计算机视觉产业落地的难点与应对
计算机视觉产业落地的难点与应对
出自:百度大脑——(计算机视觉产业落地难点与应对)https://www.bilibili.com/video/BV1eB4y1T772?spm_id_from=333.999.0.0
学术研究和产业应用的区别
| 学术研究 | 产业应用 | |
|---|---|---|
| 任务 | 1. 定义明确 2. 聚焦某一任务 3. 单一明确的评估标准 |
1. 开放问题 2. 系统整体设计 3. 多维度,复杂评估 |
| 数据 | 1. 公开数据集 2. 固定不变 3. 数据量大 |
1. 自定义数据集(也可以采用公开) 2. 不断迭代 3. 数据量小 |
| 算力 | 无硬性限制(不受到设备限制) | 1. 限制硬件端部署 2. 服务器部署吞吐量要求 3. 实时性要求 |
产业落地难点
数据的规模和平衡性
-
数据的规模:
业务数据集通常会远小于公开数据集,通常只有几百到几千张。传统的mnist,CIFAR,VOC,COCO都比业务数据集多得多,甚至ImageNet22K,YFCC100m,JFT-300M这些数据设置达到了亿级。
-
数据平衡性:
理想状态:每个类别的图片数量一致
现实状态:每个类别的图片数量基本不一致,有的设置相差很大
解决数据问题的思路
- 迁移学习与预训练:使得模型能够提前见到过更多的图片,加速模型的收敛。
- 数据增广,数据合成(OCR,GAN):使得原本数据范围得到扩张,可以看到更多的图片。
- 少样本学习和但样本学习(one-shot/few-shot learning)
- 无监督和半监督学习:使得没有标签的数据也能够被使用
- oversampling(过采样)/undersampling(降采样):使得数据集每个类别的数量尽可能均衡
- focal loss:对难易样本和不同数量类别样本的权重更加均衡一些
泛化及鲁棒性
常见的深度学习迷惑行为:
paper里结果很好,实际常见不work
换了一家CT机的影像就诊断不出来了
阴天就检测不出目标了

学术界指标高,并不一定在业务场景表现就好,也许只是overfit了公开数据集
解决思路泛化性问题的思路
- 正则化(regularization): 确保模型在比较残缺的情况下也能学到鲁棒的特征
- weight decay(权重衰减)
- early stopping(早退)
- dropout/dropblok(神经失活)
- 数据增广
- domain adaptation(域自适应)
长尾及需求变化
- 零售,人脸等场景
- 类别多
- 新品产生(对应度量学习)
- 模型层面解藕
- detector->classifier
- embedding->indexer
- 度量学习(metric learning):提取图像的特征装进数据库中,使用图片提取的特征进入数据库中进行比对
- 持续学习(continual learning)
- 终身学习(life-long learning)
常见计算机视觉任务
图像分类
定义:输入一张图片,输出图片的类别
用途:通常作为其他任务的特征提取器(backbone)或者级联模型使用
定型选型思路:
- 服务器端:ResNet及其变体系列,EfficientNet系列
- 移动/嵌入式:MobileNet系列,ShuffleNet系列
- 大感受野(关键点,分割):HRNet系列,HourGlass
作为backbone时调参的注意事项:
- batchnorm(检测与量化)
- 蒸馏weight decay
图像识别
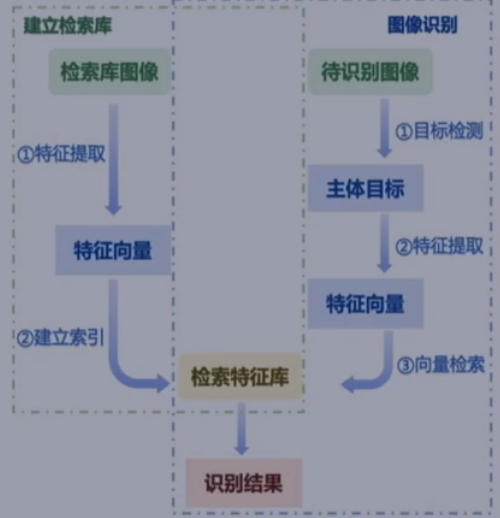
定义:输入一张图片,完成主体检测+识别过程
主体检测:快速找出图像中的一个活多个主体
度量学习:获取主体部分的图像特征
检索系统:集成Möbius 算法,高效完成向量检索
常规结构:
目标检测
定义:输入一张图片,输出图片中物体的位置及类别
| Anchor base | Anchor free | |
|---|---|---|
| One-stage | Yolo,SSD | FCOS,CornerNet |
| Tow-stage | RCNN | CPNDet |
原来anchor free和stage是两个概念
定性选型思路:
- 两阶段:准确率,小目标
- 单阶段:速度表现
- Anchor free:速度,召回率
分割任务
定义:输入一张图片,输出每个像素的类别
定性选型思路:
-
医疗影像相关:先尝试U-Net系列
-
实时性要求/移动端:Fast-SCNN系列
不知道为什么实时性这里没有使用BiseNet和STDC-Seg这种在paper上表现较好的模型。可能和之前说的,paper好不一定现实好,也有可能是因为工业界资料比较老旧了(视频是21年7月的)。也可能工业界比较求稳,上面的建议比较经得起时间考验,不过是比赛的话还是可以先试试BiseNet和STDC-Seg。
-
其他需求:先试试DeepLab V3+
我是否需要实例分割?Mask-RCNN/Solo
我是否需要全景分割?think again ! (请重新考虑)
产业落地项目流程拆解
部署环境—>任务映射—>数据采集—>建模迭代
部署环境要明确好自己的部署方式
数据采集和建模迭代的过程是整个落地过程最漫长的部分,这两个过程可以是相互弥补的,比如我一开始只有1000多张图片,然后训练的一个模型,后面突然多了几张图片,然后可以通过这个模型训练出来的标签进行微调,这样节省了标注成本。
部署环境
狭义部署环境:
云端:
1. 易于部署迭代
2. 可使用大模型,快速原型上限
3. 高延迟
4. 成本线性升高
边缘端:
1. 算力限制
2. 前期开发部署成本高
3. 低延迟
4. 成本可控
广义部署环境:
其他系统模块:
- 传感器(近视野,红外)
- 配套硬件(震动台,visual marker等)
流程自动化程度:
- 全自动 vs human-in-the-loop
- 场景容错范围:质检,医疗,零售
- 信任机制的建立
问题拆解与任务映射
出入车辆身份认证:车辆识别—>车牌识别检测+OCR
优先选择低复杂度模型
单模型和多模型组合/级联的问题:
-
多任务训练是否干扰,后续受前置任务精度制约
-
时延与运算量(如何衡量多任务带来的计算量增加)
-
数据变化速度与维护成本(如果有新的数据进来,怎么把数据划分成连个任务的数据集)
数据采集
少量精细标记数据的作用远大于大量粗标记/无标记的数据
不同标注方式信息含量不同:分割>检测>分类
可以尝试半自动/协同标注:标注100个样本迭代一个模型,尽量人工审核
成本允许的情况下,数据多多益善
有多少人工,就有多少智能。——业界名言
图片标注原则:
- 清晰明确的标注标准
- 不同标注人员标注结果需统一
- 标注尽可能细致
- 场景覆盖尽可能全面,持续迭代
模型迭代
快速起步,从0到1
一站式工具
成熟使用模型
根据需求调整结构/超参:
- 训飞(loss突然非常大,震荡):学习率,warm up
- 加速:小backbone,砍channel,使用depthwise conv,插值替换deconv等
- 小目标:大感受野backbone,使用早期特征,使用dilated conv,调整anchor
数据迭代:
- 结合bad case分析不断微调
- 一般来说加数据始终是有效的
- 可以多尝试增广,采样等方法
1 | Dear Editor, |




