论文名称:Multi-Level Feature Learning for Contrastive Multi-View Clustering
作者:Jie Xu, Huayi Tang, Yazhou Ren, Liang Peng, Xiaofeng Zhu, Lifang He
时间:2022
期刊或会议:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
代码:https://github.com/SubmissionsIn/MFLVC
Origin Abstract
Multi-view clustering can explore common semantics from multiple views and has attracted increasing attention. However, existing works punish multiple objectives in the same feature space, where they ignore the conflict between learning consistent common semantics and reconstructing inconsistent view-private information. In this paper, we propose a new framework of multi-level feature learning for contrastive multi-view clustering to address the aforementioned issue. Our method learns different levels of features from the raw features, including low-level features, highlevel features, and semantic labels/features in a fusion-free manner, so that it can effectively achieve the reconstruction objective and the consistency objectives in different feature spaces. Specifically, the reconstruction objective is conducted on the low-level features. Two consistency objectives based on contrastive learning are conducted on the highlevel features and the semantic labels, respectively. They make the high-level features effectively explore the common semantics and the semantic labels achieve the multi-view clustering. As a result, the proposed framework can reduce the adverse influence of view-private information. Extensive experiments on public datasets demonstrate that our method achieves state-of-the-art clustering effectiveness.
Abstract
多视图聚类(Multi-view clustering)能够从多个视图中探索公共的语义信息。现有的工作在同一个特征空间上惩罚(punish)多个目标,其中这些方法忽略了学习一致性的公共语义以及重建不一致的view-private信息之间的冲突。在这篇文章中,提出一个多级特征学习的新框架,用对比多视图聚类(contrastive multi-view clustering)来解决上述的问题。本文的方法通过一种不融合的方法从原始特征(raw feature)中学习不同级别的特征,包括低级特征,高级特征和语义标签/特征,以便于其可以有效地在不同的特征空间中重构目标(reconstruction objective)和一致性目标。具体来说,重构目标是在低级特征产生的。两个基于对比学习的一致性目标分别是在高级特征和语义标签产生的。这使得高级特征有效地探索出公共语义,并使语义标签实现了多视图聚类。结果,这个被提出的框架减少了view-private信息的不利影响。在公共数据集上的大量实验表明,该方法实现了最先进的聚类效果。
Introduction
由于多视图聚类(multi-view clustering, MVC)可以提供公共语义,使得多视图数据或多模态数据正受到越来越多的关注。
MVC的方法可以被粗略的分为:传统的方法和深度学习方法
传统的MVC方法是基于传统机器学习方法进行的聚类任务,可以分为以下三类
子空间方法(subspace)
矩阵分解方法(matrix factorization)
图的方法(graph)
缺点:表示能力不足,较高的计算复杂度
深度学习的MVC方法因为出色的表示能力逐渐成为主流。之前那的深度学习MVC方法可以分为两类:
two-stage method
其重点是从多个试图中分别学习显著性特征,并执行聚类任务
one-stage method
其将特征学习与聚类任务嵌入到一个统一的框架中,以实现端到端的聚类
多视图数据包含两种信息:在所有视图中的通用语义、对每一个独立视图的view-private信息
举个例子:
一段文字和一张图片可以结合来描述公共语义,而文中的不相关上下文和图像中的背景像素对学习公共语义是没有价值的view-private信息。
在多视图学习,学习公共语义和避免无价值的view-private信息误导是一个始终相关的话题。尽管现有的方法已经实现了关键过程,但是他们仍然有一些缺点需要去解决
许多MVC的方法尝试通过融合所有视图的特征来发现潜在的聚类模式(latent cluster patterns)。但与公共语义相比,无价值的view-private信息可能在融合过程中占据主导地位,从而干扰了聚类的质量。
一些MVC的方法利用潜在特征的一致性目标来探索所有视图中的公共语义。但是,他们通常需要在相同的特征上重建目标,以避免繁琐的解决方案。这就导致了一种冲突:一致性目标试图尽可能地在所有视图中学习具有公共语义的特征,而重建目标则希望相同的特征去维护单独视图的view-private信息
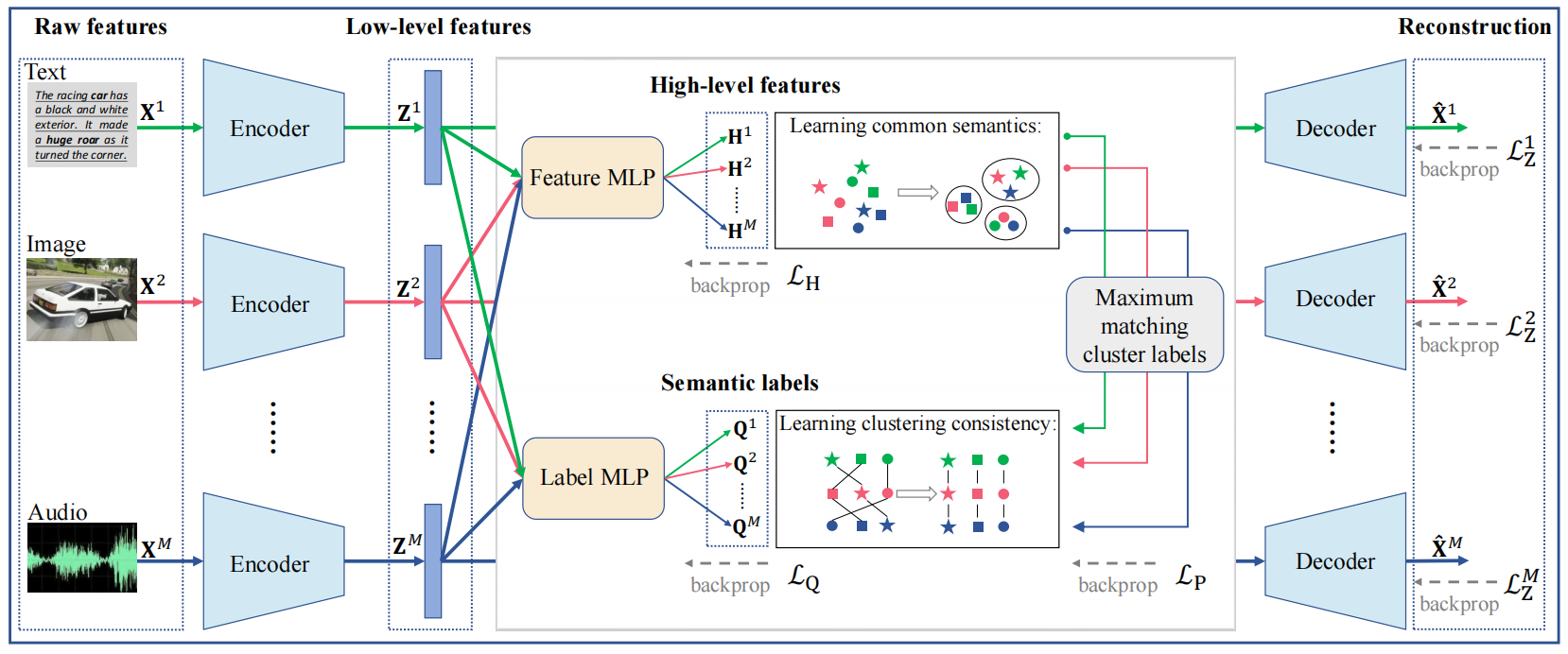
在这篇文章中提出了一个用于对比多视图聚类的新框架MFLVC,来解决之前提到的问题,结构如下图所示:
图1:
MFLVC的结构,在多级学习中,作者避免了直接特征融合,而是学习低级特征Z m Z^m Z m H m H^m H m X m X^m X m Q m Q^m Q m L Z m L_Z^m L Z m Z m Z^m Z m L H L_H L H L Q L_Q L Q { H m } m = 1 M \{H^m\}_{m=1}^M { H m } m = 1 M { Q m } m = 1 M \{Q^m\}_{m=1}^M { Q m } m = 1 M L p L_p L p { H m } m = 1 M \{H^m\}_{m=1}^M { H m } m = 1 M { Q m } m = 1 M \{Q^m\}_{m=1}^M { Q m } m = 1 M
目标:
设计一个fusion-free的MVC模型,以避免所有的视图中view-primate信息的融合。
为每个视图中的样本生成不同级别的特征,包括低级特征,高级特征和语义标签/特征。
首先利用一个自动编码器去从原始特征汇总学习低级特征,然后在低级特征上使用堆叠的两个MLP去得到高级特征和语义标签,每个MLP共享所有的视图,并有利于过滤view-private信息。此外,将语义标签作为anchors,其在高级特征中结合了语义标签,从而促进了聚类效果。
重构目标通过低级特征实现,两个一致性目标分别通过高级特征和语义标签实现。这两个一致性目标是由对比学习引导的,这使得高级特征更加关注挖掘所有视图中的一致性信息,也使得语义标签表一致性聚类并用于多视图聚类中。
贡献:
设计了一个fusion-free的MVC方法去引导不同特征空间的不同目标去解决重建目标和一致性目标的冲突。这个方法有效地探索所有视同的公共语义,避免了无意义的view-private信息。
可以用于同时实现高级特征和语义标签的一致性目标
由于良好的框架设计,这个方法对超参数的设置也具有鲁棒性
Contrastive learning:
对比学习是一种注意力获取的无监督表示学习方法,思想是在一个特征空间中,最大化相似的正样本对,最小化负样本对。
Method
原始特征 (raw feature):多视图数据集{ X m ∈ R N × D m } m = 1 M \left\{\mathbf{X}^{m} \in \mathbb{R}^{N \times D_{m}}\right\}_{m=1}^{M} { X m ∈ R N × D m } m = 1 M x i m ∈ R D m \mathbf{x}_{i}^{m} \in \mathbb{R}^{D_{m}} x i m ∈ R D m D m D_m D m
Motivation
多视图通常有冗余和随机噪声,主流方法一直从原始特征中学习显著性表征。自编码器是一个广泛被使用的无监督模型,他可以将一个原始特征建模到可定制的特征空间中。具体来说,对第m个视图,E m ( X m ; θ m ) E^m(X^m;\theta^m) E m ( X m ; θ m ) D m ( Z m ; ϕ m ) D^m(Z^m;\phi^{m}) D m ( Z m ; ϕ m ) θ m \theta^m θ m ϕ m \phi^m ϕ m z i m = E m ( x i m ) ∈ R L \mathbf{z}_{i}^{m}=E^{m}\left(\mathbf{x}_{i}^{m}\right) \in \mathbb{R}^{L} z i m = E m ( x i m ) ∈ R L L Z m L_Z^m L Z m X m X^m X m X ^ m ∈ R N × D m \hat{X}^m\in \mathbb{R}^{N \times D_{m}} X ^ m ∈ R N × D m
公式 1 : L Z = ∑ m = 1 M L Z m = ∑ m = 1 M ∑ i = 1 N ∥ x i m − D m ( E m ( x i m ) ) ∥ 2 2 公式1:\mathcal{L}_{\mathbf{Z}}=\sum_{m=1}^{M} \mathcal{L}_{\mathbf{Z}}^{m}=\sum_{m=1}^{M} \sum_{i=1}^{N}\left\|\mathbf{x}_{i}^{m}-D^{m}\left(E^{m}\left(\mathbf{x}_{i}^{m}\right)\right)\right\|_{2}^{2}
公式 1 : L Z = m = 1 ∑ M L Z m = m = 1 ∑ M i = 1 ∑ N ∥ x i m − D m ( E m ( x i m ) ) ∥ 2 2
基于{ Z m = E m ( X m ) } m = 1 M \{\mathbf{Z}^m=E^m(X^m)\}_{m=1}^M { Z m = E m ( X m ) } m = 1 M
现有的MVC方法仍然存在如下两个挑战:
直接融合所有视图得到一个通用的表征,会使得这个表征的视图中包含一致性语义和view-private信息,后者是没有意义甚至会对模型进行误导,从而印象融合特征的质量,导致poor的聚类效果。
通过在潜在性目标上引导一个一致性目标去学习一致的多视图特征,从而实现公用语义的探索,并最小化所有视图中的相关特征的距离。这使得一致性目标和重建目标都被推到相同的特征之中,而一致性目标的目的是学习公用特征,重建目标希望获得view-private信息,这两者冲突了。
Multi-view Contrastive Learning
因为从公式1得到的潜在特征{ Z m } m = 1 M \{\mathbf{Z}^m\}_{m=1}^M { Z m } m = 1 M { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Z m } m = 1 M { Z m } m = 1 M \{\mathbf{Z}^m\}_{m=1}^M { Z m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}_{m=1}^M { H m } m = 1 M h i m ∈ R H \mathbf{h}_i^m\in \mathbb{R}^{H} h i m ∈ R H F ( { Z m } m = 1 M ; W H ) F\left(\left\{\mathbf{Z}^{m}\right\}_{m=1}^{M} ; \mathbf{W}_{H}\right) F ( { Z m } m = 1 M ; W H ) { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Z m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M
具体来说,每一个高级特征h i m \mathbf{h}_i^m h i m ( M N − 1 ) (MN-1) ( MN − 1 ) { h i m , h j n } j = 1 , … , N n = 1 , … , M \left\{\mathbf{h}_{i}^{m}, \mathbf{h}_{j}^{n}\right\}_{j=1, \ldots, N}^{n=1, \ldots, M} { h i m , h j n } j = 1 , … , N n = 1 , … , M { h i m , h i n } n ≠ m \left\{\mathbf{h}_{i}^{m}, \mathbf{h}_{i}^{n}\right\}_{n \neq m} { h i m , h i n } n = m ( M − 1 ) (M-1) ( M − 1 ) M ( N − 1 ) M(N-1) M ( N − 1 )
公式 2 : d ( h i m , h j n ) = ⟨ h i m , h j n ⟩ ∥ h i m ∥ ∥ h j n ∥ , 公式2:d\left(\mathbf{h}_{i}^{m}, \mathbf{h}_{j}^{n}\right)=\frac{\left\langle\mathbf{h}_{i}^{m}, \mathbf{h}_{j}^{n}\right\rangle}{\left\|\mathbf{h}_{i}^{m}\right\|\left\|\mathbf{h}_{j}^{n}\right\|},
公式 2 : d ( h i m , h j n ) = ∥ h i m ∥ h j n ⟨ h i m , h j n ⟩ ,
其中⟨ ⋅ , ⋅ ⟩ \langle\cdot, \cdot\rangle ⟨ ⋅ , ⋅ ⟩ H m \mathbf{H}^m H m H n \mathbf{H}^n H n
公式 3 : ℓ f c ( m n ) = − 1 N ∑ i = 1 N log e d ( h i m , h i n ) / τ F ∑ j = 1 N ∑ v = m , n e d ( h i m , h j v ) / τ F − e 1 / τ F 公式3:\ell_{f c}^{(m n)}=-\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{d\left(\mathbf{h}_{i}^{m}, \mathbf{h}_{i}^{n}\right) / \tau_{F}}}{\sum_{j=1}^{N} \sum_{v=m, n} e^{d\left(\mathbf{h}_{i}^{m}, \mathbf{h}_{j}^{v}\right) / \tau_{F}}-e^{1 / \tau_{F}}}
公式 3 : ℓ f c ( mn ) = − N 1 i = 1 ∑ N log ∑ j = 1 N ∑ v = m , n e d ( h i m , h j v ) / τ F − e 1/ τ F e d ( h i m , h i n ) / τ F
其中τ F \tau_F τ F
公式 4 : L H = 1 2 ∑ m = 1 M ∑ n ≠ m ℓ f c ( m n ) 公式4:\mathcal{L}_{\mathbf{H}}=\frac{1}{2} \sum_{m=1}^{M} \sum_{n \neq m} \ell_{f c}^{(m n)}
公式 4 : L H = 2 1 m = 1 ∑ M n = m ∑ ℓ f c ( mn )
每一个视图的特征可以写做H m = W H Z m = W H E m ( X m ) \mathbf{H}^{m}=\mathbf{W}_{H} \mathbf{Z}^{m}=\mathbf{W}_{H} E^{m}\left(\mathbf{X}^{m}\right) H m = W H Z m = W H E m ( X m ) E m E^m E m X m \mathbf{X}^m X m Z m \mathbf{Z}^m Z m Z m \mathbf{Z}^m Z m W H \mathbf{W}_H W H { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Z m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M
Learning semantic labels
具体来说,本文通过在低级特征(比如,L ( { Z m } m = 1 M ; W Q ) L\left(\left\{\mathbf{Z}^{m}\right\}_{m=1}^{M} ; \mathbf{W}_{Q}\right) L ( { Z m } m = 1 M ; W Q ) { Q m ∈ R N × K } m = 1 M \left\{\mathbf{Q}^{m} \in \mathbb{R}^{N \times K}\right\}_{m=1}^{M} { Q m ∈ R N × K } m = 1 M q i j m q_{ij}^m q ij m
所有视图的相同聚类标签表示相同的语义聚类。换句话说语义标签{ Q ⋅ j m } m = 1 M ( Q ⋅ j m ∈ R N ) \left\{\mathbf{Q}_{\cdot j}^{m}\right\}_{m=1}^{M}\left(\mathbf{Q}_{\cdot j}^{m} \in \mathbb{R}^{N}\right) { Q ⋅ j m } m = 1 M ( Q ⋅ j m ∈ R N ) Q j m \mathbf{Q}_j^m Q j m ( M K − 1 ) (MK-1) ( M K − 1 ) { Q ⋅ j m , Q ⋅ k n } k = 1 , … , K n = 1 , … , M \left\{\mathbf{Q}_{\cdot j}^{m}, \mathbf{Q}_{\cdot k}^{n}\right\}_{k=1, \ldots, K}^{n=1, \ldots, M} { Q ⋅ j m , Q ⋅ k n } k = 1 , … , K n = 1 , … , M { Q i m , Q i n } n ≠ m \left\{\mathbf{Q}_{i}^{m}, \mathbf{Q}_{i}^{n}\right\}_{n \neq m} { Q i m , Q i n } n = m ( M − 1 ) (M-1) ( M − 1 ) M ( K − 1 ) M(K-1) M ( K − 1 ) Q m \mathbf{Q}^m Q m Q n \mathbf{Q}^n Q n
公式 5 : ℓ l c ( m n ) = − 1 K ∑ j = 1 K log e d ( Q ⋅ j m , Q ⋅ j n ) / τ L ∑ k = 1 K ∑ v = m , n e d ( Q ⋅ j m , Q ⋅ k v ) / τ L − e 1 / τ L 公式5:\ell_{l c}^{(m n)}=-\frac{1}{K} \sum_{j=1}^{K} \log \frac{e^{d\left(\mathbf{Q}_{\cdot j}^{m}, \mathbf{Q}_{\cdot j}^{n}\right) / \tau_{L}}}{\sum_{k=1}^{K} \sum_{v=m, n} e^{d\left(\mathbf{Q}_{\cdot j}^{m}, \mathbf{Q}_{\cdot k}^{v}\right) / \tau_{L}}-e^{1 / \tau_{L}}}
公式 5 : ℓ l c ( mn ) = − K 1 j = 1 ∑ K log ∑ k = 1 K ∑ v = m , n e d ( Q ⋅ j m , Q ⋅ k v ) / τ L − e 1/ τ L e d ( Q ⋅ j m , Q ⋅ j n ) / τ L
其中τ L \tau_L τ L
公式 6 : L Q = 1 2 ∑ m = 1 M ∑ n ≠ m ℓ l c ( m n ) + ∑ m = 1 M ∑ j = 1 K s j m log s j m 公式6:\mathcal{L}_{\mathbf{Q}}=\frac{1}{2} \sum_{m=1}^{M} \sum_{n \neq m} \ell_{l c}^{(m n)}+\sum_{m=1}^{M} \sum_{j=1}^{K} s_{j}^{m} \log s_{j}^{m}
公式 6 : L Q = 2 1 m = 1 ∑ M n = m ∑ ℓ l c ( mn ) + m = 1 ∑ M j = 1 ∑ K s j m log s j m
其中s j m = 1 N ∑ i = 1 N q i j m s_j^m = \frac 1N\sum_{i=1}^Nq_{ij}^m s j m = N 1 ∑ i = 1 N q ij m
总的来说,多视图对比学习损失函数可以由3个部分组成:
公式 7 : L = L Z + L H + L Q = L Z ( { X m , X ^ m } m = 1 M ; { θ m , ϕ m } m = 1 M ) + L H ( { H m } m = 1 M ; W H , { θ m } m = 1 M ) + L Q ( { Q m } m = 1 M ; W Q , { θ m } m = 1 M ) 公式7:\begin{aligned}
\mathcal{L} &=\mathcal{L}_{\mathbf{Z}}+\mathcal{L}_{\mathbf{H}}+\mathcal{L}_{\mathbf{Q}} \\
&=\mathcal{L}_{\mathbf{Z}}\left(\left\{\mathbf{X}^{m}, \hat{\mathbf{X}}^{m}\right\}_{m=1}^{M} ;\left\{\theta^{m}, \phi^{m}\right\}_{m=1}^{M}\right) \\
&+\mathcal{L}_{\mathbf{H}}\left(\left\{\mathbf{H}^{m}\right\}_{m=1}^{M} ; \mathbf{W}_{H},\left\{\theta^{m}\right\}_{m=1}^{M}\right) \\
&+\mathcal{L}_{\mathbf{Q}}\left(\left\{\mathbf{Q}^{m}\right\}_{m=1}^{M} ; \mathbf{W}_{Q},\left\{\theta^{m}\right\}_{m=1}^{M}\right)
\end{aligned}
公式 7 : L = L Z + L H + L Q = L Z ( { X m , X ^ m } m = 1 M ; { θ m , ϕ m } m = 1 M ) + L H ( { H m } m = 1 M ; W H , { θ m } m = 1 M ) + L Q ( { Q m } m = 1 M ; W Q , { θ m } m = 1 M )
其中L Z \mathcal{L}_{\mathbf{Z}} L Z { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Z m } m = 1 M L H \mathcal{L}_{\mathbf{H}} L H L Q \mathcal{L}_{\mathbf{Q}} L Q { Z m } m = 1 M \{\mathbf{Z}^m\}^M_{m=1} { Z m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M W h \mathbf{W}_h W h W Q \mathbf{W}_Q W Q W H \mathbf{W}_H W H W Q \mathbf{W}_Q W Q L Z \mathcal{L}_{\mathbf{Z}} L Z
Semantic Clustering with High-level Features
通过多视图对比学习,模型同时学习高级特征{ H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M { Q m } m = 1 M \{\mathbf{Q}^m\}^M_{m=1} { Q m } m = 1 M { Q m } m = 1 M \{\mathbf{Q}^m\}^M_{m=1} { Q m } m = 1 M { H m } m = 1 M \{\mathbf{H}^m\}^M_{m=1} { H m } m = 1 M
本文采用K-means去获得每一个视图上的聚类信息。对于第m个视图,让{ c k m } k = 1 K ∈ R H \left\{\mathbf{c}_{k}^{m}\right\}_{k=1}^{K} \in \mathbb{R}^{H} { c k m } k = 1 K ∈ R H
公式 8 : min c 1 m , c 2 m , … , c K m ∑ i = 1 N ∑ j = 1 K ∥ h i m − c j m ∥ 2 2 公式8:\min _{\mathbf{c}_{1}^{m}, \mathbf{c}_{2}^{m}, \ldots, \mathbf{c}_{K}^{m}} \sum_{i=1}^{N} \sum_{j=1}^{K}\left\|\mathbf{h}_{i}^{m}-\mathbf{c}_{j}^{m}\right\|_{2}^{2}
公式 8 : c 1 m , c 2 m , … , c K m min i = 1 ∑ N j = 1 ∑ K h i m − c j m 2 2
所有样本p m ∈ R N \mathbf{p}^{m} \in \mathbb{R}^{N} p m ∈ R N
公式 9 : p i m = argmin ∥ h i m − c j m ∥ 2 2 . 公式9:p_{i}^{m}=\operatorname{argmin}\left\|\mathbf{h}_{i}^{m}-\mathbf{c}_{j}^{m}\right\|_{2}^{2} .
公式 9 : p i m = argmin h i m − c j m 2 2 .
令I m ∈ R N \mathbf{I}^m\in\mathbb{R}^N I m ∈ R N l i m = a r g m a x j q i j m l_i^m=argmax_jq_{ij}^m l i m = a r g ma x j q ij m p m \mathbf{p}^m p m I m \mathbf{I}^m I m l i m l_i^m l i m l i n l_i^n l i n I m \mathbf{I}^m I m p m \mathbf{p}^m p m
公式 10 : min A m M m A m s.t. ∑ i = 1 a i j m = 1 , ∑ j = 1 a i j m = 1 , a i j m ∈ { 0 , 1 } , i , j = 1 , 2 , … , K , 公式10:\\
\begin{aligned}
& \min _{\mathbf{A}^{m}} \mathbf{M}^{m} \mathbf{A}^{m} \\
\text { s.t. } & \sum_{i=1} a_{i j}^{m}=1, \sum_{j=1} a_{i j}^{m}=1, \\
& a_{i j}^{m} \in\{0,1\}, i, j=1,2, \ldots, K,
\end{aligned}
公式 10 : s.t. A m min M m A m i = 1 ∑ a ij m = 1 , j = 1 ∑ a ij m = 1 , a ij m ∈ { 0 , 1 } , i , j = 1 , 2 , … , K ,
其中A m ∈ { 0 , 1 } K × K \mathbf{A}^m\in\{0,1\}^{K\times K} A m ∈ { 0 , 1 } K × K M m ∈ R K × K \mathbf{M}^m\in\mathbb{R}^{K\times K} M m ∈ R K × K M m = m a x i , j m ~ i j m − M ~ m \mathbf{M}^m=max_{i,j}\tilde{m}_{i j}^{m}-\tilde{\mathbf{M}}^{m} M m = ma x i , j m ~ ij m − M ~ m m ~ i j m = ∑ n = 1 N 1 [ l n m = i ] 1 [ p n m = j ] \tilde{m}_{i j}^{m}=\sum_{n=1}^{N} \mathbb{1}\left[l_{n}^{m}=i\right] \mathbb{1}\left[p_{n}^{m}=j\right] m ~ ij m = ∑ n = 1 N 1 [ l n m = i ] 1 [ p n m = j ] l [ ⋅ ] \mathbb{l}[\cdot] l [ ⋅ ] p ^ ∈ { 0 , 1 } K \hat{\mathbf{p}}\in \{0,1\}^K p ^ ∈ { 0 , 1 } K k = k 1 [ a k s m = 1 ] 1 [ p i m = s ] , k , s ∈ { 1 , 2 , … , K } k=k \mathbb{1}\left[a_{k s}^{m}=1\right] \mathbb{1}\left[p_{i}^{m}=s\right], k, s \in\{1,2, \ldots, K\} k = k 1 [ a k s m = 1 ] 1 [ p i m = s ] , k , s ∈ { 1 , 2 , … , K } p ^ i m \hat{\mathbf{p}}_i^m p ^ i m
公式 11 : L P = − ∑ m = 1 M P ^ m log Q m 公式11:\mathcal{L}_{\mathbf{P}}=-\sum_{m=1}^{M} \hat{\mathbf{P}}^{m} \log \mathbf{Q}^{m}
公式 11 : L P = − m = 1 ∑ M P ^ m log Q m
其中P ^ m = [ p ^ 1 m ; p ^ 2 m ; … ; p ^ N m ] ∈ R N × K \hat{\mathbf{P}}^{m}=\left[\hat{\mathbf{p}}_{1}^{m} ; \hat{\mathbf{p}}_{2}^{m} ; \ldots ; \hat{\mathbf{p}}_{N}^{m}\right] \in \mathbb{R}^{N \times K} P ^ m = [ p ^ 1 m ; p ^ 2 m ; … ; p ^ N m ] ∈ R N × K
公式 12 : y i = argmax j ( 1 M ∑ m = 1 M q i j m ) 公式12:y_{i}=\underset{j}{\operatorname{argmax}}\left(\frac{1}{M} \sum_{m=1}^{M} q_{i j}^{m}\right)
公式 12 : y i = j argmax ( M 1 m = 1 ∑ M q ij m )
优化:MFLVC的优化过程,可以用算法1表示。具体来说本文采用小批量梯度下降算法来训练模型。他由多个自动编码器,一个特征MLP和标签MLP组成。自编码器的初始化方式为公式1. 多视图对比学习通过公式7得到公用语义和聚类一致性。在多视图对比学习之后,从高级特征得到的聚类标签通过最大化匹配公式10所修改。修改后的聚类标签通过公式11被用于调整模型。高级特征提取器包括编码器和特征MLP,而标签预测器包括编码器和标签MLP。
算法1:MFLVC的优化
输入:多尺度数据集{ X m } m = 1 M \{\mathbf{X}^m\}^M_{m=1} { X m } m = 1 M τ F \tau_F τ F τ L \tau_L τ L
通过最小化公式1初始化{ θ m , ϕ m } m = 1 M \left\{\theta^{m}, \phi^{m}\right\}_{m=1}^{M} { θ m , ϕ m } m = 1 M
通过公式7优化W H \mathbf{W}_H W H W Q \mathbf{W}_Q W Q { θ m , ϕ m } m = 1 M \left\{\theta^{m}, \phi^{m}\right\}_{m=1}^{M} { θ m , ϕ m } m = 1 M
通过公式8和9,计算聚类标签
通过解决公式10,匹配多视图聚类标签
通过公式11,调整W Q \mathbf{W}_Q W Q { θ } m = 1 M \{\theta\}_{m=1}^M { θ } m = 1 M
通过公式12,计算语义标签。
输出:标签预测器{ { θ m } m = 1 M , W Q } \left\{\left\{\theta^{m}\right\}_{m=1}^{M}, \mathbf{W}_{Q}\right\} { { θ m } m = 1 M , W Q }
高级特征提取器{ { θ m } m = 1 M , W H } \left\{\left\{\theta^{m}\right\}_{m=1}^{M}, \mathbf{W}_{H}\right\} { { θ m } m = 1 M , W H }
Experiments
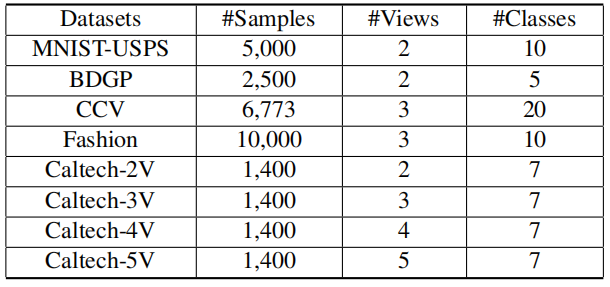
使用的数据集,样本数,视图数,类别数:
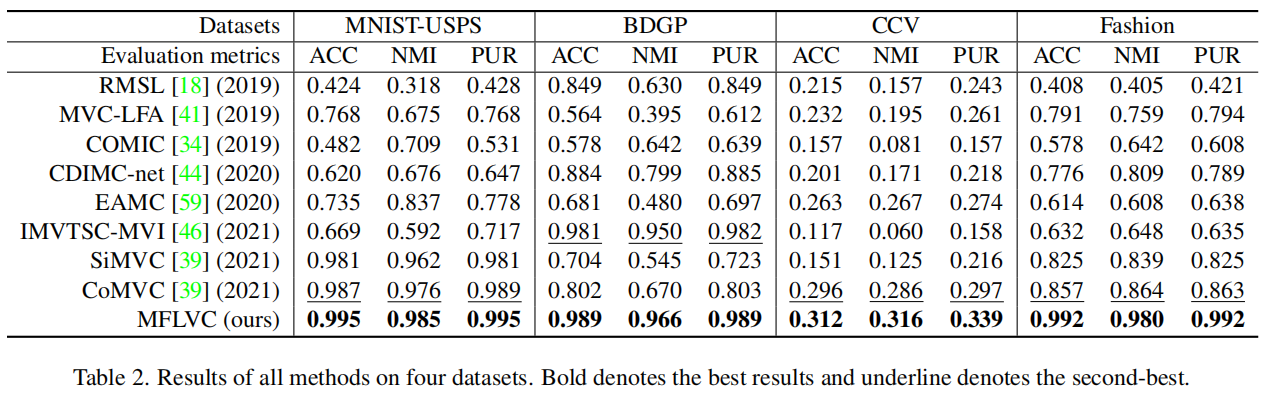
验证指标:ACC,NMI,PUR
结果:
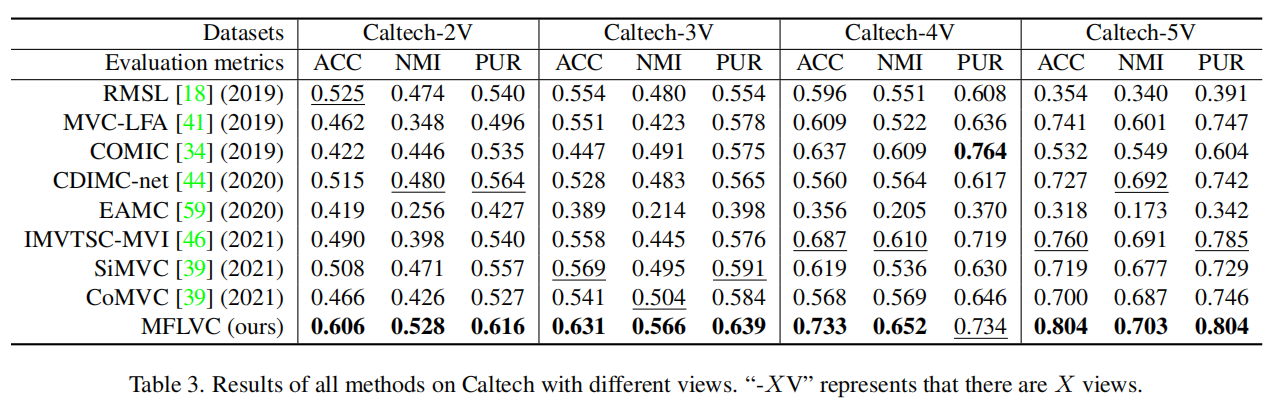
此外Caltech上通过改变不同数据集的视图数验证MFLVC在视图数变化情况的有效性
Model Analysis
图中高级特征和低级特征的聚类都逐渐变得清晰。低级特征是不密集的,因为低级特征通过重建保持了样本的多样性。高级特征是密集的,有更好的低纬度manifolds。
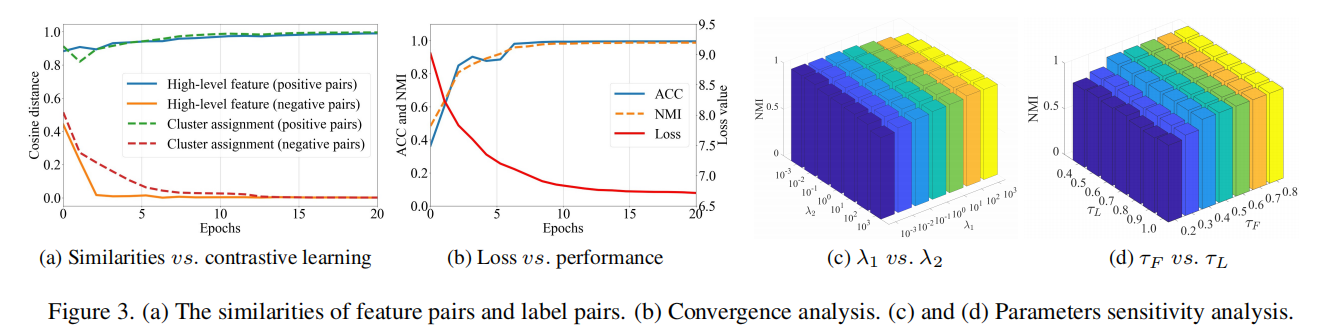
收敛性分析:图中b图在loss下降时指标提高,说明具有比较好的收敛性
参数敏感度分析:从c图和d图中可知对这两个超参数都不敏感。
Ablation Studies
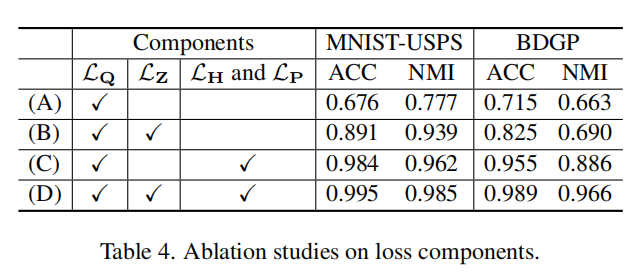
loss部分:
loss的部分你主要包括公式7和公式11的损失,消融实验的具体数值如下图:
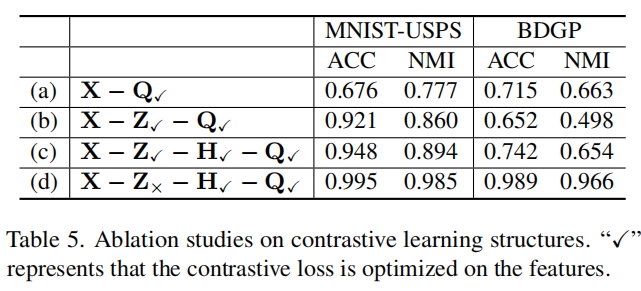
对比学习结构部分:
a表示从原始特征X中对比学习语义标签Q
b表示先从原始特征X中对比学习低级特征Z,再从低级特征对比学习语义标签Q
c表示基于低级特征Z,堆叠一个特征MLP去得到高级特征H,然后在Z,H,Q上使用对比学习
d表示只在H,Q上做对比学习,而Z在重建目标上保留