「论文阅读」Instance and Panoptic Segmentation Using Conditional Convolutions
Instance and Panoptic Segmentation Using Conditional Convolutions
论文名称:Instance and Panoptic Segmentation Using Conditional Convolutions
作者:Zhi Tian; Bowen Zhang; Hao Chen; Chunhua Shen
期刊: IEEE Transactions on Pattern Analysis and Machine Intelligence
时间:2022
原文摘要
We propose a simple yet effective framework for instance and panoptic segmentation, termed CondInst (conditional convolutions for instance and panoptic segmentation). In the literature, top-performing instance segmentation methods typically follow
the paradigm of Mask R-CNN and rely on ROI operations (typically ROIAlign) to attend to each instance. In contrast, we propose to attend to the instances with dynamic conditional convolutions. Instead of using instance-wise ROIs as inputs to the instance mask head offixed weights, we design dynamic instance-aware mask heads, conditioned on the instances to be predicted. CondInst enjoys three advantages: 1) Instance and panoptic segmentation are unified into a fully convolutional network, eliminating the need for ROI cropping and feature alignment. 2) The elimination of the ROI cropping also significantly improves the output instance mask resolution. 3) Due to the much improved capacity of dynamically-generated conditional convolutions, the mask head can be very compact (e.g., 3 conv. layers, each having only 8 channels), leading to significantly faster inference time per instance and making the overall inference time less relevant to the number of instances. We demonstrate a simpler method that can achieve improved accuracy and inference speed on both instance and panoptic segmentation tasks. On the COCO dataset, we outperform a few state-of-the-art methods. We hope that CondInst can be a strong baseline for instance and panoptic segmentation. Code is available at: https://git.io/AdelaiDet
Abstract
本文提出CondInst(条件卷积实例和全景分割)。其有3个优点
- 实例分割和全景分割统一为一个完整的全卷积网络,无须ROI拆件和特征对齐
- 消除ROI裁剪还显著提高了输出实例掩码的分辨率
- 由于动态生成的条件卷积容量大大提高,掩码头可以非常紧凑(比如三个卷积层,每层只有8个通道),使得每个实例的推理时间明显更快,并且使得总推理时间与实例数量的相关性较小。
本文展示了一种更简单的方法,它可以在实例和全景分割任务中获得更高的准确率和推理速度,在coco数据集上,本文的性能由于一些sota的方法。
Introduction
实例分割是计算机视觉中的一项基本而又具有挑战性的任务,他需要一种算法来预测图像中每个感兴趣的实例的每个像素的Mask和类别标签。
全景分割还需要算法来分割物体(例如:天空和草地),为图线中的每个像素分配一个语义标签。全景分割通常建立在具有额外语义分割分支的实例分割框架上。因此,实例分割和全景分割都面临着相同的关键挑战——如何高效有效地区分各个实例。
尽管最近提出了一些工作,但解决这一挑战的主要方法仍然是两阶段的方法,如Mask R-CNN,该方法将实例分割分为两阶段检测和分割任务。具体地说,Mask R-CNN首先使用一个更快的目标检测器R-CNN来预测每个实例的bouding-box。然后,对于每个实例,使用ROIAlign操作从网络的特征图中裁剪注意区域(ROI)。为了预测每个实例的最终掩码,将紧凑的全卷积网络(FCN,即掩码头)应用于这些ROI一执行前景背景分割。
但这些基于ROI的方法可能有以下的缺点
- 由于ROI通常是轴对齐的边界框,对于不规则形状的对象,他们可能包含大量无关的图像内容,包括背景和其他实例。这个问题可以通过使用旋转的ROI来缓解,但代表是更复杂的管道。
- 为了区分前景实例和具有固定掩码头的背景材料或实例,掩码头需要强大的容量和相对较大的接受场来编码足够大的上下文信息。其结果就是在掩码头中使用3x3卷积进行堆叠。这大大增加了掩码头部的计算复杂度。导致推理时间随实例数的变化而显著变化。
- ROI通常具有不同的大小。为了在现代深度学习框架中使用有效的批处理计算,通常需要调整大小操作以将裁剪区调整为相同大小的块。例如在Mask R-CNN将所有裁剪区域的大小调整为14x14(通过是哟经28x28的deconvolution进行上采样),这限制了实例分割的输出分辨率,因为大型实例需要更高的分辨率才能在边界保留细节。
FCN在语义分割以及其他的视觉任务上都有较好的表现,但是在实例分割任务上远不如基于ROI的方法,其原因是:FCN往往对相似的图像外观产生类似的预测,因此,普通的FCN无法区分单个实例
比如
输入图像中有两个外观相似的人A和B
在预测A的实例掩码时,FCN需要将B预测为背景。
这个任务时非常困难,因为A和B看齐来十分相似
因此:ROI操作用于裁剪关注区域的人,即A,并过滤掉B
本质上,这是使模型关注实例的核心操作
在本文的工作中,提出了一种新的新的实例分割解决方案,CondInst。该方法不是用ROI,而是过使用实例敏感的卷积过滤器以及附加到特征图的相对坐标来关注每个实例。
受到动态滤波网络和CondConv的启发,对于每个实例,使用一个控制子网络东他死生成掩码的过滤器(这个过滤器取决于实例的中心区域)。网络的参数可以编码这个实例的特征(比如,相对位置,形状和外观)并且只对这个实例的像素点火(原文:only fires on the pixels of this instance),从而绕过了标准FCNs中的困难。这些条件掩码头应用于整个高分辨率的特征图上,从而消除了ROI的需要。这种方式,看起来对于图像中多达数十个实例的话,就会引入大量的网络参数,但是,由于掩码头过滤器只被要求预测一个实例的掩码,他在很大程度上降低了学习要求,从而减少了过滤器的负载。因此,掩码头可以设计得非常轻量。本文将展示一个非常紧凑(compact)的掩码头与动态生成的过滤器可以超过以前的ROI-Base的Mask R-CNN。这种紧凑的掩码头也使得掩码头的计算复杂度远低于Mask R-CNN的掩码头。
本文的主要贡献如下:
- 本文试图从一个新的角度(使用动态掩码头)解决实例分割任务,该方法比现有的方法(如Mask R-CNN)获得了更好的实例分割性能。这是第一次新的实例分割框架在精准度和速度方面由于SOTA。
- CondInst是全卷积的结构,并避免了前面提到的在许多现有方法中使用的大小调整操作,因为CondInst不依赖ROI操作,无需调整特征图的大小,就可以得到具有更精准边缘的高分辨率的实例掩码。
- 由于CondInst中的掩码头非常紧凑和轻量,与box检测器FCOS相比,CondInst只需要增加10%的计算时间(小于5ms)就可以获得所有实例的掩码结果,即使处理每张图像的最大数量(比如图上有100个实例)也是如此。因此,总体推断时间是稳定的,因为他几乎不依赖于图像中的数量。
- 使用额外的语义分割分支,CondInst可以很容易地拓展到全景分割,从而为实例分割和全景分割任务建立统一的全卷积神经网络。
- CondInst在实例和全景分割任务上都达到了SOTA的性能,同时又快速简单。本文希望CondInst能够称为实例和全景分割任务以及其他实例级识别任务(如关键点检测)的一个新的强大代替方案。
Related Work
条件卷积和动态过滤器(Conditional Convolutions/Dynamic filters)
传统卷积层具有经过训练的固定过滤器,而条件卷积的过滤器事宜输入为天剑,由另一个网络(控制器)动态生成的。
dynamic filter network和CondConv主要是增加了分类网络的容量
DGMN采用动态过滤器去生成特定点过滤器作为信息计算,从而提高了网络的容量,从而获得了更好的性能。
本文根据每个实例生成掩码头过滤器,并提出了一种不需要ROIs的高性能实例分割算法。
实例分割(Instance Segmentation)
迄今为止,Mask R-CNN仍然是实例分割的主流框架,其采用目标检测器去检测实例的边界框,使用这些边界框可以使用ROI操作从特征映射中裁剪实例的特征,最后,使用一个FCN头来获得所需要的实例掩码。
但是一些FCNs作为实例分割的任务也有了一定的研究。
- InstanceFCN可能是第一种全卷积的分割方法,其提出用普通的FCNs预测位置敏感的评分图(position-sensitive score maps),然后将这些评分图组合起来,以获得所需的实例掩码。但InstanceFCN不能很好地处理重叠实例。
其他的方法则是尝试执行图像分割,然后通过聚合同一实例的像素来形成所需的实例掩码。
- Deep Watershed模型利用经典的watershed transform进行实例分割,对象实例可以看做是图像watershed transform能量图中的能量流域。
- SGN使用一系列网络将原始像素逐渐分组为线段,链接组间,最后是对象实例,实现了令人印象深刻的新能。
- single-shot Box2Pix 以自底向上的方式解决了实例分割
- Novotny提出了半卷积算子(semi-convolutional operators),使得FCNs适用实例分割。
- Arnab提出动态实例CRF(Dynamically Instantiated Conditional Random Field)用于实例分割,他能够为每个图像生成一个可变的数量。
但以上方法,都不能同时在准确度和速度上有超出Mask R-CNN的表现,在COCO benchmark数据集上。
最近的YOLACT和BlendMask可以看做是Mask R-CNN的重新设计,他解耦了用于掩码预测的ROI检测和特征图。
简单的FCN based的实例分割方法,该方法根据实例的位置对实例进行分段,显示出具有竞争力的性能。
PolarMask卡发了一种新的掩码表示,他拓展了bounding box检测器FCOS
全景分割(Panoptic Segmentation)
解决这个问题主要有两个方法,第一种是自下而上的方法。他首先以语义分割的方式处理这个任务,然后使用聚类、分组的方法将像素聚合成单独的实例或物品。有的研究人员探索了弱视或半监督全景分割(weakly- or semi-supervised panoptic segmentation)。
第二种是自顶向下的方法,他们通常构建在自顶向下的实例分割方法上。
- Panoptic-FPN 从Mask R-CNN拓展了一个额外的语义分割分支,并将结果与Mask R-CNN生成的实例分割结果结合起来。
- Axial DeepLab使用了一个进行设计的模块,使人们能够注意到大幅度的图像进行全景分割。
根据自顶向下的方法,CondInst可以很容易地应用于全景分割。
Method
实例分割的整体架构(Overall Architecture for Instance Segmentation)
语义分割的输出可以很容易地用FCN的输出特征映射来表示,并且输出特征映射的每个通道对应一个类别,然而,在实例分割中每个像素的预测目标很难定义,因为实例分割还需要区分单独的实例,但是实例的数量在不同的图像中是变化的。当传统的FCN应用与实例分割时,这构成了一个重大挑战。
在本文的工作中,其核心思想是对于K个实例的图像,动态生成K个不同的掩码头,每个掩码头在其过滤器中包含其目标实例的特征。因此,当掩码应用于输入时,它只会在实例的像素上触发,从而产生实例的mask预测并区分各个实例,下图表述了这一过程。
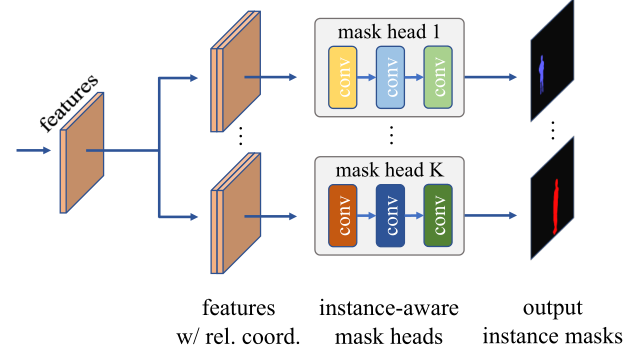
实例感知过滤器通过修改对象检测器来生成。具体地说。本文添加了一个新的控制分支来为目标实例的每个由检测器产生的预测框生成过滤器,其过程如下图所示。
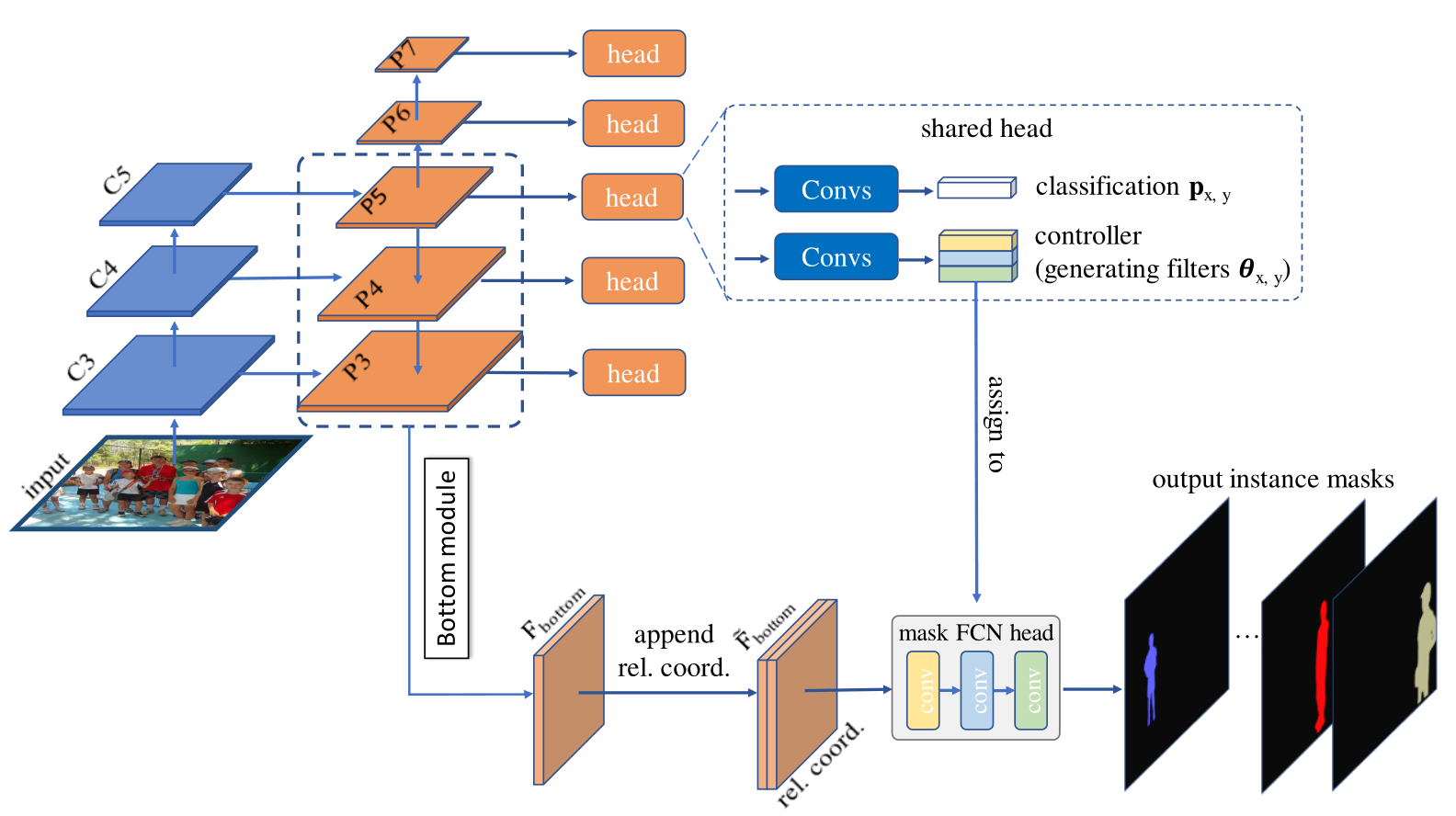
图像描述:
C3,C4,C5是由主干网络生成的特征图(ResNet-50)。
P3~P7是FPN特征图
是底部分支的输出,其分辨率与P3相同,底部分支聚合了P3,P4,P5
通过相对坐标连接到得到的
分类头预测目标实例在(x,y)位置上的类别可能性与FCOS相同
控制器为实例生成掩码头的过滤器参数
与FCOS类似,控制器还具有中心度(center-ness)和盒头(box heads)
虚线框中的头部多次应用于P3~P7中,掩码头是instance-aware的,其被用在的次数与图像中实例的数量相同
因此动态掩码头的数量与预测框的数量相同,如果detector工作良好,则预测框的数量应该是图像中的实例数量。在这项工作中,由于其简单性和灵活性,本文在流行的目标检测器FCOS构建了CondInst。此外,在FCOS中取消anchor-boxes还可以节省参数量和计算量。
本文使用特征金字塔的特征图,他们的下采样率分别为8,16,32,64,128。在FPN的每个级别特征上,应用了一些功能层(在虚线框中)用来进行实例感知预测(instance-aware predictions)。例如,目标实例的类别和该实例动态生成的过滤器。CondInst可以被视为与Mask R-CNN相同,两者都首先关注图像中的实例,然后预测实例的像素级掩码(实例优先)。
Mask R-CNN是以bounding-box表示实例,CondInst使用实例感知过滤器来表示实例,也就是说,CondInst使用生成的动态过滤器的参数隐式地编码实例信息,而不是使用bounding-box编码实例信息,这是非常灵活的。动态过滤器可以很容易地表示难以被边界框紧紧包围的不规则形状。这是CondInst对于以前基于ROI的方法的优势之一
除了检测器,还有一个底部分支,他提供生成的掩码头部作为输入以预测所需实例掩码的特征图。底部分支聚合FPN的特征图。使用双线性插值的方式上采样到相同的分辨率并加到上。之后,应用4个卷积,128个通道,得到的特征图的分辨率与相同(即输入图像分辨率的)。最后,使用另一个卷积层将输出通道的数量从128个减少到8个,从而产生底部特征图。较小的输出通道减少了生成参数的数量。根据实验发现当时可以获得良好的性能。这可能是因为本文的掩码头部只预测相对简单的与这类无关的实例掩码,而实例的大部分信息已经在动态生成的筛选器中进行了编码,这使得对性能不是很敏感。
CNN产生的特征图通常不传递位置信息,因此需要将坐标图附加到中,以便生产的过滤器知道实例的位置。过滤器是使用与位置无关的卷积生成的,因此他们只能隐式地使用相对于生成过滤器的位置的坐标对形状和位置进行编码。将特征图与相对坐标进行组合然后发送到掩码头部中,以完全卷积的方式预测实例掩码。在每个实例的预测中使用sigmoid激活函数,只区分前景与背景。
原始掩码预测的分辨率与的分辨率相同,是输入图像分辨率为。为了提高实例掩码的分辨率,本文使用双线性插值对掩码预测进行2次上采样,得到200×256个实例掩码(输入为800*1024)。该掩码的分辨率远高于Mask R-CNN的分辨率。
网络输出与训练目标(Network Outputs and Training Targets)
与FCOS类似,FPN的特征图上的每个位置或者与一个实例相关联,因此是正样本或者被认为是负样本,每个位置的关联实例和标签按如下方式确定。
本文考虑特征图,设置s为下采样率,特征图上的位置映射回原图的坐标是。如果映射的位置落在实例的中心区域,则认为该位置负责该实例。中心区域之外的任何位置都被标记为阴性样本。中心区域被定为,其中表示实例掩码的中心,是的下采样率,是恒定标量1.5。
在的位置上,CondInst具有以下输出头:
-
Classification Head
分类头预测与该位置相关联的实例的类别。ground-truth目标是实例的类别或0(背景)。与FCOS相同,网络预测用于分类的C维度的向量,并且对于的每一个维度都有对应的二元分类器,C是类别的数量。
-
Controller Head
控制头与分类头具有相同的结构,用于为每个实例的位置预测掩码头卷积核的参数。掩码头为这个特定的实例预测掩码。这就是本文的核心贡献。为了预测参数,本文将所有filters的参数连接在一起(权重和偏置)作为一个N维度的向量,其中是参数的总数。因此controller head有N个输出的通道。mask head是一个非常紧凑的FCN结构,他有三个的卷积层,每个卷积层有8个通道,除最后一个外,使用ReLU作为激活函数。这里没有使用归一化,比如BN。最后一层输出1个通道,并使用sigmoid来预测前景的概率。mask head总共有169个参数(以及)。掩码头部预测的掩码由ground truth实例掩码进行监督,这推动控制器生成 correct filters。
-
Box Head
box head 与FCOS相同,预测一个四维的向量,该向量编码从目标实例的位置到四个边界的距离。从概念上讲,CondInst可以消除box head,因为CondInst不需要ROI。
但是,本文注意到,如果本文使用box-based NMS(非极大抑制),推理时间将会被大幅缩短,因为本文只需要为box NMS后的实例计算掩码。
不知道这句说得对不对,原文是:
However,we note that if we make use of box-based NMS, the inference time will be much reduced since we only need to compute the masks for the instances kept after box NMS.
因此,本文仍然在CondInst中预测boxes。预测的boxes只被使用在NMS上不涉及任何的ROI操作。如果使用其他类型的NMS(如 mask NMS)则可以溢出box的预测。这与以前基于ROI的方法有根本的不同,以前的方法中,box的预测是必须的。
-
Center-ness Head
像FCOS,在每一个位置上,本文也预测一个center-ness score。center-ness score描述了该位置偏离目标实例的中心的程度。在推理中,他被用来见底原理中心位置预测的box的权重,因为这些box并不是可靠的。ground-truth的center-ness score可以被定义为:
其中表示该位置到ground-truth 边界的四个方向的距离。本文使用二元交叉熵(BCE)损失函数对center-ness score进行监督。
-
Semantic Branch for Panoptic Segmentation
本文可以通过添加一个新的语义分割分支将CondInst拓展到全景分割上。对于semantic segmentation branch,本文采用Panoptic-FPN中的结构。如下图所示,语义分割分支将FPN的特征图作为输入。将上采样到与相同的分辨率,并将四个特征图连接在一起。的分辨率是输入图像的,这与CondInst预测的实例掩码相同。
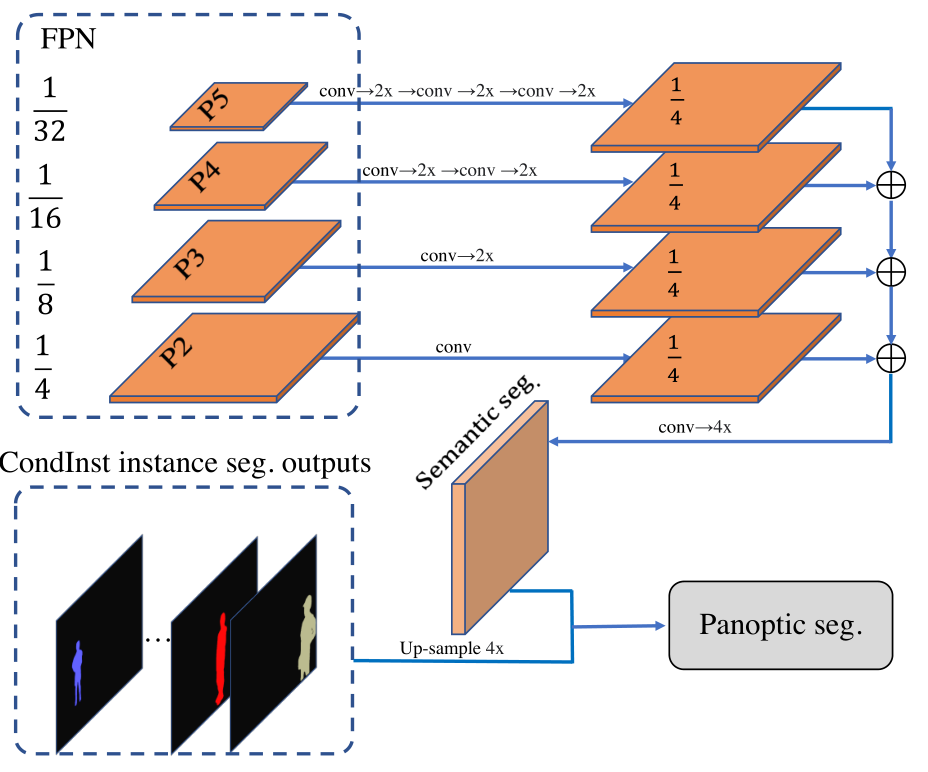
然后使用和掩护个softmax得到语义分割类别的分数。类别分数使用交叉熵损失函数进行训练,在推理中,语义分割结果与实例掩码合并,生成最终的全景分割结果。
损失函数(Loss Function)
最终CondINst全部的损失函数可以用公式表示为:
其中和分别表示FCOS的原始损失函数和实例掩码损失函数。(只被使用在全景分割中)是对全景分割语义分支的损失函数。和分别设置为1和0.5,用于平衡损失值。与FCOS相同,具体来说包括,分类头,box回归头和center-ness头,他们分别使用 focal loss,GIoU loss以及BCE loss。可以使用以下公式表示:
其中是(x,y)位置的分类标签,他是与该位置关联的实例类别或者背景(如果该位置没有和任何实例关联)。是的位置的总数。是indicator function,当时为1否则为0。是(x,y)位置上关联实例的ground-truth的掩码。是动态mask head在(x,y)位置上预测的掩码。其可以表示为如下公式:
其中是在(x,y)位置生成的filters的参数,是和坐标图的结合。是从到(x,y)位置的相对坐标。由一组具有动态参数的卷积构成。
除此之外是Dice Loss,用于客服前景-背景样本不平衡的问题。本文不是用focal loss,因为他需要用先验概率来初始化biases,如果参数是动态生成的,这就不是没有影响的操作了。可以表示为:
其中,表示the element of ,。为了计算预测mask 和ground-truth mask 之间的损失,他们需要resize到相同的大小。如前所述,预测掩码的分辨率是ground-truth掩码的。因此本文将下采样4倍,使得两者大小相等。
推理(Inference)
-
实例分割:
给定一张图像,将其通过网络计算,获得的输出有:分类的置信度,center-ness score,box prediction 以及生成的参数。首先按照FCOS中的步骤获取box检测,然后使用阈值为0.6的box-based NMS来去除重复检测,然后使用前100个box来计算掩码。每个box还与控制器生成的一组filters相关联。假设在NMS之后有个box,因此就会有组生成的filters。这些filters用于产生个特定的实例掩码头。这些特定的实例掩码头以FCNs的方式应用于(即和相对位置的组合),以预测实例的掩码。因为掩码头是一个非常紧凑的网络(有三个卷积,总共有8个通道和169的参数量),计算掩码的开销非常小。
-
全景分割:
对于全景分割,本文将实例和语义结果进行结合以得到全景结果。首先根据FCOS生成的置信度分数对CondInst实例结果进行排序。这些结果中分数低于0.45的都被丢弃。当实例掩码之间发生重叠时,重叠区域将被认为是得分较高的实例。此外没有与其他得分较高的实例重叠而损失总面积超过40%的实例将被丢弃。最后将语义结果填充到未被任何实例占用的区域中。






