大数据技术原理与应用
Big Data(大数据应用技术)
第一章:大数据概述(看好例题即可)
1. 大数据的概念
例:简述大数据的4V特征?并分别简要解释每个特征的意义?
答案:
- 数据量大(Volume)——各行各业每时每刻都在生产数据,生产速度非常块,产生的数量非常大。
- 数据类型繁多(Variety)——每个领域都会产生不同的数据类型,因此数据类型非常多。
- 处理速度快(Velocity)——数据生成速度很快,因此对这些数据的处理也要非常快。
- 价值密度低(Value)——我们的视频监控可能要录制很长时间,并且存储量特别大,但是有价值的部分可能只有几分钟。
2. 大数据的应用实例
智能推荐系统,信贷评估系统,无人驾驶汽车,优化物流网络,智慧交通,智能安防
3. 大数据的关键技术
从数据分析全流程角度,大数据技术包含哪些内容?每个内容请至少列出至少2个该内容包含的功能?
- 数据采集与预测——清洗,转化,集成
- 数据存储和管理——利用分布式文件系统,数据仓库等,实现海量数据的存储和管理
- 数据处理与分析——分布式并行编程,机器学习和数据挖掘
- 数据安全和隐私保护——保护数据安全和个人隐私
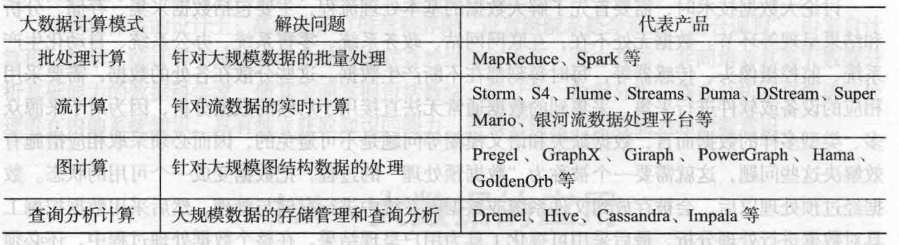
4. 大数据的计算模式
例:大数据有哪些计算模式?每个计算模式下请列举至少2个代表产品?
5. 大数据与云计算,物联网的关系
例:请简要说明大数据与云计算、物联网的联系与区别?
区别:
- 大数据侧重海量数据的存储,处理与分析
- 云计算整合优化各种IT资源,通过网络的方式廉价地提供给用户
- 物联网的目的是实现"物物互联"
联系:
- 云计算为大数据提供分布式存储和管理系统,大数据通过分布式并行处理框架MapReduce为云计算提供数据分析能力。
- 物联网传感器产生的数据是大数据的来源之一,云计算和大数据为物理网实现了数据的存储,分析和处理
2.大数据处理架构Hadoop
1. HDFS的生态环境
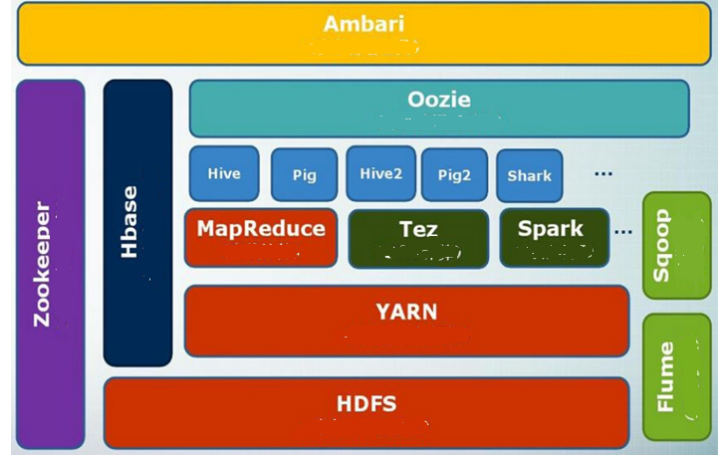
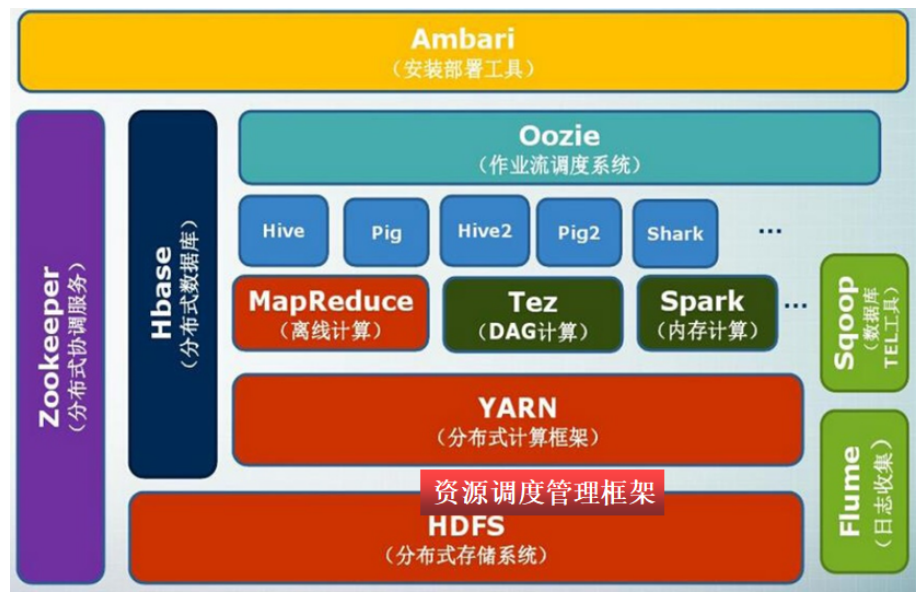
2. HDFS的安装与使用
在Linux下若以伪分布式的方式安装Hadoop,若Hadoop启动成功,则输入JPS后应至少包含哪些java进程?
答案:
- NameNode
- DataNode
- SeondaryNameNode
超重点:单击安装和伪分布式安装的区别
单机安装:只在一台机子上运行,存储采用本地文件系统,没有采用分布式文件系统HDFS
伪分布式:hadoop存储采用HDFS,但是HDFS的名称节点和数据节点都位于同一台机器上
超重点:HDFS块的概念及意义
概念:默认一个块的大小是64MB,在HDFS中的文件会被拆分成多个块,每个块作为独立的单元进行存储
意义:支持大规模文件存储,简化系统设计,适合数据备份
超重点:名称节点的构成与合作关系
构成:FsImage维护文件系统树及元数据,EditLog记录所用的创建,删除,重命名操作,第二名称节点正常状态下定时同步FsImage,故障情况下用于恢复
合作关系:开始进入时读取FsImage中的内容,然后操作过程记录在EditLog中,再次打开FsImage时会重新执行EditLog中的内容一次。第二名称节点,定期使用网络请求的方式将EditLog和FsImage下载到本地,在本地对FsImage中的内容执行EditLog的操作,然后将新的FsImage上传回名称节点替换掉原本的FsIamge,EditLog也用新的文件代替。
读HDFS操作的指令:
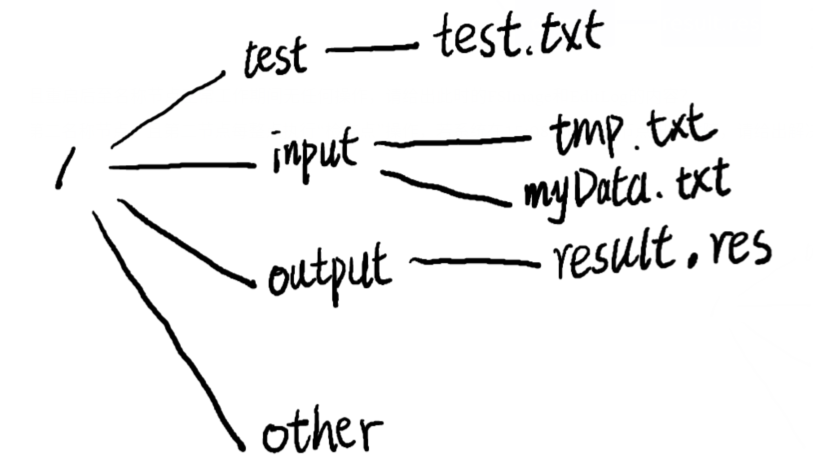
假设HDFS中名称节点NameNode下FsImage中保存的文件目录结构以及EditLog中的内容如下图所示,回答如下问题:

1)若16:00时系统重启,且重启后至名称节点正常工作期间无任何操作,请给出此时的FSImage和EditLog的内容?
2)若此HDFS系统配置有第二名称节点,且第二节点每整点执行“检查点”操作,若系统在15:08分时名称节点出现故障,请给出解决措施,并给出最终恢复的名称节点中FSImage和EditLog的内容?
解题:
1)按顺序执行上面的内容
- 创建other文件夹
- 将myData.txt文件放进/input文件夹中
- 删除/input中的data.txt文件
- 在/input文件夹中创建一个tmp.txt文件
EditLog中没有任何的内容,FSImage的内容如下图所示:
2)在执行到15.08分时,出现故障,此时EditLog文件中记录了最开始的三条操作,恢复结果应该如下图所示(只执行前三条操作),FSImage为空。
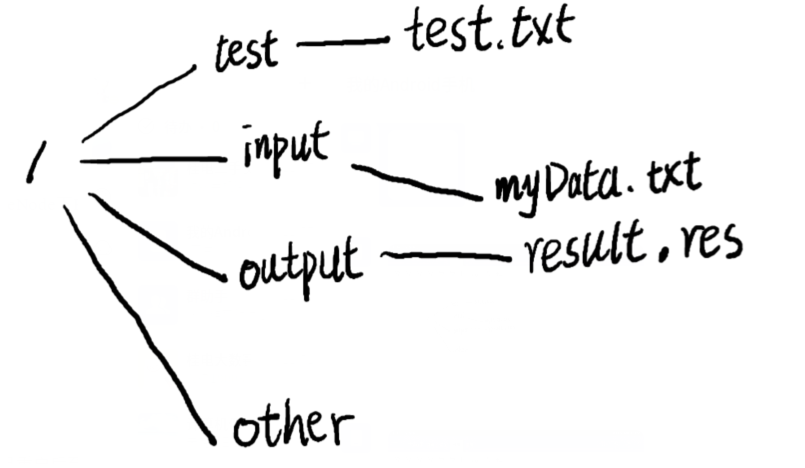
解决措施:第二名称节点先复制名称节点的FSImage文件和EditLog文件,再将两个文件通过网络请求的方式下载到本地,然后第二名称节点在本地执行EditLog中记录的操作,并修改复制的FSImage文件。在执行玩EditLog中的操作后,上传新的FSImage文件替换名称节点中FSImage文件,名称节点中的EditLog文件也用空文件替换。
3. 超重点:HDFS的存储原理
假设文件分成了2个块A和B,那A和B的上传是按序的,先A后B对吧,但是因为有复制的过程,假设复制因子=3,则先上传A,A要复制3份啊,这3份的复制过程是并行的;A都复制完了之后,B再开始,3份B的复制过程开始
- 如果是在集群内发起写请求,则把第一个副本放置在发起写操作的数据结点上,实现就近写入数据。如果是来自集群外部的写操作请求,则从集群内部挑选一台磁盘不太满,CPU不太忙的数据结点,作为第一个副本的存放地。
- 第二个副本会被放置在与第一个副本不同的机架的数据结点上
- 第三个副本会被放置在与第一个副本想头给你的机架的其他结点上
- 如果还有更多的副本,则继续从集群中,随机选择数据结点进行存放

4. 数据读取
客户端可以通过API获取自己的ID和机架的ID,客户端请求数据到机架请求数据就需要ID,客户端请求的内容会获得目标数据及其副本的位置,当搜索到第一个位置ID与客户端ID相同时,有限读取这个副本
5. 超重点:数据复制
客户端将文件写入HDFS时,现在本地将文件分成若干块,然后向HDFS集群发起请求,然后名称节点返回一个数据节点存放位置和其他副本的存放位置列表,每传送好4KB就向副本传输。
总之就是说,一旦原本的文件存放完成,副本也存放完成了
4. HDFS存储机制
简述HDFS的写入过程和读入过程,假设复制因子为3?
- 读入时
- 客户端向名称节点请求上传文件,名称节点检查目标文件是否已经存在,父目录是否存在
- 名称节点返回是否可以上传
- 客户端请求第一个块上传到那几个数据节点服务器上
- 名称节点返回3个数据节点,分别为D1,D2,D3
- 客户端请求D1上传数据,D1收到请求会继续调用D2,然后D2调用D3,将这个通信管道建立完成
- D1,D2,D3逐级响应客户端
- 客户端开始往D1上传第一个块(先从磁盘读取数据放到第一个本地内存缓存),以包为单位,D1收到一个包就会传给D2,D2传给D3,D1每传一个包会放入一个应答队列等待应答
- 当一个块传输完成之后,客户端再次请求名称节点上传第二个块的服务器(重复3-7)
- 写入时
- 客户端向名称节点请求下载文件,名称节点通过查询元数据,找到文件所在的数据节点地址
- 挑选一台数据节点(就近原则,然后随机)服务器,请求读取数据。
- 数据节点开始传输数据给客户端(从磁盘里面读取数据放入流,以包为单位来做校验)
- 客户端以包为单位接收,现在本地缓存,然后写入目标文件
5. 超重点:数据错误的恢复(P56)
- 名称节点出错:
- 首先到远程挂载的网络文件系统中获取备份的元数据信息,放到第二名称节点上进行恢复,并把第二名称节点作为名称节点来使用
- 数据节点出数据出错:
- 数据节点定期向名称节点发送信号,,当数据节点故障时,名称节点收不到这个信号,就标记数据节点为不可读状态,名称节点不会向其发送IO请求
- 如果这导致数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本
- 数据出错:
- 客户端会采用MD5和SHA-1对数据块进行校验
- 当客户读取文件的时候,会先读取该信息文件,然后利用该信息文件对每个读取的数据块进行校验
- 如果出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并重新复制这个块。
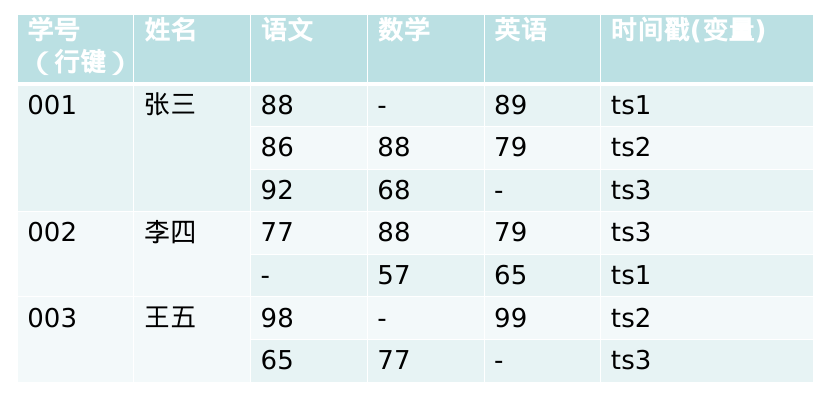
6. 超重点:数据库的数据模型,概念视图,物理视图
数据模型:就是我常见的样子,左边是行键,然后列族堆下来,每个列族下面有对应的列限定符,然后就是对应的数据了
概念视图:行键在左边,然后是时间戳,对应时间,然后就是每一个列族了,然后每个时间戳对应的记录就是这个时间戳的时候记录的修改,记录方式为
列族名称:列限定符=数值,列限定符=数值。。。
物理视图:每个列族拆成一个表,每个表中,行键在最左边,然后对应时间戳,然后列族,列族的表示方式为:列族:列限定符=数值
列式存储(DSM):DSM以关系数据库中的属性或列作为单位进行存储,关系中多个元组的同一属性值(或同一列值)会被存储在一起,而一个元组中不同属性值通常会被分别存放于不同的磁盘页中。
例:给定如下的数据,请按要求完成如下问题:
1)请将该数据转化为HBase数据模型
2)分别画出该数据模型的概念视图和物理视图
7. 超重点:Region定位的三层映射结构
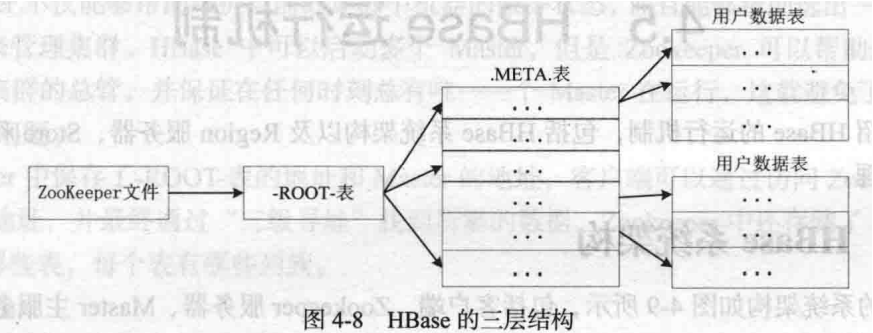
用户数据表中初始化时一个数据表对应一个Region,随着Region的增大会不断进行分裂,这些Region被分发到不同的Region服务器上。
Region标识符和Region服务器标识符组成一个条目被记录在".META."表(元数据表)中(元数据就是Region和Region服务器之间的对应关系)
当".META.“表也会分裂成多个Region,这时候就要将这些Region映射到”-ROOT-"表中
"-ROOT-"表不会再继续分裂了,“-ROOT-”表的位置被记录在ZooKeeper文件中。
8.超重点:Region服务器的工作原理
- 用户读写数据的过程
- 写入:分配Region服务器去执行操作,首先将用户数据写入MemStore和HLog中,当操作写入Hlog后,commit()调用才会将其返回到客户端中
- 读取:Region服务器首先访问MemStore缓存,如果数据不在缓存中,才会到磁盘上的StoreFile中去寻找
- 缓存的刷新
- Region服务器会周期性地将MemStore缓存里的内容写入磁盘的StoreFile文件中,清空缓存,并在HLog文件中进行标记,用来表示内容已经写入了StoreFile中
- 在启动时,每个Region服务器会检查自己的Hlog文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作。
- StoreFile合并
- MemStore缓存刷新都会在磁盘上生成一个新的StoreFile文件,当StoreFile的文件数量达到一个阈值时,就会将StoreFile合并成一个大文件
9. 超重点:Store的工作原理
当用户写入数据时,系统首先把数据放入MemStore缓存中,当MemStore缓存满时,就会刷新到磁盘中的一个StoreFile文件中。
当达到实现设定的数量时,就会出发文件合并操作,多个StoreFile文件会被合并成一个大的StoreFile文件。
当单个StoreFile文件大小超过一定阈值时,就会出发文件分裂操作
同时,当前的一个父Region会被分裂成两个Region,父Region会下线,新分裂的两个子Region会被Master主服务器分配到相应的Region服务器上
10.超重点: HLog的工作原理
HBase系统为每个Region服务器配置了一个HLog文件,用户更新数据必须首先被记入日志才能吸入MemStore缓存,并且知道MemStore缓存对应的日志已经写入磁盘之后,该缓存内容才会被刷新写入磁盘。
Zookeeper服务器会实时监视Region服务器的状态,当某个Region服务器发生故障时,ZooKeeper服务器会通知Master主服务器。Master主服务器首先会处理该故障Region服务器上面遗留的HLog文件,会把每条日志记录所述的Region对象对HLog数据进行拆分,分别放到相应的Region对象的目录下,然后将失效的Region重新分配到可用的Region服务器中。Region服务器获取到失效的Region后,执行Region中的日志操作,然后写入到自己的HLog和缓存之中,并立即对缓存进行刷新。
例子:
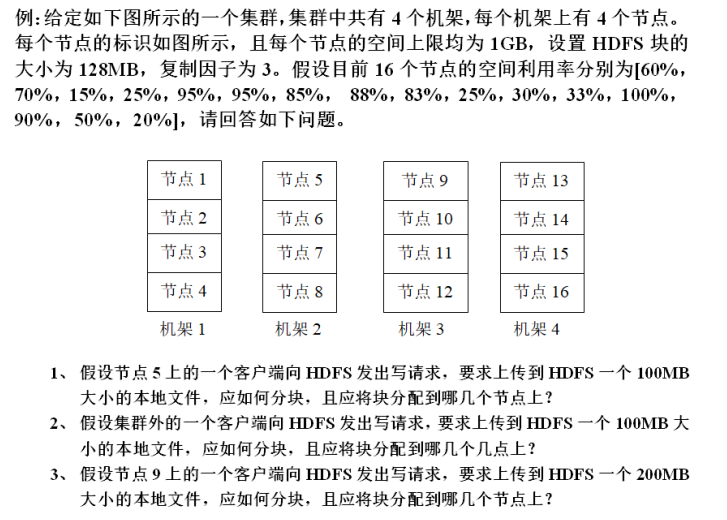
假设一个HBase集群中有1个Master服务器(表示为MS)以及5台Region服务器,分别标识为RS1,RS2,RS3,RS4和RS5,HBase中设置Region的默认大小为128MB。假设目前HBase中存储了一个大小为1GB的数据表,该数据表被分成了10个Region,分别标识为**R1,R2,…,R10,**且集群中各Region服务器负载均衡,即RS1中存放了R1和R2;RS2中存放了R3和R4;以此类推。假设META表被分割成2份(M1和M2)分别保存在RS2和RS5中,M1表存放了R1-R5的信息,M2表存放了R6-R10的信息,ROOT表保存在RS1中。请回答如下问题。
- 请根据如上的描述,分别写出ROOT表以及各个META表中完整的映射关系,画出HBase相应的三层映射结构。
- 假设某个操作员按照上级的要求在如下表规定的时间对HBase进行相应的操作,且HBase在12:00正式启动完毕,假设表中的操作全部映射到RS2,
(1)请列出14:00时(假设OP7已完成)RS2上Hlog的内容。
(2)若14:00时RS2发生故障,缓存的刷新频率为1小时1次(每个整点的01分开始刷新),若Master已经获知了RS2的故障信息并准备将R3和R4分别分配给RS1和RS3,请描述整个分配过程,包括HLog,缓存的内容变化,R3和R4需要执行哪些操作以及各个服务器如何协作?
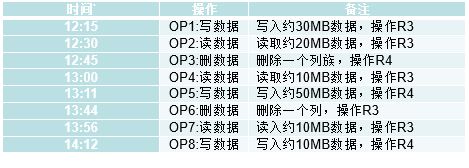
解答:

11. NoSQL数据库(例题即可)
例:简述NoSQL数据库的四大类型以及各类型的至少2个代表数据库?
- 键值数据库:Redis,Riak
- 列族数据库:Hbase,BigTable
- 文档数据库:MongoDB,SisoDB
- 图数据库:InfoGrid,GraphDB
CAP理论:一致性(Consistency)、可用性(Availability)、分区容忍性(Tolerance of Network Partition)
例:如图所示,假设M1和M2为两个分布式环境下的节点,M1和M2为数据V副本的存放节点,进程P1向M1写入新值val1,进程P2读取M2的值。当新值更新失败时,该分布式系统的操作如上图,请从CAP理论的角度解释图中的流程,并给出该系统基于CAP理论的设计原则?
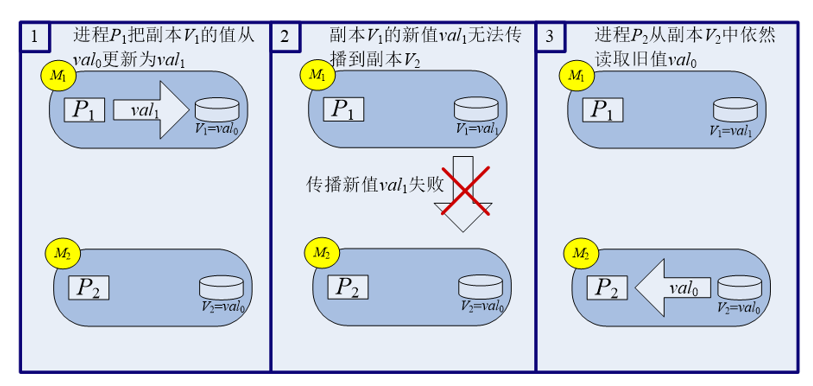
该分布式系统采用AP设计原则,
当网络发生故障时M1中的消息无法发送到M2,这是进程P2在节点M2读取的副本V2的值仍然是旧值val0,产生了不一致问题,不满足一致性理论©
P1和P2都能迅速到达V1和V2获取自己想要的数据,满足可用性理论(A)
即使V1节点发生故障,V2节点仍然能发挥作用,满足了分区容忍性理论§
什么是最终一致性?根据更新数据后各进程访问到数据的时间和方式的不同可以分为哪几类?
最终一致性:允许后续的访问操作可以暂时读不到更新后的数据,但是经过一段时间之后,用户必须读到更新后的数据。
类别:
- 因果一致性
- ”读已之所写“一致性
- 会话一致性
- 单调读一致性
- 单调写一致性
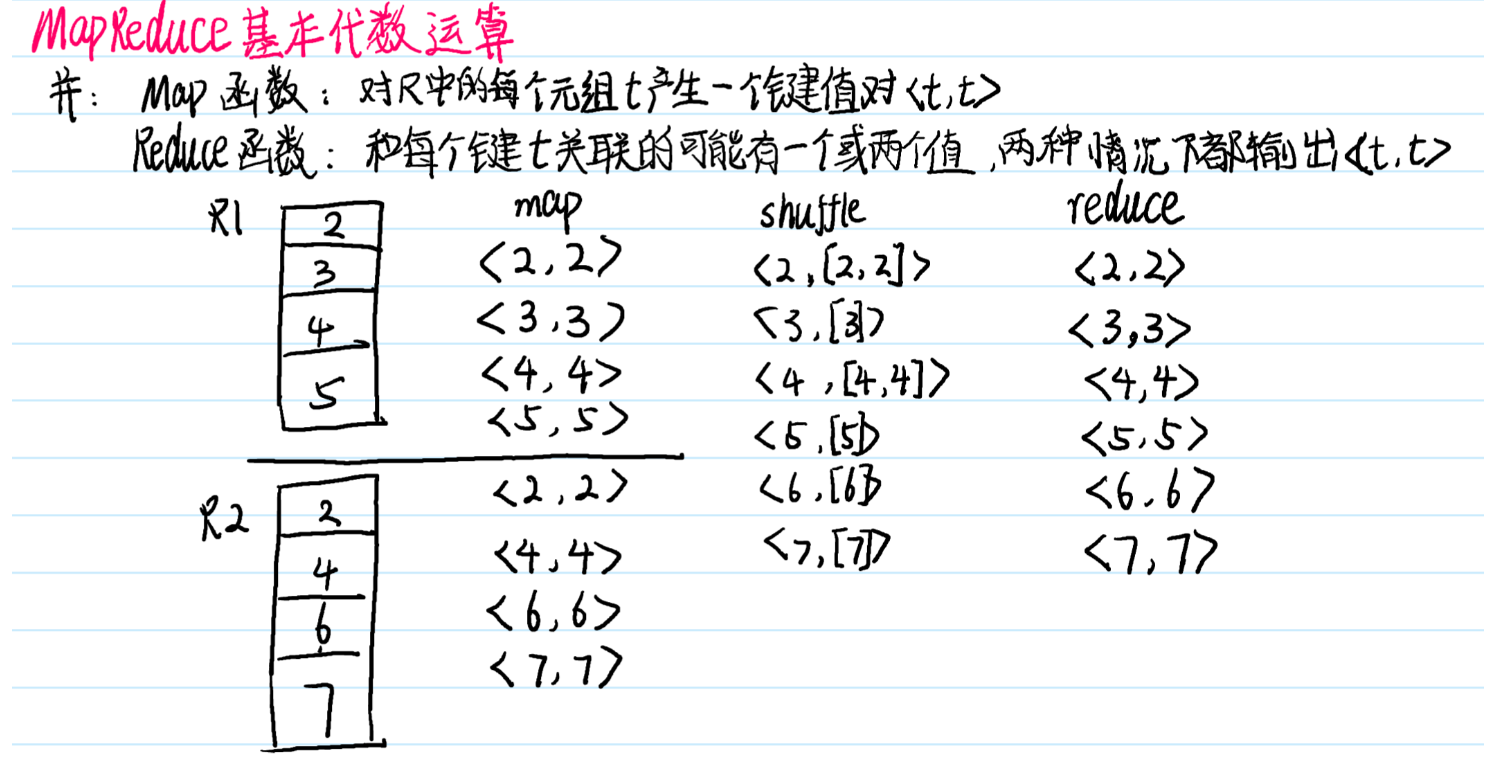
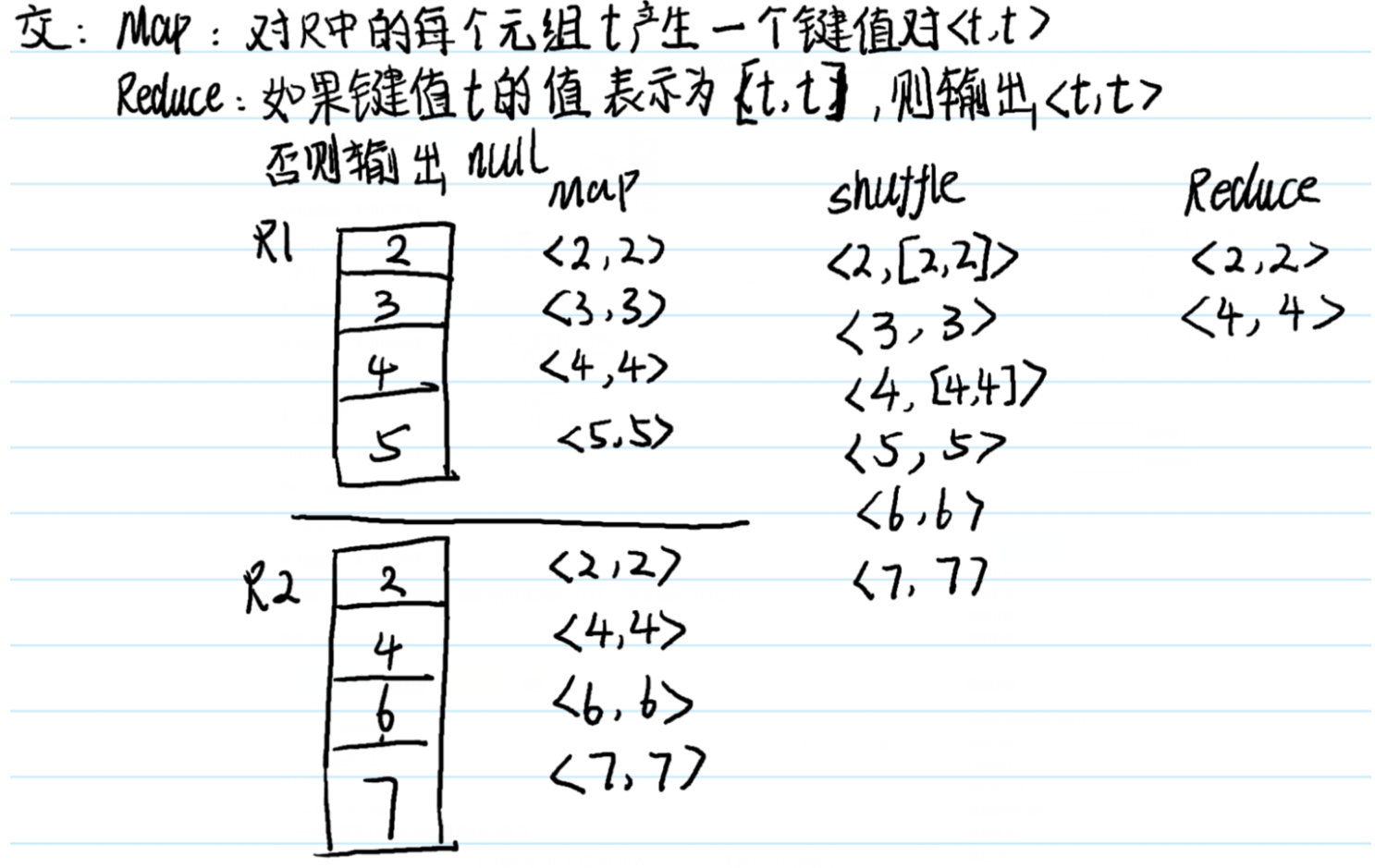
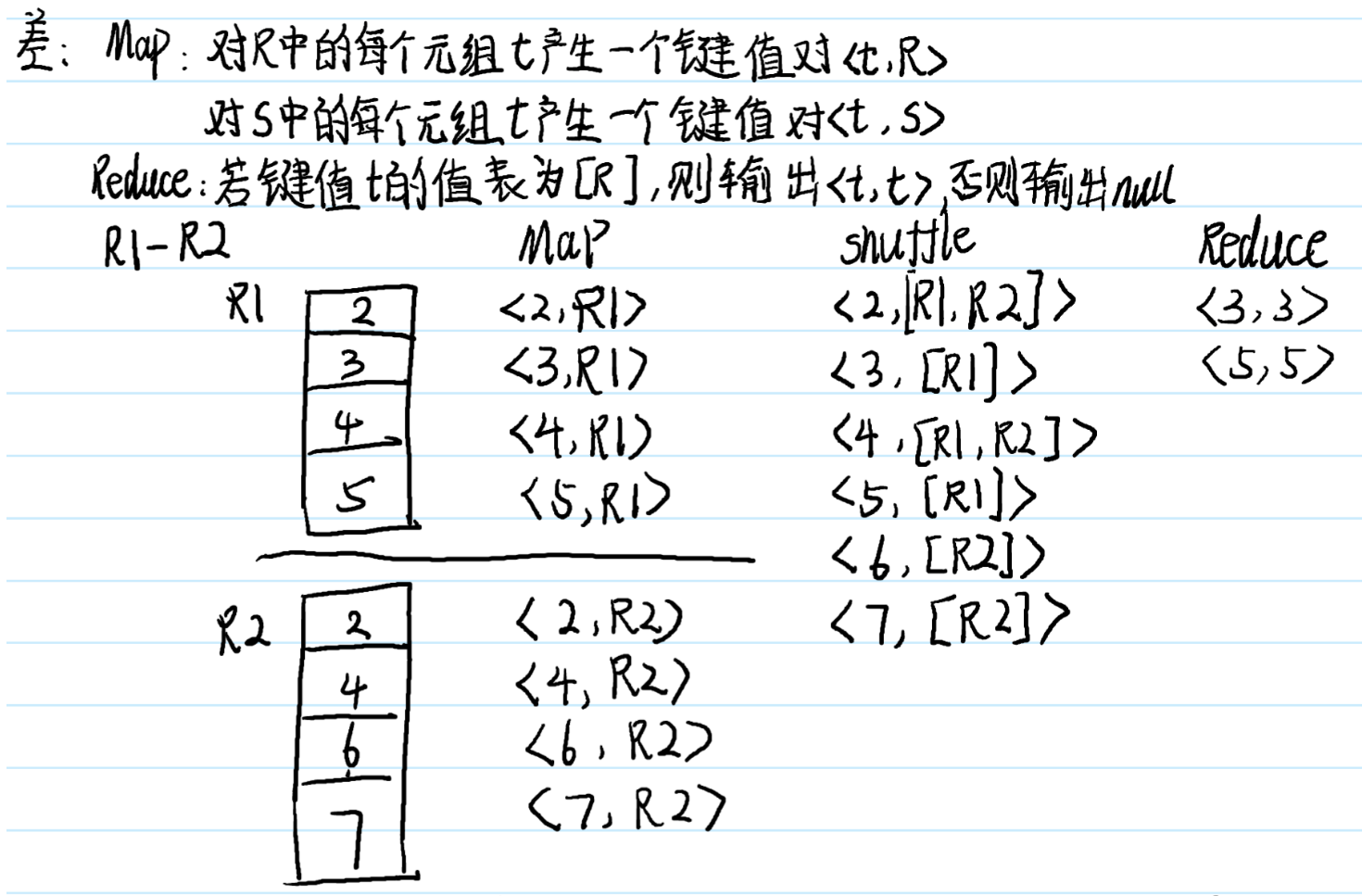
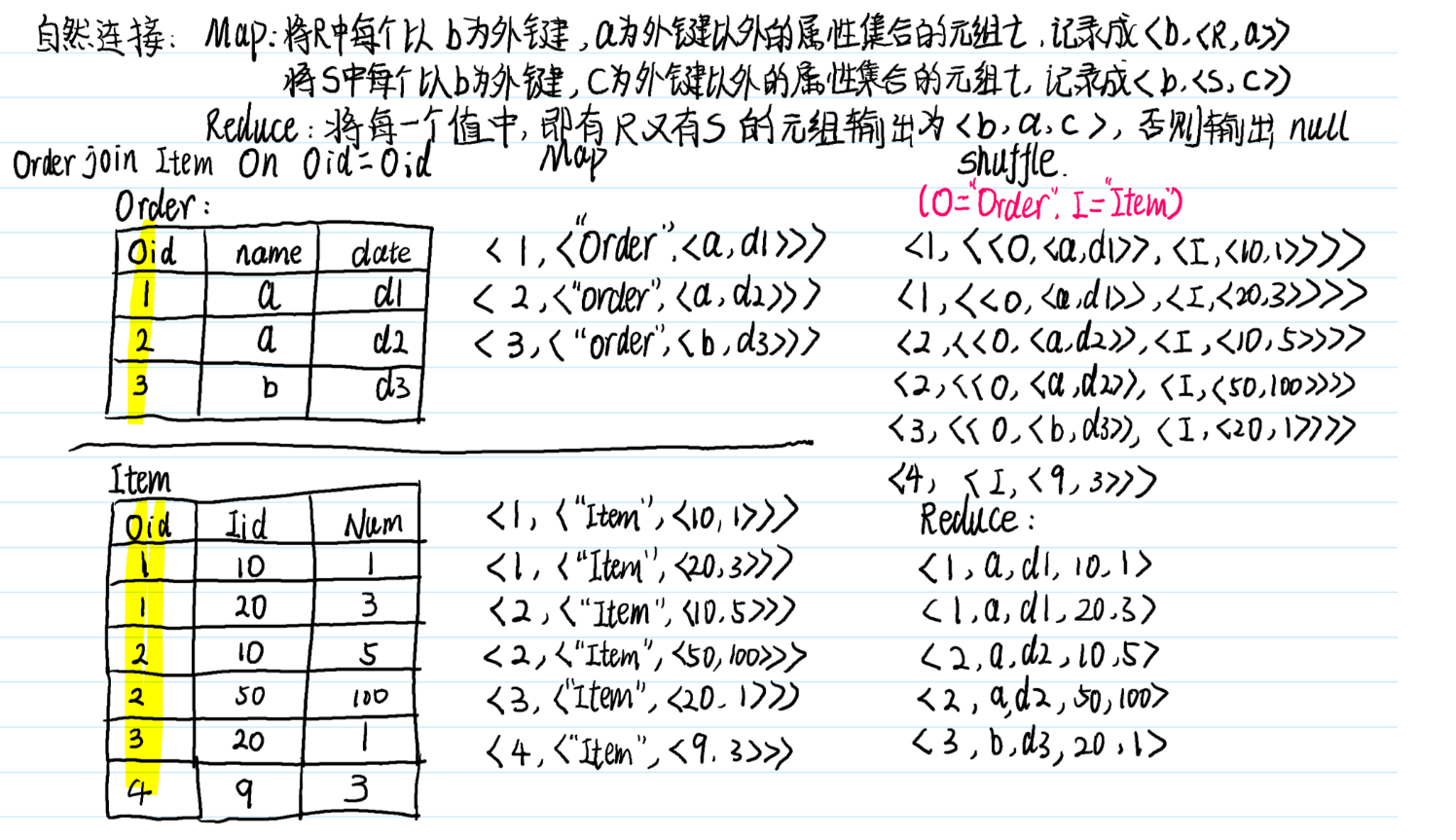
12.超重点:MapReduce代数运算
shuffle的过程,如果值只有一个元素就直接写,如果有多个元素,尖角号括起来,不要被下面的写法误导了
纠正一点:下面的shuffle过程只针对一个map内,我下面写的shuffle包含了多个map,这个地方错了,不过shuffle的思想没有错

13. 超重点:MapReduce的Top-k 极值问题
某大型超市想要对最近 10 天的销售数据进行分析,每一天的数据均保存在一个文件中。现要求对这 10 天的销售数据用大数据相关技术进行分析,指定一个参数 k,请设计一个大数据算法返回销量最低的前 k(top-k)个商品,并打印出它们各自的总销量。请设计相应的算法,给出你用到的大数据相关的技术,编写相应代码并进行演示。
输入:
10 天的数据文件,文件名为 data_i.txt 表示第 i 天的销售数据。每个文件中 1 行有 2 个值,第 1 个值为商品名称,第 2 个值为用户一次购买的数量。因只用于测试,每个文件仅有10000 行左右的数据。(测试数据见附件!)
k:需要返回的销量最高的商品的个数;
输出:
前 k 个销量最高的商品名称以及商品的总销量。
示例:
假设只有 2 天的数据且两天的数据如下图所示,
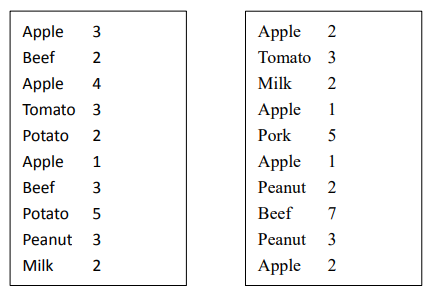
若设置 k=2,则应输出(按字母序排列!):
Apple: 14
Beef: 14
若 k=1,应输出 Apple:14
若 k=3,应输出:
Apple: 14
Beef: 14
Peanut: 8
解题思路 1:首先,将该问题变成一个经典的 wordcount 问题,word 即为商品名称,对应的 count 可以直接从原始文件中取,这样 Map 任务即输出<商品,数量>的集合,假设一个文件对应一个 Map 任务,则 Reduce 端不需要任何处理,直接将最终的<数量,商品>写入HDFS 即可,之所以是<数量,商品>的集合,是因为 Shuffle 过程中会对 key 进行排序,若key 为数量,则我们不需要写任何排序代码,将第一次 MapReduce 生成的文件直接进行MapReduce 任务,Map 直接读即可,Reduce 端直接迭代并倒序输出即可,不需要任何多余的代码。该方法代码量非常少(可能自己写的代码只要十几行),实现也非常容易。
解题思路 2:该思路只需要一次 MapReduce 过程,Map 过程类似于 wordcount 过程,在Reduce 任务中,可以获得所有商品的销售总量的哈希表,基于这个哈希表,我们可以设计非常多高效的方法进行 Top-k 极值的选择,最简单的方法就是先排序,再取前 k 个,代码量也很少,且容易实现,但时间复杂度为 O(n2)。当然,这里面还有很多很多巧妙的解决方式,不 需 要 全 排 序 既 可 以 拿 到 结 果 , 详 细 请 戳 :https://blog.csdn.net/wufaliang003/article/details/82940218,最快可达到 O(logn),请同学们根据自己的兴趣进行发挥。

14. 超重点:MapReduce的购物篮数据的关联分析
某大型商场预计在下个周进行一次大型的促销活动,促销的主要手段为捆绑销售,即将某些商品进行捆绑销售并以一定的折扣卖出。然而,捆绑并不是随机的,商场希望捆绑的商品都是关联的,即若在平时用户买了商品 A,则他有大概率会买商品 B 的话,将 A 和 B 进行捆绑就有很大概率比单卖的话销量更高,即A 和 B 是关联商品。现要求设计一个大数据算法,利用大数据相关的技术,获取尽可能多的关联商品集合,以帮助该商场获得尽可能多的利润。然而,偶尔的关联性并不能很好地说明物品间的联系,因此,给定该商场最近 10 天的所有销售记录(用户的购买记录)t,若存在一个商品集合 s = {A,B,C} ∈t,s 若能频繁地出现在销售记录中,则 s 就可能是一个关联的商品集合。为了量化该频繁性,给定一个参数 d,d 为正整数,若|s|不小于 d,则 s 就是一个关联集合,请设计算法求出所有的关联集合,给出用到的大数据的相关技术,编写相应代码并演示
输入:
10 天的销售数据文件 data.txt,文件中每一行代表一个用户的购买记录,如“apple, milk, beef”表示用户一次性买了苹果、牛奶和牛肉。因只用于测试,该文件仅有 10000 行左右的数据。(测试数据见附件!)
d:需要满足的最小频繁度;
输出:
返回所有的关联集合以及它们各自的频繁度,且集合内商品的数量不小于 2。
示例:
假设文件 data.txt 的内容如下图所示:

若设置 d=2,则应输出:
{Bread, Diaper, Beer}, 2
{Bread, Diaper}, 2
{Bread, Beer}, 2
{Diaper, Beer}, 3
思路提示:
本题为求解所有的关联集合,用白话来说,给定某个集合 S,若 S 出现在数据集中的次数达到了 d 以上,则 S 就可以输出了,因此,本题转化为求 S 的个数的问题,基于 MapReduce的特性,我们 Map 的输出一定得是<集合,在当前数据集中存在的个数>这样的一个键值对,然而,数据集给的是一条一条的记录,一个记录里可能包含了很多的集合,因此,本题的难点在于如何把这些集合都拆解出来,而拆解集合其实就是一个求子集的过程,每读到一条购物记录,则将其所有子集拆出来(只含 1 项的去掉),然后转化为<子集,1>的形式,这样又变成了 1 个 wordcount 问题,Reduce 过程几乎不用做任何处理。所以,当数据集被读入时,每读到一个购物记录,则生成该购物记录的所有子集,剔除其中只含有 1 个商品的子集,并将每个子集计数为 1,并输出。Reduce 端不需要做任何处理,只要判断某个集合的计数是否不小于 d,若不小于 d 则输出即可,本题完结。

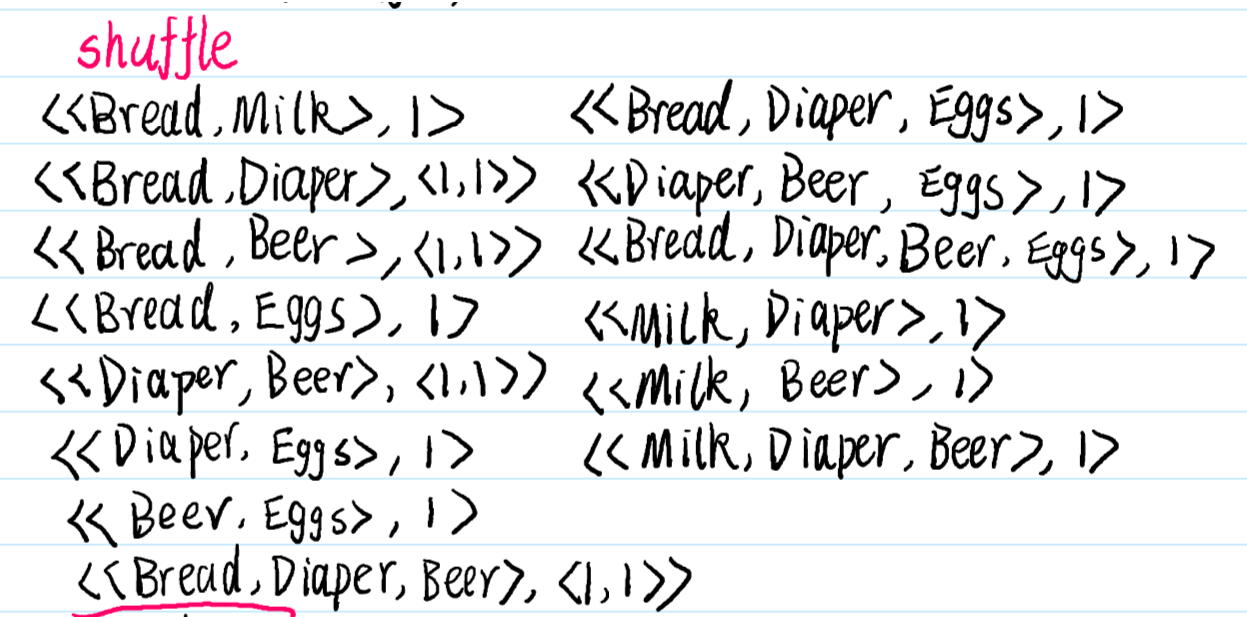
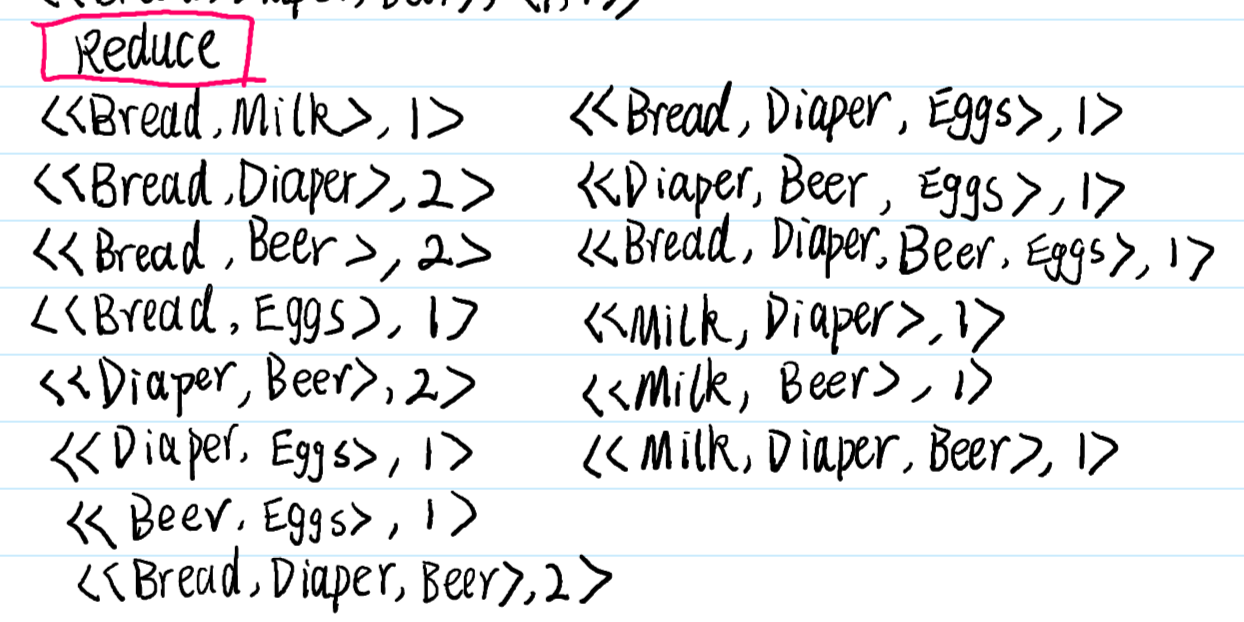
15. 超重点:窄依赖和宽依赖以及stage划分
窄依赖:一个节点出发只能指向一个节点
宽依赖:一个节点出发可以指向多个节点
stage划分,如果碰到宽依赖,就划分为一个stage,如果没有碰到就继续往后走
例:给定如下图所示的RDD依赖关系DAG,请指明其中哪些RDD的依赖关系为窄依赖,哪些为宽依赖?并根据此DAG图划分stage,给出你划分的stage?
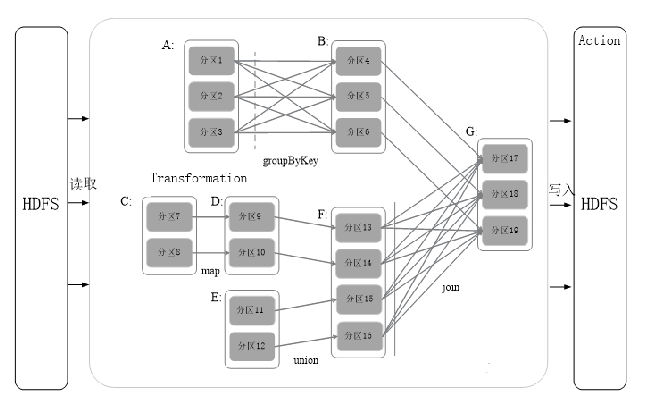
宽依赖:A->B,F->G
窄依赖:C->D,C->F,B->G,E->F
划分为三个Stage:
- A
- C,D,E,F
- A,B,C,D,E,F,
16. 超重点:RDD的概念,“血缘关系”以及“惰性调用”
概念:
一个RDD就是一个分布式对象集合,本质上是一个**只读的分区记录集合,**每个RDD可以分成多个数据集片段,可以保存在集群中的不同节点上,在不同的节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和group by)而创建得到新的RDD。
惰性调用:在RDD执行过程中,真正的计算发生在RDD的"行动"操作,对于"行动"之前的所有"转换"操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD的生成轨迹,即相互之间的依赖关系,而不会出发真正的计算。
说白了就是之前都是在生成新的RDD,只有在最后行动的时候才进行计算
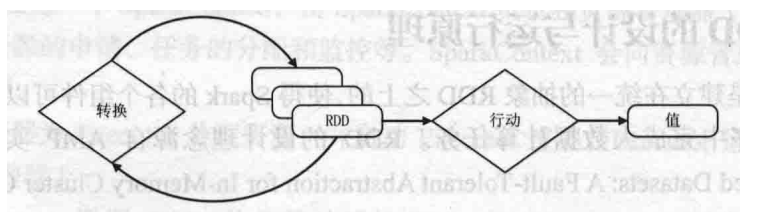
血缘关系:本质上是DAG拓扑排序的结果。在输入之后,会在逻辑上生成各种RDD,最后在行动的时候,才将RDD之间的生成和依赖关系进行使用,计算最终结果的过程就是血缘关系起作用的过程。
优点:惰性调用、管道化、避免同步等待、不需要保存中间结果、每次操作变得简单
17.超重点RDD的各个操作的辨析
下面都是转化操作
map,filter→两个集合一对一
union→三个集合,两个集合一对一指向第三个集合的不同节点
join→三个集合,两个集合一对一,指向第三个集合的任意节点
groupByKey→两个集合多对多
join→三个集合,两个集合多对多,指向第三个集合的任意节点
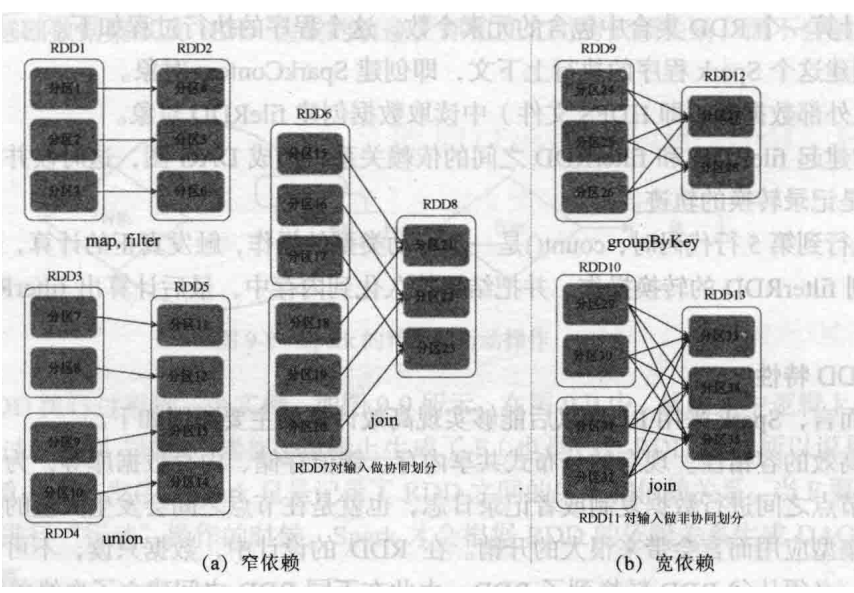
18.超重点:RDD的容错方式
RDD数据只读不改,如果需要修改数据必须从父RDD转化到子RDD,由此在不同的RDD之间建立了血缘关系。
RDD是具有容错机制的特殊集合,不需要通过数据荣誉的方式实现容错,而只需要通过RDD父子依赖关系重新计算丢失的分区来实现容错,无须回滚整个系统。
19.超重点:RDD的wordcount代码
5行代码实现他
conf用于配置Spark的上下文
sc实例化SparkContext
textFile实例化文件内容
flatMap每个输入可以映射多个输出结果,这里映射为每一行按照空格分割后的结果
map映射每一个单词对应出现一次,
reduceByKey定义每个键值对的值之间进行的操作
collect()收集reduce的结果
1 | val conf = new SparkConf().setAppName("word count") |
20. 超重点:Store的wordcount代码
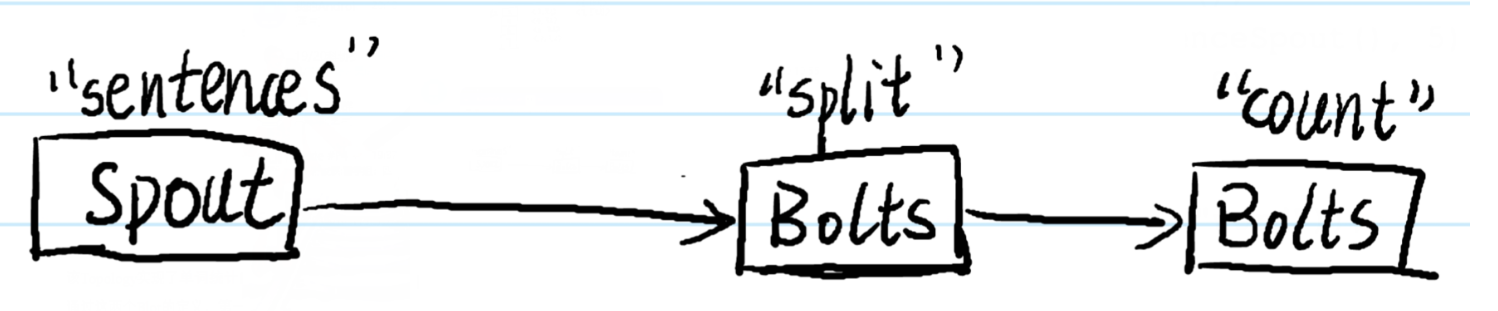
例:给定如下所示的Storm相关代码,请说明该拓扑的作用?该拓扑中定义了两个Bolt,试述两个Bolt各自完成的功能,以及中间结果如何在两个Bolt之间传输?

该Topology实现了单词统计的功能。在Topology中包含了两个Bolt处理器,同时每个Bolt使用了Grouping()系列方法定义了Tuple的发送方式。
通过这两个Blot的定义,第一个Bolt用于单词的分割,该Blot中的任务随机接收Spout发送的句子,并从接受的句子中提取出单词
第二个Bolt接受第一个Bolt发送的Tuple进行处理(Bolt是通过定于Tuple的名称来接收相应的数据,第一个Bolt声明其输出Steam的名称为‘split’,而第二个Bolt申明其订阅的Steam为’split’,因此第二个Bolt可以接受到第一个Bolt发送的Tuple)
即统计分割后的单词出现的次数。通过fieldsGroupings()方法,在’word’上具有相同字段值的所有Tuple(即单词相同的Tuple)将发送到同一个任务中进行统计,从而保证了统计的准确性
上面代码的拓扑图:
21.超重点: Storm中各个分组策略的辨析
- ShuffleGrouping:随机分组,随机分发Stream中的Tuple,保证每个Bolt的Task接受Tuple的数量一致。
- FieldsGrouping:按照字段分组,保证相同字段的Tuple分配到同一个Task中
- AllGrouping:广播发送,每个Task都会收到所有的Tuple。
- GlobalGrouping:全局分组,所有的Tuple都发送到同一个Task中
- NonGrouping:不分组,和ShuffleGrouping类似,当前Task的执行会和他的被订阅者在同一个线程中执行
- DirectGrouping:直接分组,直接指定由某个Task来执行Tuple的处理




