「论文阅读」CTNet: Context-based Tandem Network for Semantic Segmentation
CTNet: Context-based Tandem Network for Semantic Segmentation
论文名称:[CTNet: Context-based Tandem Network for Semantic Segmentation](CTNet: Context-based Tandem Network for Semantic Segmentation | IEEE Journals & Magazine | IEEE Xplore)
作者:Zechao Li; Yanpeng Sun; Liyan Zhang; Jinhui Tang
时间:2021
期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence
原文摘要
Contextual information has been shown to be powerful for semantic segmentation. This work proposes a novel Context-based Tandem Network (CTNet) by interactively exploring the spatial contextual information and the channel contextual information, which can discover the semantic context for semantic segmentation. Specifically, the Spatial Contextual Module (SCM) is leveraged to uncover the spatial contextual dependency between pixels by exploring the correlation between pixels and categories. Meanwhile, the Channel Contextual Module (CCM) is introduced to learn the semantic features including the semantic feature maps and class-specific features by modeling the long-term semantic dependence between channels. The learned semantic features are utilized as the prior knowledge to guide the learning of SCM, which can make SCM obtain more accurate long-range spatial dependency. Finally, to further improve the performance of the learned representations for semantic segmentation, the results of the two context modules are adaptively integrated to achieve better results. Extensive experiments are conducted on four widely-used datasets, i.e., PASCAL-Context, Cityscapes, ADE20K and PASCAL VOC2012. The results demonstrate the superior performance of the proposed CTNet by comparison with several state-of-the-art methods. The source code and models are available at https://github.com/syp2ysy/CTNet.
摘要
语境信息(Contextual information)已经被证明是语义分割的强大工具,本文提出一种基于上下文的串联网络(Context-based Tandem Network ,CTNet),通过对空间上下(spatial contextual)文信息和通道上下文(channel contextual)信息的交互挖掘来发现语义上下文,并用于语义分割。具体来说,空间上下文模块(Spatial Contextual Module, SCM)通过探索像素和类别之间的相关性来解释像素之间的空间上下文模块(Channel Contextual Module,CCM)。通过对通道之间的长期语义依赖关系建模,学习通道的语义特征,包括语义特征图和类的特征。利用学习到的语义特征作为先验知识来指导SCM,这个方法可以使得SCM获得更多准确的远程空间依赖(long-range spatial dependency)。最后为了进一步提高学习后的语义分割表征的性能,本文对两个上下文模块的结果进行自适应集成以获得更好的结果。
Introduction

语义分割的主要挑战来自于很难准确区分一些外观相似的令人迷惑的类别(confusing categories)
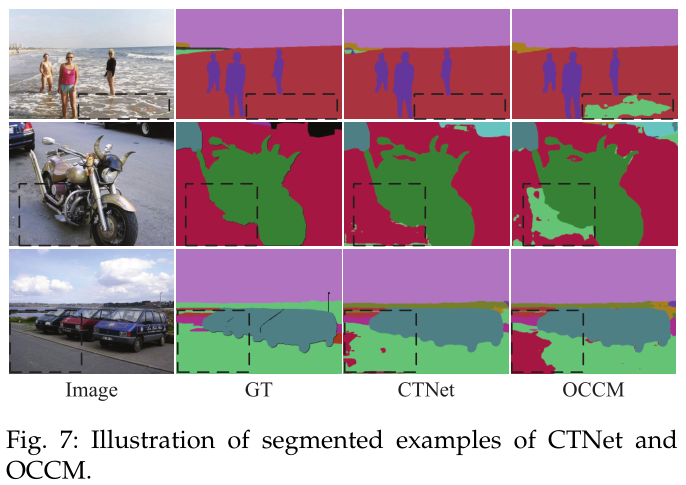
比如上图第一行中的椅子对象,他和沙发对象的颜色十分相近,还有第三行中水的区域和背景的区域,在形状和颜色上十分相近。只凭外观是很难区分这些区域的,因此语义信息被广泛用于改进分割的性能。
每个通道的特征图对应一个特定的语义表征,不同的语义表征是相互关联的。
CTNet发现通道的高级特征图中编码的丰富语义信息,以知道空间依赖性的学习。它可以保证所提出的CTNet同时捕获像素之间的空间上下文依赖关系和通道之间的语义依赖关系。
在CCM中,由于不同尺度的局部通道上下文信息(contextual information of local channels)是互补的,因此提出了多局部通道激励块(Multi-local Channel Excitation, MCE),通过学习多局部通道特征图之间的语义依赖关系来探索通道的上下文。此外还提出了一种新的类概率损失来规范训练,使网络能够更好地捕捉信道上下文并准确预测图像中类的概率。在uncovered channel context中,CCM通过月类别出现在图中的概率,为每个类别生成一个语义表示向量(称为类别向量,class feature),并通过更新每个通道特征图,生成一个新的特征图(称为中间特征, middle feature).
在SCM中,提出了一种新的自注意机制来捕获空间上下文。通过中间特征和类别特征学习所有像素之间的全局依赖关系,并根据像素和类别之间的相关性聚合类别特征更新特征。实际上,CCM学习到的特征可以作为先验知识来指导SCM学习,这样可以提高SCM学习到的特征。
因此CCM和SCM是相互训练的,而不是独立训练的,最后,将CCM和SCM学习到的特征自适应融合,进行语义分割。CTNet可以通过交互地考虑空间和通道关系来发现完全的长依赖关系。
本文的主要贡献
- 本文提出了一种基于情景的串联网络(Context-based Tandem Network, CTNet),通过交互研究像素之间的空间语境依赖和通道之间的语义依赖关系。长期语义依赖和空间依赖的联合学习可以显著提高语义分割的期望特征。据说,这是第一个利用空间语境和通道语境进行语义分割的研究。
- 通道上下文模块(CCM)利用MCE块和类概率损失来探索多尺度的局部通道上下文,确保通道上下文能够包含所有类别并反应不同类别之间的差异。
- 提出了一种新的自注意力机制,通过研究像素和类别之间的相关性来建立全局空间依赖模型,在保证吸能的同时降低了计算复杂度。
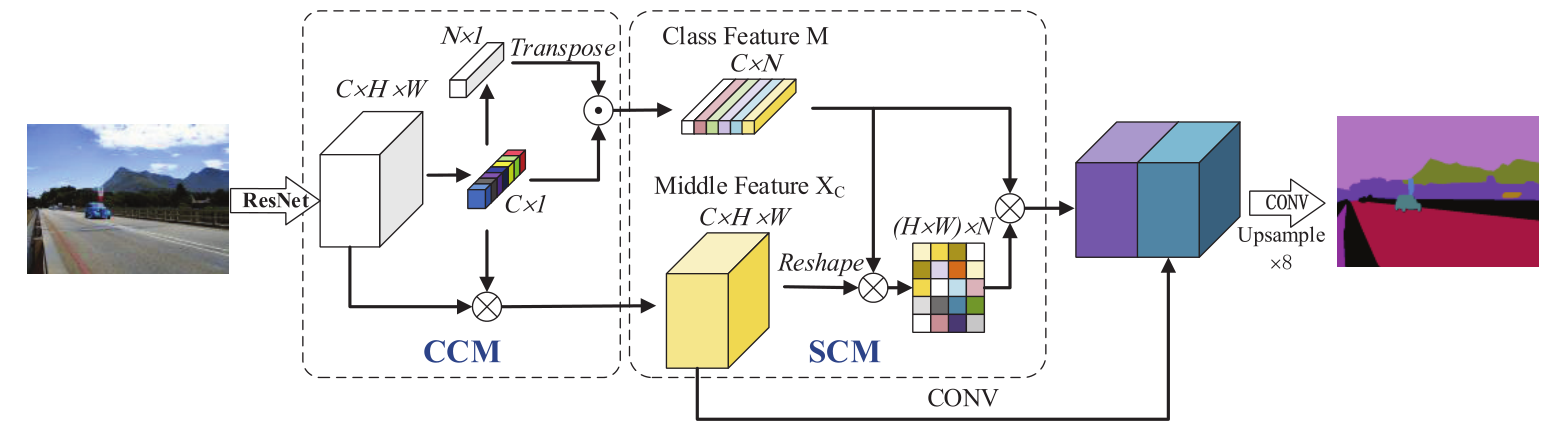
Proposed Approach
总览(overview)
如上图所示,CCM被提出用于学习可以表示每个通道重要性的通道上下文向量(channel context vector)。将原始特征与通道上下文向量相乘,获得一个新的特征图,这个特征图被称为中间特征(Middle Feature)。此外,通道上下文向量包含丰富的语义信息,因为每个通道的特征图对应特定的语义表征。因此,通过使用通道上下文映射来预测每个类别出现在图像中的概率。CCM通过将这个概率与通道上下文向量相乘来学习每个类别的特定类别表征(class-specific feature representation)。将学习到的中间特征和类特征作为SCM的输入,他们可以作为知道SCM学习的先验知识。
为了探索长期空间环境,SCM引入了一种新的自注意力模型。对像素与类别之间的空间关系进行建模,利用类特征进行聚合,得到长期依赖关系的特征表示。CCM和SCM之间的通信可以使他们相互兼容,最后将这两个模块的特征图进行集成,生成更好的特征表示。最后通过引入最后的卷积层和一系列上采样操作得到分割的结果。
CCM Module
在高级特征图中,每个通道的特征图,对应一个特定的语义表征(semantic response)。使用通道上下文,即通道之间的依赖关系,可以改进特定的语义表征,并重新校准特征映射。现有方法通过设计不同的结构来提取通道上下文(channel context)如下图所示:
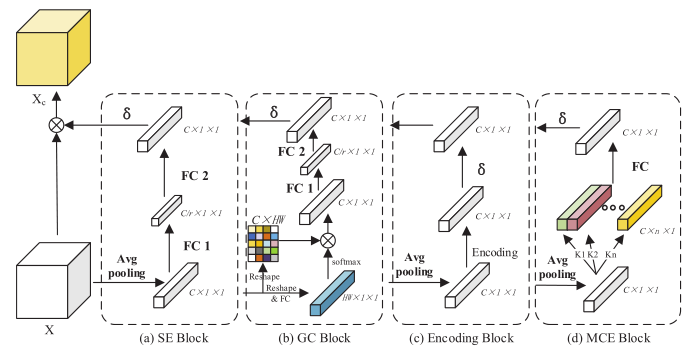
SE block,GC block,Encoding block通过获取全局通道交互信息来提高模型的表示能力。然而,由于每个通道仅与其相邻通道密切相关,因此这些交互信息是冗余的。
因此,通过融合多尺度本地通道上下文,提出了多本地通道激励块(Multi-local Channel Excitation, MCE),其中不同尺度代表与当前信道相关联的不同数目的相邻信道。MCE模块的结构如图中d所示。
对给定的输入特征图,采用全局池化操作将每个二维特征通道变为实数,该实数具有一定的全局感受野(global receptive field)。也就是说,可以得到一个粗略的全局信息,他可以表示在特定通道上的全局分布相应(represents the global distribution of responses on the characteristic channel)。MCE block引入一维卷积从粗略的全局信息中捕获局部信道上下文。
为了获取更全面的信道上下文信息,MCE块首先采用多个具有不同核的一维卷积来探索不同尺度的本地通道上下文,然后将其聚合到多尺度本本地通道上下文特征图。
其中是一维卷积的数量,表示链接操作,是使用作为卷积核的一维卷积。MEC block采用全连接层从聚合通道特征图中提取最终的通道上下文。
其中表示激活函数,和表示参数矩阵和全连接层的偏置向量。
CCM是在MCE block的基础上开发的,用于更新含有通道上下文的特征图的表征,并且获得图像的类特征。如下图所示
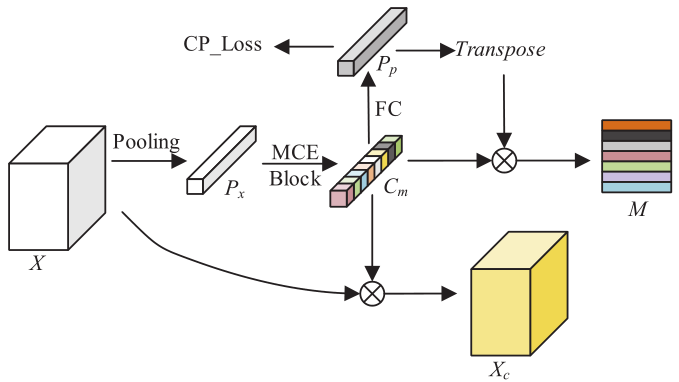
通过将和原始的特征图进行通道维度的乘法生成一个叫做中间特征的新特征图。
其中表示通道维度的乘法。
高层特征往往会丢失图像中下目标的信息,这给语义分割任务识别小目标带来了困难。同时,为了得到类别特征图,CMM需要了解每幅图像中类别之间的差异。为此,提出了一种新的损失函数(类别概率损失,Class Probability Loss, CP-Loss)。通过使CCM预测图像中目标类别出现的概率来实现训练的正则化,CP-Loss的定义方式如下:
其中表示预测类别的概率,是目标概率,是当前batch的权重,通过参数为全连接层从中学习到的,其中是数据集中所有类别的数量。实际上,图像中没有出现关于的对象类别的目标的概率的信息。因此是居于ground-truth标注计算的。图像中第i类的目标概率由获得,其中是属于当前图像中第j类的像素出现的频率。CP-Loss保证了通道上下文不仅可以包含图像中所有类别,还可以包含图像中所有类别的出现概率。
基于通道上下文和每个类别的概率,有图像中所有对象特征向量组成的类特征矩阵可以通过下面的方式获得。
其中表示叉积,中间特征图和类别特征图是SCM模块的输入。CCM提供的特征图可以作为先验知识来指导SCM的学习,可以改善SCM学习的特点。同时,类特征矩阵为图像中的每个类别提供了独立的特征表示,这有助于SCM更简洁地捕捉空间上下文。
SCM Module
为了提高分割性能,需要获取空间维度上的长期依赖上下文信息。本文提出了一种基于自注意力的方法,通过扩大模型的感受野来捕获全局空间上下文。这些方法通过计算特征图中每个像素之间的相关性来捕捉图像的长期依赖性,这占用了大量的计算资源。因此在SCM模块中提出了一种新的解决方案,如下图所示。提出的SCM模块通过计算特征图和图像的高级语义表征之间的相关性来探索空间上下文。
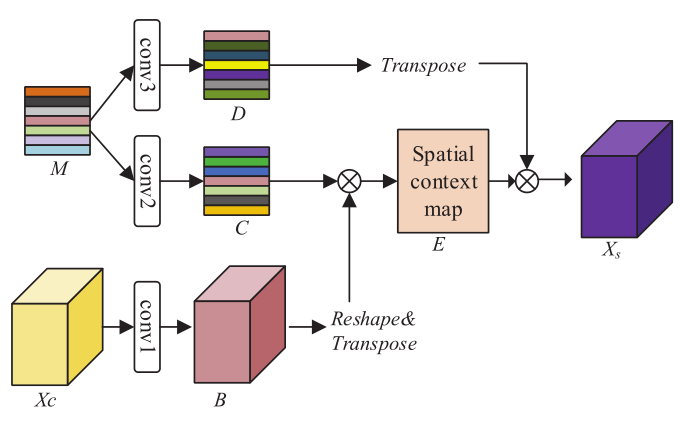
为了在不影响性能的情况下,有效地降低计算复杂度,SCM将空间上下文的学习问题转化为特征图上每个像素类别的匹配问题,然后利用像素与类别之间的相关性来描述全局上下文。为了使空间上下文和通道上下文信息具有交互性,将空间特征映射和类别特征表示矩阵输入到SCM模块中。首先,利用卷积层进一步降低运算量,在和的基础上分别得到两个新的特征表示和,其中s为减少比(reduction ratio),然后被reshape为。
通过使用Softmax层获得空间上下文映射(Spatial context map),对于Softmax的极值问题,传统的减去最大值的方法是通过以下工作来实现的。
其中是第i个像素和第j个语义类别之间的相关分数。是超参数,根据之前的工作,超参数设置为。他不仅获取像素与类别之间的匹配关系,并且将具有相同匹配关系的像素进行聚合,间接获得像素之间的相关性。
为了增加模型的表示空间,将输入到一个新的卷积图层中,生成一个新的类特征图。
截下来,使用类特征表示矩阵和空间上下文映射重新校准像素特征表示,以进一步提高像素的特征表示。具体来说,我们通过卷积层获得随空间上下文功能更新的特征图。
其中表示由组成的转换函数。它可以推断每个位置的是跨越空间上下文矩阵和类别特征矩阵的特征的加权和。因此,相似的意义特征通过类别特征矩阵实现互惠互利。当特征图是时,SCM块的计算复杂度是,而non-local块的计算复杂度是,其中。也就是说,SCM块不仅可以解决non-local block的问题,而且为描述空间上下文提供了一种新的方向。
损失函数(Loss Function)
为了充分利用这两个维度的上下文,将两个模块的特征图进行了集成。将CCM生成的中间特征送入卷积层进行特征提取。然后将提取的特征与SCM模块生成的特征图进行连接。引入卷积层对连接后的特征图进行整合,生成最终的特征图。分割结果是通过双线性插值将最终的特征图上采样到原始图像大小得到的。为了评价分割性能,通过测量分割结果与ground-truth数据之间的差异,引入了分割损失。
为了增强网络的表示能力,我们引入了辅助监督来提高分割的性能。根据之前的工作,在ResNet的第四阶段之后通过额外的FCN头添加辅助损失,此外还将改进的CP-Loss引入到受限(restrict)网络训练.
为了共同探讨上述术语,所提出的CTNet的最终目标函数包含分段损失,和辅助损失以及CP-loss,其可用下面的公式表示
和分别是对应与负数损失和CP-loss的折中参数(trade-off parameters)。在之前的工作中,辅助损失是唯一的附加损失,并且附加损失的权重被重置为0.4。在此设置之后,被设置为的实验中的默认值。
实验部分
使用的数据集
PASCAL-Context,Cityscapes,ADE20K和PASCAL VOC2021。
在前人工作的基础上,通过将原始图像调整到不同的尺度来采用多尺度(MS)测试。缩放后的图像被调整到训练图像的大小,并馈送到网络中,最终结果通过多个尺度上的网络预测进行平均得到,为了评价语义图像分割方法的性能,引入了广泛使用MIOU度量,此外,在消融研究中,使用Miou和PixAcc度量。
实施细节
网络
实验系统基于Pytorch和PaddlePaddle。利用ImageNet预先训练的ResNet和HRNetV2作为CTNet的主干。CTNet在消融研究中使用ResNet-50作为主干以加快实验速度,在其他实验中使用ResNet-101或HRNetV2作为主干。为了解决膨胀卷积带来的内存消耗问题,提高分割效率,我们使用JPU模块代替膨胀卷积策略来表征特征图为输入图像的,同时,使用同步的BN训练CTNet。
训练
采用SGD方法对网络进行优化,动量设置为0.9,权重衰减设置为0.0001,采用多元学习策略,将初始学习率乘以其中。
Cityscapes:初始学习率为0.01,设置400个epoch,8 batch size
ADE20K:初始学习率为0.05,300个epoch,16 batch size
PASCAL-Context and PASCAL VOC2012 :初始学习率设置为0.001,250个epoch,16 batch size
对于数据增强,只在[0.5,2]范围内随机翻转和缩放图像,然后在[-10,10]之间随机旋转图像,最后再必要时使用0填充将图像固定到统一大小。
CTNet在RTX 3090 GPU上训练,每个GPU具有24GB的内存。
消融实验
For CCM
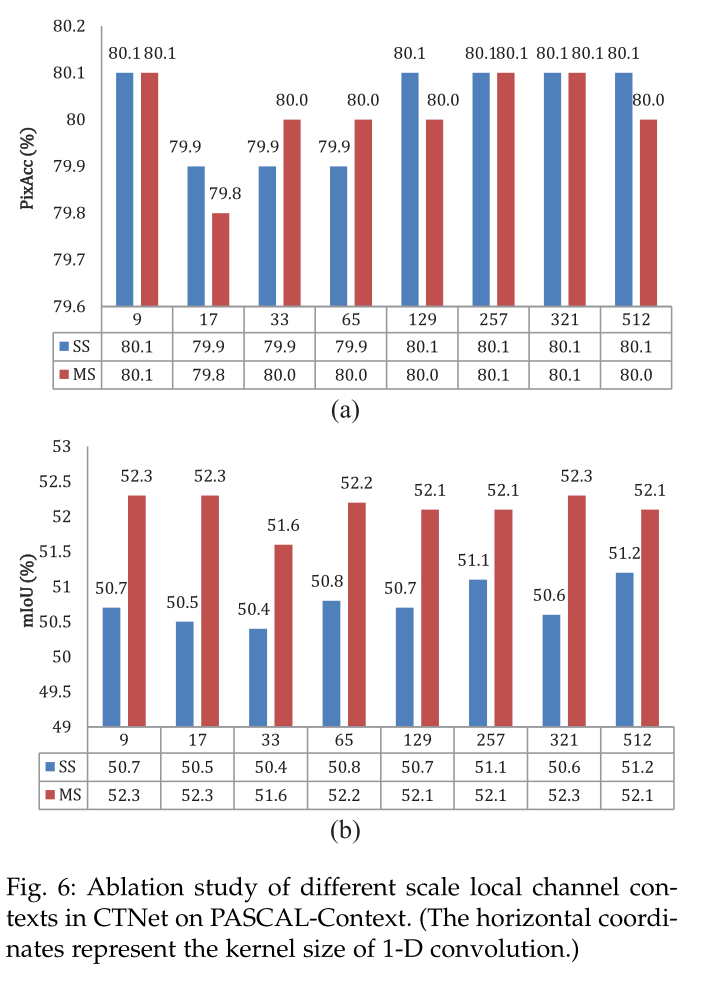
通过用一维卷积替换CCM模块中的MEC块,在内调整卷积核k的大小。值得注意的是,特征图的通道数是512。也就是说,当K=512时的情况对应与全局信道上下文。此外,还黑出了使用多尺度测试(MS)和单尺度测试(SS,直接将原始图像送入网络)的结果。
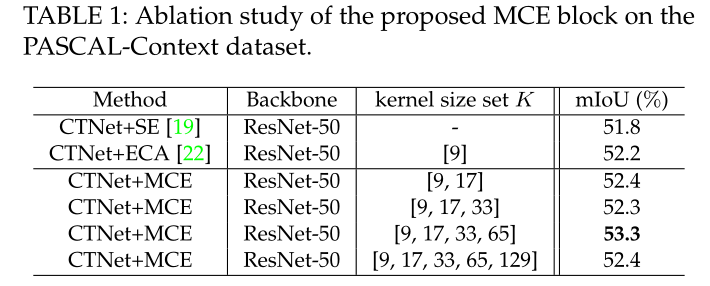
MCE块与ECA块和SE块进行对比
验证CCM提取的特征是否包含特征映射中的重要信息,对全局池化策略的性能进行了评估。
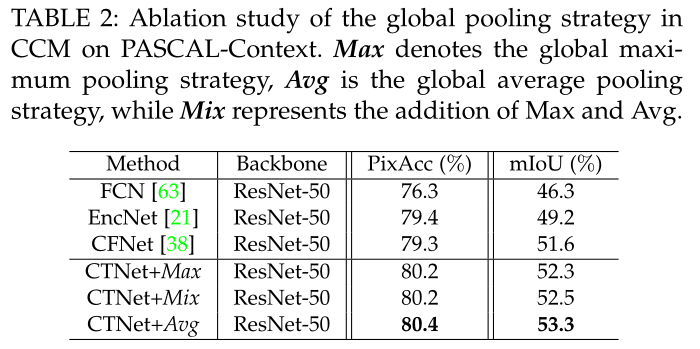
采用全局平均池化策略的CTNet在以ResNet-50为骨干的Pascal-Context数据集上取得了最好的结果,准确率为80.4%,MIOU为53.3%,说明全局平均池化是提取通道间对分类目标响应度的最准确方法。因此,在实验中使用了全局平均池化策略。
For SCM
为了降低自我注意带来的计算开销,提出了一种基于新的自我注意机制的SCM模块,利用像素与类别之间的关系来描述全局空间上下文。
对比主流结构
验证SCM模块中使用单个卷积层产生C和D的有效性,通过比较使用相同层和使用不同层的两种不同方法进行了实验。
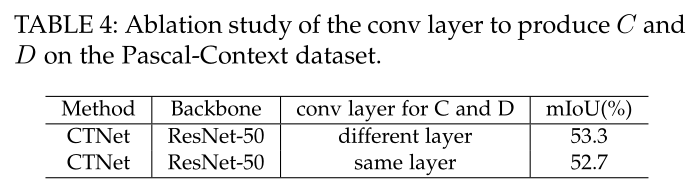
从结果可以看出,使用不同的卷积层比使用相同的卷积层的性能要好,这表明使用不同的卷积层可以提高系统的性能。
验证公式8中,softmax超参数的有效性

验证SCM模块的有效性
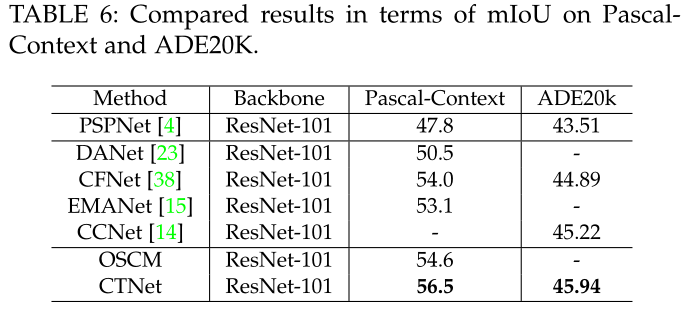
For single module and connection mode
为了更好地体现CTNet中CCM和SCM模块对语义分割的重要性,设计了CTNet的简化版本OCCM和OSCM。通过从CTNet中删除SCM模块,OCCM仅使用CCM模块作为分段报头。OCCM、OSCM和CTNet的定量比较如下表所示
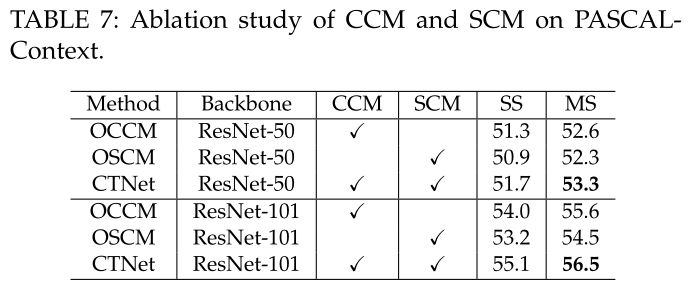

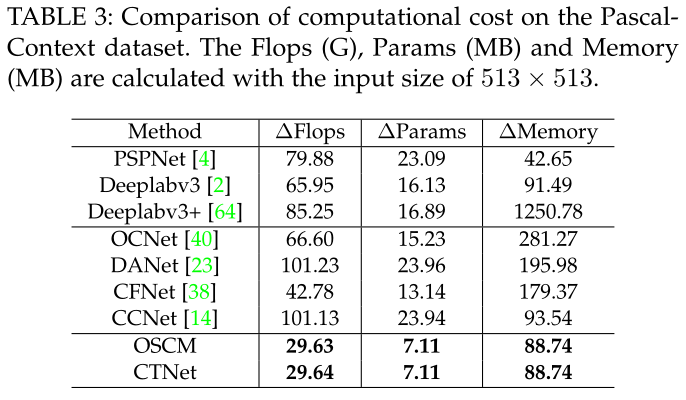
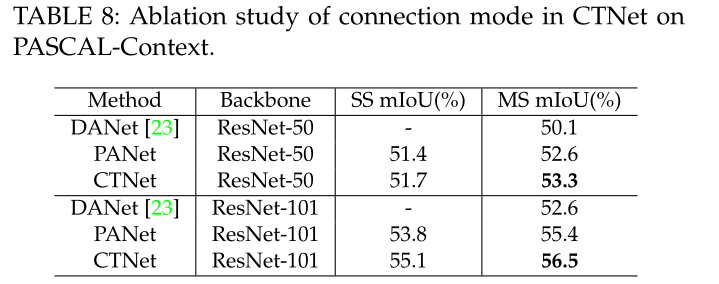
实际上,有不同的连接模式可以同时探索频道和空间语境。现在正在进行实验,以评估连接方式的有效性。有两种方式可以连接两个独立的模块。也就是说,一个是串联的,另一个是并行的。因此,将所提出的串联连接模型与DANet中使用的并行连接模型进行了比较。量化结果下表。
 ++ ————–
++ ————–






