像素穷尽patch的任何可能的形状。然而,这种建模方法使问题难以解决,因为他是一个高维度的精确搜索问题。
对象检测器的内部机制(The Inner Mechanism of an Object Detector)
假设能够对补丁进行建模,攻击一个物体检测器还是很困难的,尤其是对灵活的补丁。这个困难主要来自于物体检测器的边界预测机制。一般来说,一个物体检测器的通道是:首先,他预测一个物体上的多个边界框,然后在检测器对他们进行分类,最后使用非最大抑制(NMS)从其中选择一个边界框。攻击应该同时影响所有这些边界框,这使得对物体检测器的攻击变得困难。为了解决这个问题,以前使用固定补丁的攻击采用了两种策略。
- 用目标类别的最大置信度来攻击边界,然而,在优化过程中,具有最大置信度的边界框(即模型的输出应该代表分类的置信度)可以不断改变,使得本文的区域搜索不稳定。
- 第二种策略是对可检测到的目标的边界框即对抗性攻击的目标物体进行平等攻击(equally attack)。然而这些边界框大多是不准确的,将区域误导到次优位置。因此这些策略都不适合本文的区域弹性攻击(region-flexble attack)
本文的提议
本文题提出的LDAP的生成被表述为一个联合优化问题,它破坏了物体检测器的预测,减少了补丁的面积并同时保留与原始图像的纹理一致性。下面是实现目标的两个方案
使用几何图元来建模(The Use of Geometric Primitives to Model thePatches)
以前的一些研究用一组几何图元(geometric primitives,这里用的是椭圆形)表示一个给定的二维形状。他们利用高斯混合模型(GMM)来对这些椭圆进行参数优化,并利用期望最大化(EM)算法来最大化与给定形状的相似度。本文使用一组几何图元(矩形)来模拟具有灵活形状和位置的补丁。具体来说,首先,基于一个发现,图像平面上不规则形状的补丁可以被几个矩形所近似,本文假设对抗性补丁可以被一组矩形所近似,因此,本文将补丁区域建模为几个矩形的联合体。这些补丁与其他区域的划分可以通过二进制图像掩码来实现,其中补丁区域被设置为1,其他区域被设置为0。
然而,这些矩形的边界是陡峭的(steep),使得损失函数相对于他们的形状和位置参数不可微分。为了解决这个问题,本文放松了这些矩形的陡峭边界,使其从1到0的过渡变得平滑。这些边界放松的矩形在任何地方是连续的,使本文能够使用基于梯度的方法来优化其参数。松弛使矩形看起来像羽毛球,如下图所示。
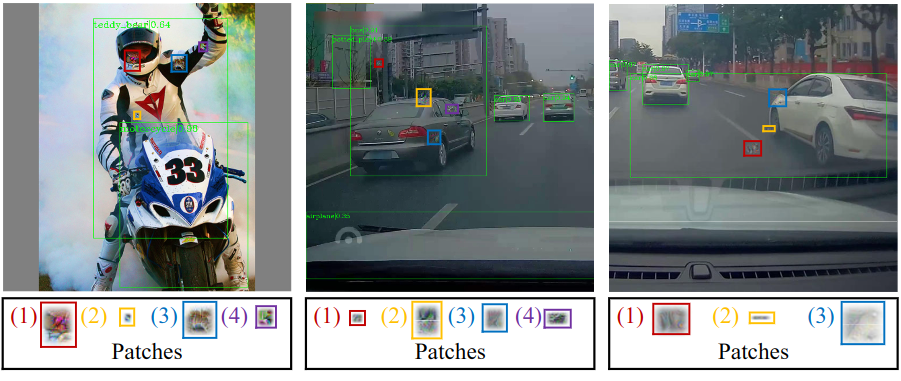
补充GMM对椭圆进行建模,使用硬性的EM和Akaike信息准则来优化GMM的参数以近似给定的形状。
软攻击策略(Soft-Attack Strategy)
为了克服来自物体检测器内部机制的困难,本文在损失函数中采用了软攻击策略,也就是说,本文对可以被检测为目标物体的多个边界框分配不同的权重。这种策略是基于这样的假设:攻击应该更加关注离目标物体更近的边界框。这种假设是合理的,因为较近的边界框更有可能是正确的预测。权重被设定为预测的边界框和目标物体的边界框值之间的交并比(IoU)。损失函数中的软攻击策略使本文能够更专注于更接近目标对象的边界框,这种专注有利于本文在搜索补丁位置使的攻击。(在COCO上,对Faster R-CNN,Mask R-CNN,SSD,YOLOv3做实验)
工作总结
- 提出了一种低检测的补丁式攻击方法。基于一个合理的假设,我们将低检测攻击制定为一个联合优化问题,同时考虑到攻击性能,补丁面积和补丁的纹理一致性
- 以可微调的方式对补丁的形状和位置进行建模,这使我们能够使用基于梯度的方法来优化补丁的形状和位置,以及他们的纹理。
- 为了克服来自物体内部机制的困难,在损失函数中采用了软攻击策略,对可以检测为目标物体的边界框分配不同的权重。
方法
问题提出
LDAP的目标是用小的,纹理一致的补丁来欺骗物体检测器。我们设定这个目标是基于一个假设,即这两方面都可以帮助我们躲避对抗性补丁检测器。这个假设是合理的,因为小补丁可以减少图像中被操纵部分的面积,而这些补丁中一致的纹理可以减少操纵的幅度。这两方面都能帮助我们减少对抗性例子和良性图像之间的差异,使对抗性补丁检测器不太可能将他们区分开来。
为了实现这一目标,给定一个输入图像,其中分别是输入图像的宽度和高度,我们将LDAP的问题表述为求解最佳扰动(optimal perturbation)。
其中是参数权重,是包含所有对抗性补丁的对抗性扰动。是攻击损失函数用于确保不同攻击任务中攻击性能。是面积损失,用于约束补丁的面积。是约束补丁纹理的纹理损失。通过解决这个联合问题,可以得到一个适当的,它可以欺骗补丁具检测器,同时补丁小且纹理一致。
纹理和遮罩层(texture and mask layers)
为了清楚地定义补丁的形状,位置和纹理,本文把分解成一个纹理层和一个掩码层的元素积。纹理层对补丁的纹理进行编码,而掩码层对补丁的形状和位置进行编码,用这个二元掩码层M来划分补丁和其他区域。那么扰动(perturbation 所有补丁的聚合)可以被投射为:
其中表示元素积。这种因式分解的一个好处是,它把形状和位置项以及补丁的纹理分解出来,使得直接在M上定义非常容易。
元素积计算
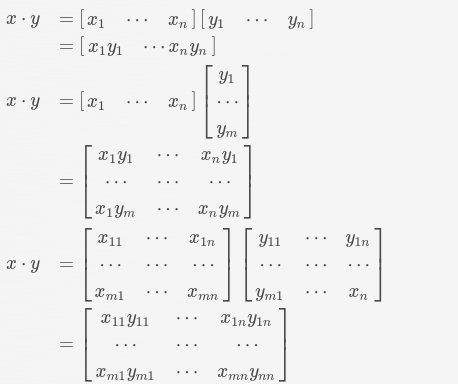
基于掩码层M和纹理层t的定义,整个LDAP问题被重新表述为:
在这个公式中,面积损失和纹理损失只与M和t有关,这使得本文更容易单独优化补丁的形状和位置以及补丁的纹理。这种分离有助于我们克服优化过程中两部分的耦合问题。(耦合意味着形状和位置的值会影响纹理的最佳值,反之亦然,如果我们同时更新两边的值,优化就会不稳定。)
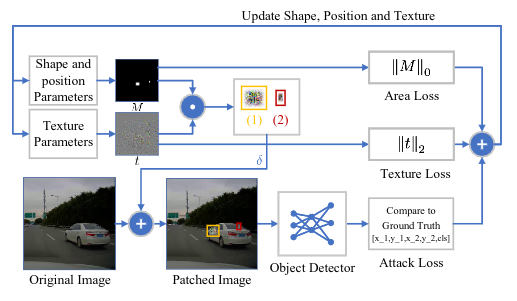
给定一个输入图像,首先从形状,位置和纹理参数中生成补丁,然后将他们添加到输入图像上。然后将修补后的图像传入物体检测器,计算攻击损失。面积损失和纹理损失是直接诶从M和t计算出来的。然后,我们将损失函数相加,并反向传播以更新性状,位置和纹理参数。
软攻击策略(Soft-attack strategy)
以前的攻击方法在处理目标对象上预测冗余边界框时,采用两种常见的策略。
- 只攻击目标类别中具有最大置信度的边界框。然而在攻击优化过程中,具有最大置信度分数的边界框可能会在优化过程中从一个边界框不断地改变到另一个。这不仅会减慢优化速度,而且会导致补丁的劣质位置和更差的攻击性能,导致更大的补丁,更低的纹理一致性和更高的可探测性。
- 平等地攻击可以被检测为目标对象的边界框,这意味着这些边界框的预测类别分数以及它们与目标对象之间的IoU都高于检测模型的阈值。这种解决方案可以缓解第一种策略的缺点,因为这些边界框通常具有最大置信度分数的边界框变化更少。然而,这些预测出来的边界框中,大多数并不准确。
因为,我们在攻击损失函数中使用软攻击策略,而不是这些攻击策略。软攻击策略意味着我们对可检测目标对象的边界框分配不同的权重。在这里,我们有一个假设,即离目标对象更近的边界框更值得攻击,因为他们更可能是正确的预测。基于这一假设,本文将预测的边界框和目标物体边界框之间的IoU设定为攻击损失函数中每个边界框的权重。软攻击策略将我们的LDAP集中在目标物体上,并帮助我们减少欺骗检测器所需的补丁面积。
不同的攻击损失函数(Different attack-loss functions)
与分类不同,目标检测包括两个部分,物体分类和定位。这使得对目标检测的攻击更加复杂。相应地,我们设置了一个分类攻击任务和一个定位攻击任务,只关注一个功能。对于不同的任务,我们设置了不同的攻击损失函数。
对于分类攻击,本文将分类分数的加权和作为损失函数,被定义为:
其中是可被检测为目标对象的边界框。是中的第i个边界框。是目标物体的边界框。是的权重,由我们的软攻击策略分配。是目标分类得分,由目标检测器对修补后的图像进行预测。
定位攻击(localization attack)是指攻击图像应该使检测模型预测出目标物体上的形状或位置不可取的边界框。在本文中,研究了对边界框位置的攻击,目地是使边界框水平移动。在定位攻击中,本文将边界框的回归偏移量的权重和作为攻击损失,该损失被定义为:
其中是可被检测为目标对象的边界框。是中的第i个边界框。是目标物体的边界框。是的权重。是在x维度的回归偏移量
综上所述,攻击损失被定义为:
区域损失(Area Loss)
面积损失被定义为:
然而,直接求解M是一个不简单的高维离散搜索问题,因为M由的二进制元素组成(W和H分别是原始图像的宽度和高度)。为了规避这个非线性问题,本文用一组集合图元来表示掩码层。
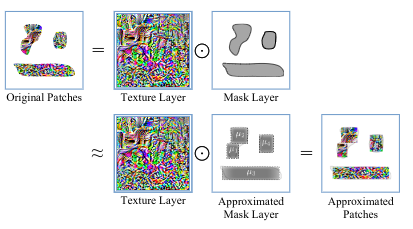
不规则形状和位置的补丁,可以由几个矩形近似地表示
本文做了一个合理的假设,即在攻击上的掩码层可以通过一组集合图元进行近似,因此,本文将掩码层表示为:
其中是第j个集合图元,N是几何图元的数量。每个图元可以被看作是一个退化的掩码层,它只用于一个简单的形状编码掩码层的一部分,这样,我们将M的优化转化为图元参数的优化,极大地减少了需要优化的参数量。
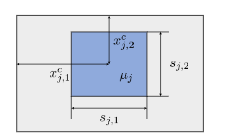
在不丧失一般性的情况下,我们首先选择矩形作为几何图元。因为感知场(receptive fields)和检测模型的预测边界框都是矩形。矩形图元被写成:
其中表示图像中像素的坐标,表示第j个矩形的位置参数(中心坐标点),表示形状参数(宽度和高度)。一个矩形图元及其参数的演示如下图所示(蓝色用1填充,灰色用0填充)。
解决非差分问题( Solving Non-differential Problem)
公式9中定义了矩形图元在矩形的边界上引起了从1到0的陡峭变化,导致损失函数相对与图元和的位置和形状参数来说是不可区分的。为解决这个非可区分问题,使用余弦函数对矩形图元的边界进行了松弛化(relax)。边缘松弛的图元可以表示为:
本文发现,余弦边界图元获得了一个平滑的边界,在所有的点上都是连续的,使得损失函数对于其位置和形状参数是可微分的。
边界松弛化之后,图元的取值范围从离散变为连续,因此,把公式8中的图元的联合重写为图元的权重和,如下所示:
其中是我们第j个图元的权重,。这种重写假设意味着图元在掩码层中不会相互重叠,因为重叠是对图元面积的浪费,重叠的图元可以用不重叠的图元来等价替换。
根据公式11,本文可以将公式7中的难以优化的范式内化为每个图元面积之和,面积损失被冲定义为
其中是第j个矩形图元的宽度和高度。
纹理损失(Textrue Loss)
纹理损失的目的是保持补丁的纹理与圆石图像的纹理的一致性。因此,本文直接使用对抗性纹理的范式作为纹理损失,可表示为:
最后将公式6,10,11,12,13带入公式3,计算出对抗性扰动,即所有补丁的汇总。
优化(optimization)
正如之前提到的,的优化和公式3中定义的问题是耦合的,这可能会破坏我们的优化,导致次优(sub-optimal)攻击性能。这里的。因此,我们把问题分成两个独立的方面,即掩码层搜索和纹理层搜索,并交替地一步一步地优化M或t,以简介地解决问题。
掩码层搜索(Mask Layer Search)
在这个搜索步骤中,我们固定纹理t,并优化由控制的任务层M。由于掩码层和纹理层的分离,我们可以在这一步直接省略纹理损失。其可以表示为:
在优化过程中耦合,因此我们可以将的更新分开。把公式14,中定义的目标函数称为J。首先,固定并计算J相对于的梯度,以更新他们:
其中分别是的学习率,然后固定并更新
其中是的学习率。在这两次更新之后,我们完成一个区域搜索步骤,在这个步骤中,我们根据固定的纹理层更新任务层M
纹理层搜索(Texture Layer Search)
在区域搜索的下一步骤之后,我们固定掩码M和更新纹理t的一个步骤。忽略公式3中不相关的内容,本文把纹理层的搜索问题写为:
我们还计算梯度来更新纹理的一步,例如
其中是t的学习率,是公式17的目标函数。在这一步中,我们根据固定掩码层来更新纹理层。
增加
对于不同的图像,面积损失和纹理损失的权重不应该总是相同,因为不同图像中的物体通常大小不一(较小的物体通常需要较小的补丁来攻击,所以面积损失的权重应该更大)为了克服这个问题,我们将的值设定为在纹理搜索步骤之后逐渐增加。这种设置可以确保对于不同的图像,LDAP可以找到最够小,纹理一致的补丁。
其中的增加率,在这一步之后,我们转到下一步的区域搜索。我们的方法的总体程序如下算法所示:
输入:图像I,矩形图元的数量N,目标物体的边界,学习率,和他们的增加率,最大搜索步骤
输出:对抗性扰动
- 初始化纹理层t,基本权重,图元的位置和形状参数
- step= 0
- while step < do
- 根据公式15,搜索掩码层,更新和s
- 根据公式16,搜索掩码层,更新
- 根据公式18,搜索纹理层,更新t
- 根据公式19,增加
- step =step+1
- end while
- 计算扰动
实验
参数设置
的初值为1e-2,增量为1e-4,最大搜索步长为2000。矩形图元的数量N为10




