「论文阅读」Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
论文名称:Learning from Pixel-Level Label Noise: A New Perspective for Semi-Supervised Semantic Segmentation
作者:Rumeng Yi; Yaping Huang; Qingji Guan; Mengyang Pu; Runsheng Zhang
期刊:IEEE Transactions on Image Processing,2021
原文摘要
This paper addresses semi-supervised semantic segmentation by exploiting a small set of images with pixel-level annotations (strong supervisions) and a large set of images with
only image-level annotations (weak supervisions). Most existing approaches aim to generate accurate pixel-level labels from weak supervisions. However, we observe that those generated labels still inevitably contain noisy labels. Motivated by this observation, we present a novel perspective and formulate this task as a problem of learning with pixel-level label noise. Existing noisy label methods, nevertheless, mainly aim at image-level tasks, which can not capture the relationship between neighboring labels in one image. Therefore, we propose a graph based label noise detection and correction framework to deal with pixel-level noisy labels. In particular, for the generated pixel-level noisy labels from weak supervisions by
Class Activation Map (CAM), we train a clean segmentation model with strong supervisions to detect the clean labels from these noisy labels according to the cross-entropy loss. Then, we adopt a superpixel-based graph to represent the relations of spatial adjacency and semantic similarity between pixels in one image. Finally we correct the noisy labels using a Graph Attention Network (GAT) supervised by detected clean labels. We comprehensively conduct experiments on PASCAL VOC 2012, PASCAL-Context and MS-COCO datasets. The experimental results show that our proposed semi-supervised method achieves the state-of-the-art performances and even outperforms the fully-supervised models on PASCAL VOC 2012 and MS-COCO datasets in some cases.
Abstract
本文使用以小组带有像素级标注的图像(strong supervisions)和一大批只带有图像级标注的图像(weak supervisions)来解决半监督语义分割的问题。
现有的大多数方法旨在从薄弱的监督中生成精确的像素级标签,然而,我们注意到那些生成的标签任然不可避免地包含有噪声的标签,于是本文基于这一观察结果,提出了一个新的视角,定义此任务为像素级标签噪声的学习问题。
- 提出了一种基于图的标签噪声检测(graph based label noise detection)与校正框架(correction framework)来处理像素级的噪声标签。
- 使用类激活映射(Class Activation Map ,CAM)生成弱监督像素级标签,使用一个强监督训练的分割模型,依据交叉熵损失从这些噪声标签中筛选出干净的标签(clean label)
- 采用基于超像素的图(superpixel-base graph)来表示图像中像素之间的空间邻接关系(adjacency)和语义相似性(semantic similarity)
最后使用图像注意网络GAT(Graph Attention Network)对检测到的干净标签进行监督,对有噪声的标签进行校正
Introduction
半监督方法的关键步骤:在图像级弱标注的情况下,对大量图像进行精确的像素级标注
类激活映射(Class Activation Map,CAM):通过从深度分类模型中研究隐藏单元的贡献来突出局部有识别力的区域(local discriminative regions)
缺点:生成的目标区域较小或稀疏,不足以覆盖整个目标区域
后来他们专注于使用不同的技术来拓展这个有识别力的区域:
- 像素亲和力(pixel-level affinities)
- 对抗性消除方法(adversarial erasing manner)
- 随机正则化(stochastic regularization)
从下图可以看出,置信度高的区域并不意味着其对应的标签总是正确的
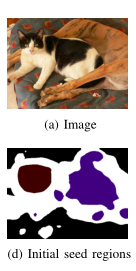
d表示初始的分割种子(用上面的方法处理出来的标签,具有高置信度的部分)(黑色表示背景,白色表示未标记的像素)。
本文通过观察CAM产生的一大部分噪音标签,提出了一个新的视角,他们将半监督语义分割表述为像素级标签噪声的学习问题。
解决这个问题的关键是对像素级标签之间的关系进行建模,因此本文提出了一种基于图的噪声检测与校正框架来捕获相邻像素之间的关系,并进一步利用这些关系来校正噪声标签。
本文贡献:
- 从一个新的角度解决半监督语义分割问题,并将其定义为像素级标签噪声的学习问题
- 提出了一种基于图的标签噪声检测与校正框架来处理像素级的噪声标签,该框架能够捕获图像中像素级标签之间的关系,有效地校正图像中的噪声标签。
relate work
学习噪声标签
大多数大规模的数据集都包含有噪声的标签。缓解噪声标签影响的技术可以分成两类:
- 检测噪声标签(detecting noisy labels),然后清楚潜在的噪声标签或降低标签噪声标签的影响
- 直接训练带有噪声标签的噪声鲁棒模型(noise-robust models)
处理图结构数据
基于光谱的图卷积(Graph Convolutional Network,GCN),在这类方法中,学习的滤波器依赖于拉普拉斯特征基。
基于空间的方法根据节点的空间关系定义图的卷积,其中图像可以被视为图的特殊形式,每个像素代表一个节点。
图注意网络(Graph Attetion Network, GAT)是一种典型的基于空间的方法。引入了一种基于注意力的图结构数据节点分类体系结构,通过关注图的邻居来计算图中每个节点的隐藏表示。
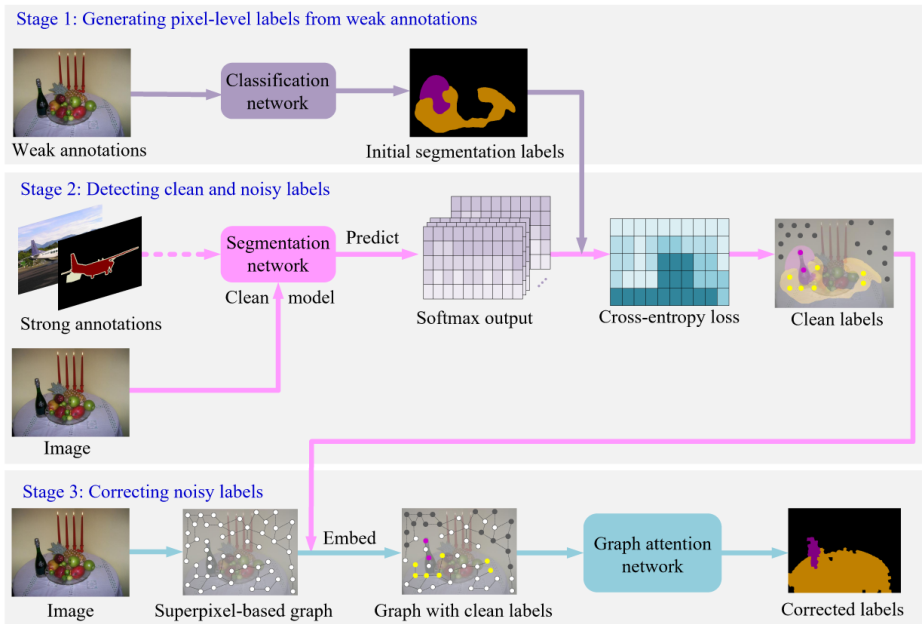
首先使用CAM从弱标签中生成原始的分割标签,然后使用带有精细标签的数据集进行训练clean模型(分割网络),将从这个clean网络预测的结果与初始的原始标签计算交叉熵损失,然后得到Clean标签。将图像构建成超像素图的结构,将clean标签嵌入到超像素图中,然后使用GAT(Graph attention network)网络对噪声标签进行纠正,从而获得纠正后的标签。
proposed method
通过弱标注生成像素级标签
首先使用CAMs生成的标签作为初始化的标签,一个ground truth类别c的CAM可以表示为:
其中表示类别的类别激活映射(class activation map)
表示在空间位置上的最后一个卷积层上的第k个单元的激活值
表示第个单元对应类别的权值
除此之外,对于与ground truth无关的类别,本文通过设置的激活值为0,对其进行忽略。
因此,根据激活得分最高的像素,为每个像素分配相应的类标签,激活得分小于0.05的像素为背景。这些生成的像素级标签可以用作初始分割标签,其中显然包含不可避免的噪声标签。
检测干净标签和噪声标签
在本文的方法中,关键问题是在CAM计算初始分割标签中检测出干净和有噪声的标签。在本节中,使用一小组像素级标签来训练一个clean的分割模型,然后根据训练好的clean模型上生成的像素级标签的交叉熵损失检测干净标签和噪声标签。
具体来说,本文训练的像素级标签数据集是由两个部分组成的:,其中表示的是第i个输入图像的像素级ground truth标签。
图像级标签的数据集:,其中是第j个输入图像,是CAM生成的对应的像素级标签。
在这个过程中,本文使用训练分割网络,得到一个clean分割模型。然后使用去预测中的图像的每一个像素的标签,并在的监督下计算他们的交叉熵损失,计算公式可以表示为:
其中是将图像输入clean模型进行预测的分割函数。本文通过阈值,将损失值小的标签认为是clean标签,并将这个clean标签作为GAT训练的监督信息。
纠正噪声标签
现有的带噪声学习方法主要集中在图像分类任务上,没有考虑对一幅图像中像素标签之间的关系进行建模。
本文提出了一种基于图注意网络的方法来校正像素噪声标签。
本文首先考虑空间连接性(spatial adjacency)和语义相似性(semantic similarity)的双重约束,在图像上构造超像素图。然后将clean labels嵌入到图中。
超像素图结构(Superpixel-based graph construction)
超像素可以提供更大的局部同构(locally homogeneous)并且能为精确分割保持大部分结构的相干区域(coherent regions)。
本文将一张图片转化成一个超像素图,其中是一组节点,是一组边,是一个邻接矩阵。
具体来说表示超像素集合,在中的边表示链接两个在空间上相邻的节点和的边。表示节点的接近程度。
顶点构建(Vertex construction)
本文使用简单线性迭代聚类(Simple Linear Iterative Clustering,SLIC)方法去对图像进行过分割(over-segment),并将其分割成一个超像素集合,用表示,其中是一张图像包含的超像素的数量。在本文的是实验中,一张图像过分割后的超像素大约有1000个。
所以本文使用clean模型C从整张图像中提取出高级语义特征并融合全部的超像素。特征图要经过双线性插值得到和原图相同大小的密集特征图,然后在通道上对一个超像素进行平均池化。最终每一个超像素上都能得到一个512维度的CNN特征向量。
边构建(Edge construction)
本文利用图像的两个特性(空间连接性和语义相似性)在图像上构造图的边。
空间连接性意味着相邻的像素往往有相同的标签。
语义相似性意味着具有相同标签的像素可能共享类似的语义信息。
本文假设,两个空间接近的节点又相同的语义内容,这些内容通常属于相同的类别。因此本文考虑了空间连接性和语义相似性的双重约束。
首先,本文将空间相似性在图上进行建模,本文构建空间连接性权重矩阵去测量超像素点和所有超像素点的空间链接关系,如果和具有空间连接性,则权重设置为1,否则设置为0。
然后,本文将语义相似性在图上进行建模,具体来说,本文构造了语义相似性权重矩阵去计算和与他空间相邻的超像素之间的语义相似性。
每一个超像素对应的的512维度的特征向量的权重计算方式为:
其中表示特征向量的维度,如果两个超像素和是空间不相邻的,那么,忽略他们的语义关系。
邻接矩阵的计算方式为:
是从边缘集合中过滤出低相似度的边缘的一个阈值。在本文的工作中,,其中和是均值和标准差。是超像素和他临近的超像素最大的语义相似性。此外,如果同时小于和,边就被去除了。
在对每幅图构造超像素图后,将检测干净标签和噪声标签阶段选择的干净标签嵌入图中,作为训练GAT的监督信息。
嵌入干净的标签(Embedding clean labels)
本文使用表示每一张图片的干净标签集合。其中表示第k个像素,表示的类别标签。如果与重叠,就设置的类别标签为。然而,在实验中发现,一个超像素通常包含不止一个干净标签,所以需要选择干净百骑爱你数量最大的对应标签,并将标签分配给这个超像素。
使用GAT纠正噪声标签(Correcting noisy labels by GAT)
本文将图像转换为基于超像素的图形表示,并利用GAT校正噪声标签。本文在图节点上使用自注意力(self-attention)去计算注意系数。节点j的特征对节点i的重要性为
其中,。 和是反向传播学习的权重参数。本文只为每一个节点计算,其中是图中节点的相邻节点的集合。
为了使系数在不同节点之间容易比较,本文归一化的方式是在所有可选择的中使用softmax函数,该函数可以表示为:
然后利用多头注意(multi-head attention)对上述的图注意力机制进行拓展,给出每个节点的最终输出特征。
其中表示连接,表示非线性函数,如ReLU,由第个注意力机制计算的归一化注意力系数。表示对应的输入线性转化的权重矩阵。
在本文的实验中,采用一个双层的GAT网络进行标签纠正。这个过程可以建模为:
其中是由公式7计算的超像素特征矩阵。是由公式4计算的邻接矩阵。所有嵌入干净标签的超像素的交叉熵损失被定义为:
其中是对应的标签,是嵌入干净标签的超像素的数量。是GAT对的预测结果。
训练分割网络(training the segmentation network)
在每个图像上,最初被认为是噪声的像素分类信息已经得到纠正,因此我们可以根据他们相应的超像素回复每一个像素的标签,然后用密集的CRF细化修正后的分割标签,以更好地评估目标形状。
最后利用检测和校正阶段得到的分割标签作为监督训练分割网络,本文的方法可以使用任何完全监督的语义分割模型。
阅读体会
本质上感觉就是利用了没有精细标注的图像进行训练,训练效果总体来说并没有说完全超过完全标签的训练结果。但是这种方式可以使得研究者使用更少的精细标签,和大量的粗略标签完成分割模型的训练,是一种数据集生成的方式。
优点:利用了没有被精细标注的图像,降低了对精细标注的需求
缺点:实际上训练效果并没有本质上的提高,有时候会稍逊于完全标注的内容。






