论文名称:Deep Incomplete Multi-view Clustering via Mining Cluster Complementarity
作者:Jie Xu, Huayi Tang, Yazhou Ren, Liang Peng, Xiaofeng Zhu, Lifang He
时间:2022
期刊或会议:AAAI2022
代码:https://github.com/SubmissionsIn/DIMVC
Origin Abstract
Incomplete multi-view clustering (IMVC) is an important unsupervised approach to group the multi-view data containing missing data in some views. Previous IMVC methods suffer from the following issues: (1) the inaccurate imputation or padding for missing data negatively affects the clustering performance, (2) the quality of features after fusion might be interfered by the low-quality views, especially the inaccurate imputed views. To avoid the above issues, this work presents an imputation-free and fusion-free deep IMVC framework. First, the proposed method builds a deep embedding feature learning and clustering model for each view individually. Our method then nonlinearly maps the embedding features of complete data into a high-dimensional space to discover linear separability. Concretely, this paper provides an imple mentation of the high-dimensional mapping as well as shows the mechanism to mine the multi-view cluster complemen tarity. This complementary information is then transformed to the supervised information with high confifidence, aiming to achieve the multi-view clustering consistency for the com plete data and incomplete data. Furthermore, we design an EM-like optimization strategy to alternately promote feature learning and clustering. Extensive experiments on real-world multi-view datasets demonstrate that our method achieves superior clustering performance over state-of-the-art methods.
Abstract
不完整的多视图聚类(IMVC)是一个重要的无监督方法,去分组在某些视图上含有缺失信息的多视图数据数据。
之前的IMVC方法存在如下问题:
不准确的归类或填充确实数据对聚类效果有负面影响
融合后的特征质量可能受到低质量视图的影响
为了避免这两个问题,本文提出了一个不用归类,不用融合的深度IMVC框架。首先,提出的方法在每一个视图上单独构造了一个深度嵌入特征学习和聚类的模型。本文的方法非线性映射完整数据的嵌入特征到更高的维度空间,去发掘线性可分离性。具体来说,本文提供了高维映射的互补性,也展示了这个机制去挖掘多视图聚类的互补性。
这个互补信息被转化成高置信度的监督信息,目的是为完整数据和不完整的数据取得多视图聚类的一致性。
Introduction
在实际应用中,数据通常有从不同来源收集的多个视图,比如:分类,社区检测(community detection),降维,跨模态检索。多视图聚类的目的是通过挖掘隐藏在多视图数据中的互补性来提高模型的有效性。现在已经有很多多视图聚类的方法,这些方法通常用完整的多视图数据处理,即所有视图的信息都是可以观察的数据。
图像和文本是描述一个场景的两个视图,但是只有一些图像有文本描述。不完整的多视图数据会不可避免得使得现有的多视图聚类方法首先和难以应用。于是就有了对部分多视图聚类和不完整多视图聚类(IMVC)问题的研究。
IMVC方法可以分为传统方法和深度学习方法两类。传统的方法通常使用0或者均值来填充缺失的数据,还有设计特殊的机制学习技术去实现多视图聚类,比如非负矩阵分解法,子空间学习法,核方法,图方法。然而传统的IMVC方法仍然受限于他们的表达能力和高复杂性。
最近深度学习的IMVC方法因为其有力的生成能力和可伸缩性逐渐收到关注。深度学习的IMVC方法,通常使用归类策略(imputation stategies)在多视图聚类之前去为缺失的数据推理可能的值。比如:
使用GAN的优势去生成确实数据中的期望数据
使用对比学习的方法恢复缺失的数据
但这些方法,仍然存在以下问题:
归类策略的有效性依赖于归类数据的质量。基于完整数据去正确地估计缺失数据是困难的,尤其是缺失数据特别大的时候。
因为缺失数据的GT是不知道的,所以衡量归类的质量也是困难的。
现有的IMVC方法通常通过融合过程去探索多视图数据当中的互补信息。比如
通过融合多个相似性矩阵来挖掘互补信息。
利用融合层去挖掘互补信息
但一些视图可能会继承低质量或者不正确的归类,他们会对融合过程产生负面影响
在这篇文章中提出了一个不用归类,不用融合的深度IMVC框架(DIMVC)去解决上述问题。这个框架使得确实的数据不需要被归类或者填充,以及聚类分布不需要依赖多视图的融合过程。这个框架要解决两个挑战
要发展新的策略在不融合模型中探索互补信息
在没有归类的前提下,获得完整数据和不完整数据的一致性聚类分布是困难的
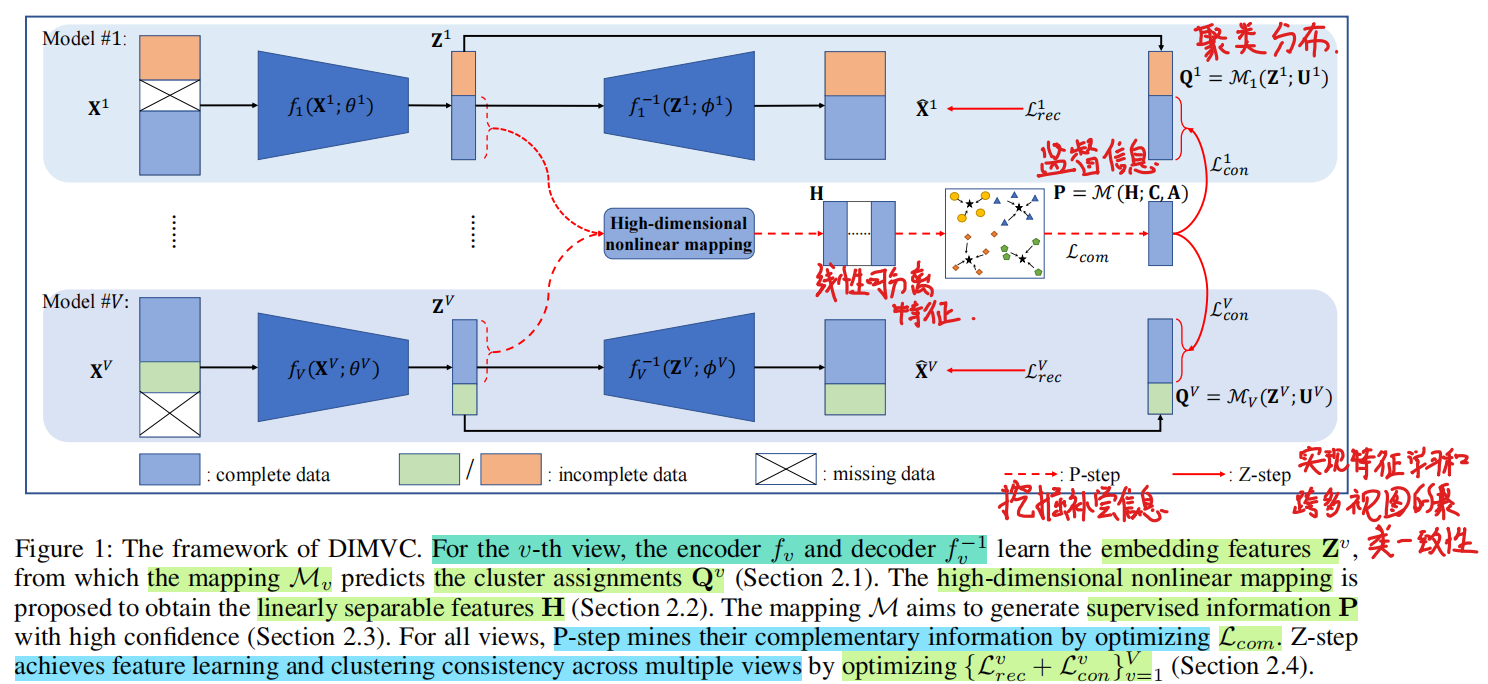
本文提出的DIMVC框架如下图:
具体来说,首先每个视图上所有可观察的数据中构建一个独立的模型,每个模型由一个自编码器和一个聚类映射构成。基于作者的观察,多视图的互补信息可以通过非线性映射描述。于是作者通过一个高维映射解决了第一个挑战。具体来说完整数据的嵌入特征被非线性映射到一个级联的权重特征空间中,其中,高度可分离的视图被设置了很高的权重。线性可分离聚类信息被和钻花为高维度特征,叫做多视图聚类互补性(multi-view cluster complementarity)。这个互补的聚类信息被转化为高置信度的监督信息,目的是获取所有视同中的一致性聚类分布,从而解决第二个挑战。此外,还提出了类EM的优化策略,包括P-step和Z-step,去交替促进特征学习和和聚类。
本文的主要贡献如下:
提出了一个新颖的深度IMVC方法,是一个不用归类也不用融合的框架,他可以避免不准确归类早造成的噪声,减轻低质量数图的干扰。
提出通过多视图中的一个非线性映射挖掘高维特征空间中的补偿信息。
设计了一个交替优化策略,有效地优化了DIMVC框架。
Method
N个样本的不完整的多视图数据集{ X v ∈ R N v × D v } v = 1 V \left\{\mathbf{X}^{v} \in \mathbb{R}^{N_{v} \times D_{v}}\right\}_{v=1}^{V} { X v ∈ R N v × D v } v = 1 V V V V D v D_v D v N v N_v N v X \mathcal{X} X
Deep model of feature learning and clustering
首先,在每个模态中引入了特征学习和聚类模型。深度自编码器能够捕获数据中的显著特征并被运用在许多无监督领域中。所以本文使用自编码器,将衣钩的多视图数据转化为clustering-friendly的嵌入特征。在第v个视图中,通过编码器和解码器学习的嵌入特征表示为Z v \mathbf{Z}^v Z v
编码器:f v ( X v ; θ v ) : X v ∈ R N v × D v ⟼ Z v ∈ R N v × d v f_{v}\left(\mathbf{X}^{v} ; \theta^{v}\right):\mathbf{X}^{v} \in \mathbb{R}^{N_{v} \times D_{v}} \longmapsto \mathbf{Z}^{v} \in \mathbb{R}^{N_{v} \times d_{v}} f v ( X v ; θ v ) : X v ∈ R N v × D v ⟼ Z v ∈ R N v × d v
解码器:f v − 1 ( Z v ; ϕ v ) : Z v ∈ R N v × d v ⟼ X ^ v ∈ R N v × D v f_{v}^{-1}\left(\mathbf{Z}^{v} ; \phi^{v}\right): \mathbf{Z}^{v} \in \mathbb{R}^{N_{v} \times d_{v}} \longmapsto \hat{\mathbf{X}}^{v} \in \mathbb{R}^{N_{v} \times D_{v}} f v − 1 ( Z v ; ϕ v ) : Z v ∈ R N v × d v ⟼ X ^ v ∈ R N v × D v
其中d v d_v d v θ v \theta^v θ v ϕ v \phi^v ϕ v X v \mathbf{X}^v X v X ^ v \hat{\mathbf{X}}^v X ^ v
公式 1 : L r e c = ∑ v = 1 V ∥ X v − f v − 1 ( Z v ) ∥ F 2 = ∑ v = 1 V ∑ i = 1 N v ∥ x i v − f v − 1 ( f v ( x i v ) ) ∥ 2 2 公式1:
\begin{aligned}
\mathcal{L}_{r e c} &=\sum_{v=1}^{V}\left\|\mathbf{X}^{v}-f_{v}^{-1}\left(\mathbf{Z}^{v}\right)\right\|_{F}^{2} \\
&=\sum_{v=1}^{V} \sum_{i=1}^{N_{v}}\left\|\mathbf{x}_{i}^{v}-f_{v}^{-1}\left(f_{v}\left(\mathbf{x}_{i}^{v}\right)\right)\right\|_{2}^{2}
\end{aligned}
公式 1 : L rec = v = 1 ∑ V X v − f v − 1 ( Z v ) F 2 = v = 1 ∑ V i = 1 ∑ N v x i v − f v − 1 ( f v ( x i v ) ) 2 2
利用一个参数映射,M v ( Z v ; U v ) : Z v ∈ R N v × d v ⟼ Q v ∈ R N v × K \mathcal{M}_{v}\left(\mathbf{Z}^{v} ; \mathbf{U}^{v}\right): \mathbf{Z}^{v} \in \mathbb{R}^{N_{v} \times d_{v}} \longmapsto \mathbf{Q}^{v} \in \mathbb{R}^{N_{v} \times K} M v ( Z v ; U v ) : Z v ∈ R N v × d v ⟼ Q v ∈ R N v × K Q v \mathbf{Q}^v Q v U v = [ u 1 v ; u 2 v ; … ; u K v ] ∈ R K × d v \mathbf{U}^{v}=\left[\mathbf{u}_{1}^{v} ; \mathbf{u}_{2}^{v} ; \ldots ; \mathbf{u}_{K}^{v}\right] \in \mathbb{R}^{K \times d_{v}} U v = [ u 1 v ; u 2 v ; … ; u K v ] ∈ R K × d v
公示 2 : q i j v = ( 1 + ∥ z i v − u j v ∥ 2 2 ) − 1 ∑ j = 1 K ( 1 + ∥ z i v − u j v ∥ 2 2 ) − 1 ∈ Q v 公示2:q_{i j}^{v}=\frac{\left(1+\left\|\mathbf{z}_{i}^{v}-\mathbf{u}_{j}^{v}\right\|_{2}^{2}\right)^{-1}}{\sum_{j=1}^{K}\left(1+\left\|\mathbf{z}_{i}^{v}-\mathbf{u}_{j}^{v}\right\|_{2}^{2}\right)^{-1}} \in \mathbf{Q}^{v}
公示 2 : q ij v = ∑ j = 1 K ( 1 + z i v − u j v 2 2 ) − 1 ( 1 + z i v − u j v 2 2 ) − 1 ∈ Q v
在第v个视图中u j v \mathbf{u}_j^v u j v q i j v q_{ij}^v q ij v
Multi-view cluster complementarity
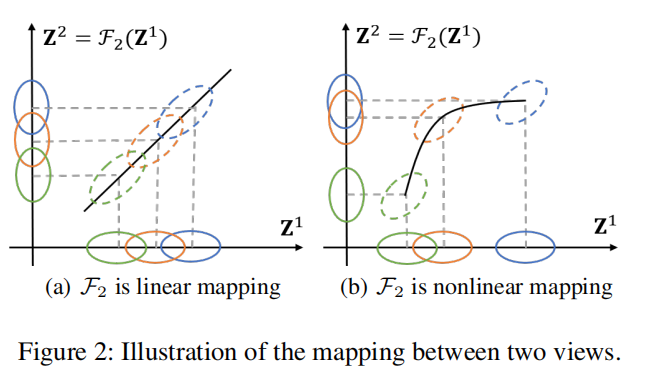
因为多视图共享相同的语义信息,对于每一个视图可以被认为是其他视图的映射,如下图:
图中(a),如果一个视图是其他视图的线性映射,他们是没有互补信息的。但是如果在多视图中存在互补关系,在一个视图的不可分离性聚类在其他视图是可分离的,互补性可以通过如图中b的非线性映射描述。
通过考虑聚类分布作为样本的伪标签的方式,可以将聚类问题看做分类问题。
假设1:
一个负载的分类问题可以被看做是线性可分的,当其非线性映射到高维度空间时。
根据假设1,本文提出通过线性映射H \mathcal{H} H
公式 3 : H = H ( { Z v } v = 1 V ) = ( w 1 Z 1 , w 2 Z 2 , … , w V Z V ) 公式3:\mathbf{H}=\mathcal{H}\left(\left\{\mathbf{Z}^{v}\right\}_{v=1}^{V}\right)=\left(w_{1} \mathbf{Z}^{1}, w_{2} \mathbf{Z}^{2}, \ldots, w_{V} \mathbf{Z}^{V}\right)
公式 3 : H = H ( { Z v } v = 1 V ) = ( w 1 Z 1 , w 2 Z 2 , … , w V Z V )
其中H ∈ R ∣ X ∣ × ∑ v = 1 V d v \mathbf{H} \in \mathbb{R}^{|\mathcal{X}| \times \sum_{v=1}^{V} d_{v}} H ∈ R ∣ X ∣ × ∑ v = 1 V d v w v w_v w v
公式 4 : w v = 1 + log ( 1 + σ ( U v ) ∑ v σ ( U v ) ) 公式4:w_{v}=1+\log \left(1+\frac{\sigma\left(\mathbf{U}^{v}\right)}{\sum_{v} \sigma\left(\mathbf{U}^{v}\right)}\right)
公式 4 : w v = 1 + log ( 1 + ∑ v σ ( U v ) σ ( U v ) )
其中σ ( U v ) \sigma(\mathbf{U}^v) σ ( U v ) U v \mathbf{U^v} U v { w v } v = 1 V \{w_v\}^V_{v=1} { w v } v = 1 V H \mathcal{H} H
理论1:
H \mathbf{H} H { Z v } v = 1 V \{\mathbf{Z}^v\}_{v=1}^V { Z v } v = 1 V H \mathbf{H} H Z v Z^v Z v
证明:
考虑到每个视图的每个样本的嵌入特征z i v \mathbf{z}_{i}^{v} z i v z i t = F t ( z i v ) ∈ R d t \mathbf{z}_{i}^{t}=\mathcal{F}_{t}\left(\mathbf{z}_{i}^{v}\right) \in \mathbb{R}^{d_{t}} z i t = F t ( z i v ) ∈ R d t t ∈ { 1 , 2 , … V } t \in \{1,2, \ldots V\} t ∈ { 1 , 2 , … V } { F t : Z v ⟼ Z t } t ≠ v V \left\{\mathcal{F}_{t}: \mathbf{Z}^{v} \longmapsto \mathbf{Z}^{t}\right\}_{t \neq v}^{V} { F t : Z v ⟼ Z t } t = v V ( z i 1 , z i 2 , … , z i V ) = ( F 1 ( z i v ) , F 2 ( z i v ) , … , F V ( z i v ) ) ∈ R ∑ v = 1 V d v , ∑ v = 1 V d v > d v \left(\mathbf{z}_{i}^{1}, \mathbf{z}_{i}^{2}, \ldots, \mathbf{z}_{i}^{V}\right)=\left(\mathcal{F}_{1}\left(\mathbf{z}_{i}^{v}\right), \mathcal{F}_{2}\left(\mathbf{z}_{i}^{v}\right), \ldots, \mathcal{F}_{V}\left(\mathbf{z}_{i}^{v}\right)\right) \in \mathbb{R}^{\sum_{v=1}^{V} d_{v}}, \sum_{v=1}^{V} d_{v}>d_{v} ( z i 1 , z i 2 , … , z i V ) = ( F 1 ( z i v ) , F 2 ( z i v ) , … , F V ( z i v ) ) ∈ R ∑ v = 1 V d v , ∑ v = 1 V d v > d v z i v \mathbf{z}_{i}^{v} z i v w v w_{v} w v H : { Z v } v = 1 V ⟼ H \mathcal{H}:\left\{\mathbf{Z}^{v}\right\}_{v=1}^{V} \longmapsto \mathbf{H} H : { Z v } v = 1 V ⟼ H
基于理论1,映射H \mathcal{H} H H \mathbf{H} H C \mathcal{C} C
公式 5 : L c o m = min { C v } v = 1 V ∑ i ∈ X ∑ j = 1 K ∑ v = 1 V ∥ w v z i v − c j v ∥ 2 2 = min C ∑ i ∈ X ∑ j = 1 K ∥ h i − c j ∥ 2 2 公式5:\begin{aligned}
\mathcal{L}_{c o m} &=\min _{\left\{\mathbf{C}^{v}\right\}_{v=1}^{V}} \sum_{i \in \mathcal{X}} \sum_{j=1}^{K} \sum_{v=1}^{V}\left\|w_{v} \mathbf{z}_{i}^{v}-\mathbf{c}_{j}^{v}\right\|_{2}^{2} \\
&=\min _{\mathbf{C}} \sum_{i \in \mathcal{X}} \sum_{j=1}^{K}\left\|\mathbf{h}_{i}-\mathbf{c}_{j}\right\|_{2}^{2}
\end{aligned}
公式 5 : L co m = { C v } v = 1 V min i ∈ X ∑ j = 1 ∑ K v = 1 ∑ V w v z i v − c j v 2 2 = C min i ∈ X ∑ j = 1 ∑ K ∥ h i − c j ∥ 2 2
其中:C ∈ R K × ∑ v = 1 V d v \mathbf{C} \in \mathbb{R}^{K \times \sum_{v=1}^{V} d_{v}} C ∈ R K × ∑ v = 1 V d v c j = ( c j 1 , c j 2 , … , c j V ) ∈ R ∑ v = 1 V d v \mathbf{c}_{j}=\left(\mathbf{c}_{j}^{1}, \mathbf{c}_{j}^{2}, \ldots, \mathbf{c}_{j}^{V}\right) \in \mathbb{R}^{\sum_{v=1}^{V} d_{v}} c j = ( c j 1 , c j 2 , … , c j V ) ∈ R ∑ v = 1 V d v X \mathcal{X} X
Multi-view clustering consistency
在CWFS中,所有视图中的线性可分离聚类信息被转化为高维特征H \mathbf{H} H M ( H ; C , A ) : H ∈ R ∣ X ∣ × ∑ v = 1 V d v ⟼ P ∈ R ∣ X ∣ × K \mathcal{M}(\mathbf{H} ; \mathbf{C}, \mathbf{A}): \mathbf{H} \in\mathbb{R}^{|\mathcal{X}| \times \sum_{v=1}^{V} d_{v}} \longmapsto \mathbf{P} \in \mathbb{R}^{|\mathcal{X}| \times K} M ( H ; C , A ) : H ∈ R ∣ X ∣ × ∑ v = 1 V d v ⟼ P ∈ R ∣ X ∣ × K
公式 6 : P = M ( H ; C , A ) = E ( S ( H , C ) ) A 公式6:\mathbf{P}=\mathcal{M}(\mathbf{H} ; \mathbf{C}, \mathbf{A})=\mathcal{E}(\mathcal{S}(\mathbf{H}, \mathbf{C})) \mathbf{A}
公式 6 : P = M ( H ; C , A ) = E ( S ( H , C )) A
其中函数S \mathcal{S} S s i j s_{ij} s ij
公式 7 : s i j = S ( h i , c j ) = 1 1 + ∥ h i − c j ∥ 2 2 ∈ S 公式7:s_{i j}=\mathcal{S}\left(\mathbf{h}_{i}, \mathbf{c}_{j}\right)=\frac{1}{1+\left\|\mathbf{h}_{i}-\mathbf{c}_{j}\right\|_{2}^{2}} \in \mathbf{S}
公式 7 : s ij = S ( h i , c j ) = 1 + ∥ h i − c j ∥ 2 2 1 ∈ S
通过这种方式,当h i \mathbf{h}_i h i c j \mathcal{c}_j c j s i j s_{ij} s ij E ( S ) \mathcal{E}(\mathbf{S}) E ( S ) [ 0 , 1 ] [0,1] [ 0 , 1 ] { s i 1 , s i 2 , … , s i K } \left\{s_{i 1}, s_{i 2}, \ldots, s_{i K}\right\} { s i 1 , s i 2 , … , s i K }
公式 8 : s i j = E ( s i ) = ( s i j / ∑ j s i j ) 2 ∑ j ( s i j / ∑ j s i j ) 2 公式8:s_{i j}=\mathcal{E}\left(\mathbf{s}_{i}\right)=\frac{\left(s_{i j} / \sum_{j} s_{i j}\right)^{2}}{\sum_{j}\left(s_{i j} / \sum_{j} s_{i j}\right)^{2}}
公式 8 : s ij = E ( s i ) = ∑ j ( s ij / ∑ j s ij ) 2 ( s ij / ∑ j s ij ) 2
A \mathbf{A} A A A T = I K \mathbf{A} \mathbf{A}^{T}=\mathbf{I}_{K} A A T = I K S \mathbf{S} S P \mathbf{P} P Q v \mathbf{Q}^{v} Q v
公式 9 : L c o n = ∑ v = 1 V H ( P , Q v ) = − ∑ v = 1 V ∑ i ∈ X p i log q i v 公式9:\mathcal{L}_{c o n}=\sum_{v=1}^{V} H\left(\mathbf{P}, \mathbf{Q}^{v}\right)=-\sum_{v=1}^{V} \sum_{i \in \mathcal{X}} \mathbf{p}_{i} \log \mathbf{q}_{i}^{v}
公式 9 : L co n = v = 1 ∑ V H ( P , Q v ) = − v = 1 ∑ V i ∈ X ∑ p i log q i v
因为相同的P \mathbf{P} P { Q v } v = 1 V \left\{\mathbf{Q}^{v}\right\}_{v=1}^{V} { Q v } v = 1 V
公式 10 : y i = arg max j ∑ v q i j v 公式10:y_{i}=\arg \max _{j} \sum_{v} q_{i j}^{v}
公式 10 : y i = arg j max v ∑ q ij v
因为每个视图有他自己的聚类预测,并且不依赖于多视图的融合特征,所以经过本文的方法训练出的模型是不用融合的。
Optimization
本文提出的框架的损失函数由三个部分组成:
公式 11 : L = L r e c + L c o m + L c o n = min C , A , { Z v , U v } v = 1 V ∑ v = 1 V ∥ X v − f v − 1 ( Z v ) ∥ F 2 + ∑ i ∈ X ∑ j = 1 K ∥ h i − c j ∥ 2 2 + ∑ v = 1 V H ( P , Q v ) , s.t. P = M ( H ; C , A ) , A A T = I K , Q v = M v ( Z v ; U v ) , 公式11:\begin{aligned}
\mathcal{L} &=\mathcal{L}_{r e c}+\mathcal{L}_{c o m}+\mathcal{L}_{c o n} \\
&=\min _{\mathbf{C}, \mathbf{A},\left\{\mathbf{Z}^{v}, \mathbf{U}^{v}\right\}_{v=1}^{V}} \sum_{v=1}^{V}\left\|\mathbf{X}^{v}-f_{v}^{-1}\left(\mathbf{Z}^{v}\right)\right\|_{F}^{2} \\
&+\sum_{i \in \mathcal{X}} \sum_{j=1}^{K}\left\|\mathbf{h}_{i}-\mathbf{c}_{j}\right\|_{2}^{2}+\sum_{v=1}^{V} H\left(\mathbf{P}, \mathbf{Q}^{v}\right),\\
&\text { s.t. } \mathbf{P}=\mathcal{M}(\mathbf{H} ; \mathbf{C}, \mathbf{A}), \mathbf{A} \mathbf{A}^{T}=\mathbf{I}_{K}, \mathbf{Q}^{v}=\mathcal{M}_{v}\left(\mathbf{Z}^{v} ; \mathbf{U}^{v}\right),
\end{aligned}
公式 11 : L = L rec + L co m + L co n = C , A , { Z v , U v } v = 1 V min v = 1 ∑ V X v − f v − 1 ( Z v ) F 2 + i ∈ X ∑ j = 1 ∑ K ∥ h i − c j ∥ 2 2 + v = 1 ∑ V H ( P , Q v ) , s.t. P = M ( H ; C , A ) , A A T = I K , Q v = M v ( Z v ; U v ) ,
其中Z v = f v ( X v ) , H = H ( { Z v } v = 1 V ) \mathbf{Z}^{v}=f_{v}\left(\mathbf{X}^{v}\right), \mathbf{H}=\mathcal{H}\left(\left\{\mathbf{Z}^{v}\right\}_{v=1}^{V}\right) Z v = f v ( X v ) , H = H ( { Z v } v = 1 V ) L r e c \mathcal{L}_{r e c} L rec L com \mathcal{L}_{\text {com }} L com L con \mathcal{L}_{\text {con }} L con
为了优化上面的不可微的目标函数,本文提出了交替优化策略如下:
初始化 :首先深度编码器通过公式1进行初始化,并得到有意义的嵌入特征。然后聚类中心{ U 1 , U 2 , … , U V } \left\{\mathbf{U}^{1}, \mathbf{U}^{2}, \ldots, \mathbf{U}^{V}\right\} { U 1 , U 2 , … , U V } A \mathbf{A} A I K \mathbf{I}_{K} I K
P-step :固定{ Z v , U v } v = 1 V \left\{\mathbf{Z}^{v}, \mathbf{U}^{v}\right\}_{v=1}^{V} { Z v , U v } v = 1 V { P , C , A } \{\mathbf{P}, \mathbf{C}, \mathbf{A}\} { P , C , A }
首先C \mathbf{C} C l i ( t ) = argmax j s i j ( t ) l_{i}^{(t)}=\operatorname{argmax}_{j} s_{i j}^{(t)} l i ( t ) = argmax j s ij ( t ) h i \mathbf{h}_i h i l i ( t + 1 ) l_{i}^{(t+1)} l i ( t + 1 ) l i ( t ) l_{i}^{(t)} l i ( t ) m ~ i j = ∑ n ∈ X 1 [ l n ( t + 1 ) = i ] 1 [ l n ( t ) = j ] \tilde{m}_{i j}=\sum_{n \in \mathcal{X}} \mathbb{1}\left[l_{n}^{(t+1)}=i\right] \mathbb{1}\left[l_{n}^{(t)}=j\right] m ~ ij = ∑ n ∈ X 1 [ l n ( t + 1 ) = i ] 1 [ l n ( t ) = j ] M ∈ R K × K \mathbf{M} \in \mathbb{R}^{K \times K} M ∈ R K × K m i j = max i , j m ~ i j − m ~ i j m_{i j}=\max _{i, j} \tilde{m}_{i j}-\tilde{m}_{i j} m ij = max i , j m ~ ij − m ~ ij
公式 12 : min A ∑ i = 1 K ∑ j = 1 K m i j a i j s.t. A A T = I K , 公式12:\begin{array}{l}
\min _{\mathbf{A}} \sum_{i=1}^{K} \sum_{j=1}^{K} m_{i j} a_{i j} \\
\text { s.t. } \mathbf{A} \mathbf{A}^{T}=\mathbf{I}_{K},
\end{array}
公式 12 : min A ∑ i = 1 K ∑ j = 1 K m ij a ij s.t. A A T = I K ,
其中A ∈ R K × K \mathbf{A}\in \mathbb{R}^{K\times K} A ∈ R K × K
然后,P \mathbf{P} P M ( H ; C , A ) \mathcal{M}(\mathbf{H} ; \mathbf{C}, \mathbf{A}) M ( H ; C , A ) H , C \mathbf{H}, \mathbf{C} H , C A \mathbf{A} A
Z-step :固定{ P , C , A } \{\mathbf{P}, \mathbf{C}, \mathbf{A}\} { P , C , A } { Z v , U v } v = 1 V \left\{\mathbf{Z}^{v}, \mathbf{U}^{v}\right\}_{v=1}^{V} { Z v , U v } v = 1 V
给定固定的C \mathbf{C} C A \mathbf{A} A P \mathbf{P} P { L 1 , L 2 , … , L V } \left\{\mathcal{L}^{1}, \mathcal{L}^{2}, \ldots, \mathcal{L}^{V}\right\} { L 1 , L 2 , … , L V } L v = L rec v + L con v = ∥ X v − f v − 1 ( Z v ) ∥ F 2 + H ( P , Q v ) \mathcal{L}^{v}=\mathcal{L}_{\text {rec }}^{v}+\mathcal{L}_{\text {con }}^{v}=\left\|\mathbf{X}^{v}-f_{v}^{-1}\left(\mathbf{Z}^{v}\right)\right\|_{F}^{2}+H\left(\mathbf{P}, \mathbf{Q}^{v}\right) L v = L rec v + L con v = X v − f v − 1 ( Z v ) F 2 + H ( P , Q v ) λ \lambda λ
公式 13 : U v = U v − λ n ∑ i = 1 n ∂ L v ∂ U v Z v = Z v − λ n ∑ i = 1 n ∂ L v ∂ Z v 公式13:\begin{aligned}
\mathbf{U}^{v} &=\mathbf{U}^{v}-\frac{\lambda}{n} \sum_{i=1}^{n} \frac{\partial \mathcal{L}^{v}}{\partial \mathbf{U}^{v}} \\
\mathbf{Z}^{v} &=\mathbf{Z}^{v}-\frac{\lambda}{n} \sum_{i=1}^{n} \frac{\partial \mathcal{L}^{v}}{\partial \mathbf{Z}^{v}}
\end{aligned}
公式 13 : U v Z v = U v − n λ i = 1 ∑ n ∂ U v ∂ L v = Z v − n λ i = 1 ∑ n ∂ Z v ∂ L v
其中Z v \mathbf{Z}^v Z v
P-step过程通过从所有视图的嵌入特征中挖掘聚类胡必行来产生更精确的监督信息。Z-step使每个视图的模型利用监督信息学习更好的聚类嵌入特征。
算法1:DIMVC的优化
输入 :数据集X v ∈ R N v × D v \mathbf{X}^v\in \mathbb{R}^{N_v\times D_v} X v ∈ R N v × D v
输出:聚类预测
初始化 :通过公式1,初始化{ Z v } v = 1 V \{\mathbf{Z}^v\}^V_{v=1} { Z v } v = 1 V { U v } v = 1 V \{\mathbf{U}^v\}^V_{v=1} { U v } v = 1 V A = I K \mathbf{A} =\mathbf{I}_{K} A = I K while 未达到最大迭代次数 do : P-step :固定{ Z v , U v } v = 1 V \left\{\mathbf{Z}^{v}, \mathbf{U}^{v}\right\}_{v=1}^{V} { Z v , U v } v = 1 V
通过公式5更新C \mathbf{C} C
通过公式12更新A \mathbf{A} A
通过公式6更新P \mathbf{P} P
Z-step :固定{ P , C , A } \{\mathbf{P}, \mathbf{C}, \mathbf{A}\} { P , C , A }
通过公式13更新{ Z v , U v } v = 1 V \left\{\mathbf{Z}^{v}, \mathbf{U}^{v}\right\}_{v=1}^{V} { Z v , U v } v = 1 V
end while
通过公式2和10计算聚类预测
Experiments
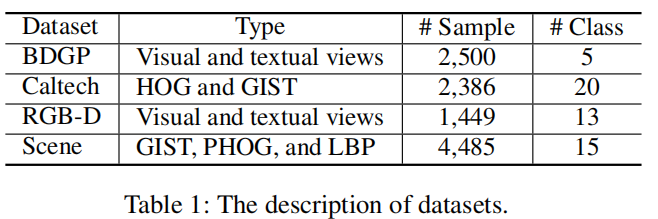
数据集信息如下表:
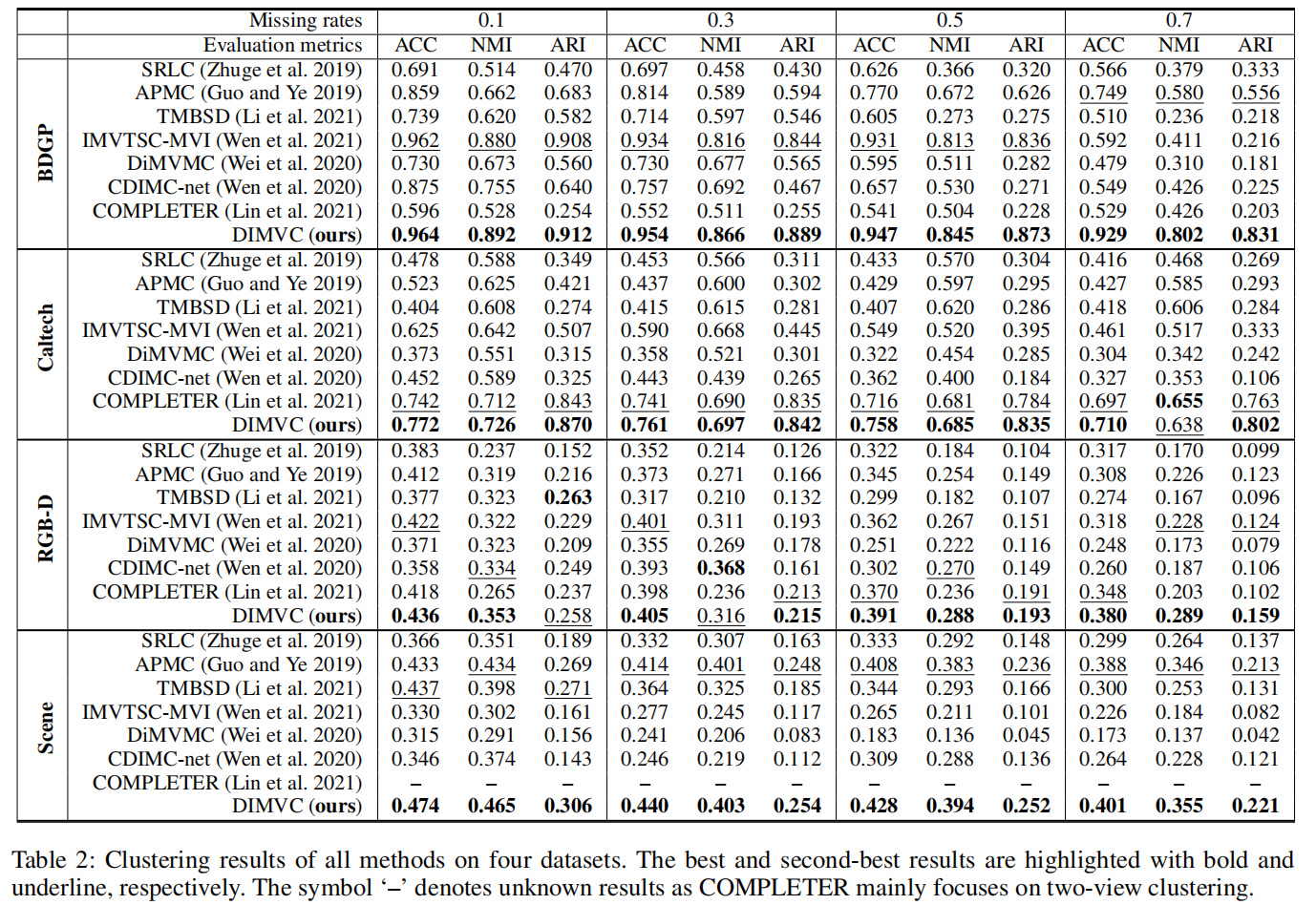
在数据集上对比的方法实验结果如下表:
DIMVC在所有数据集中都具有最好的表现。
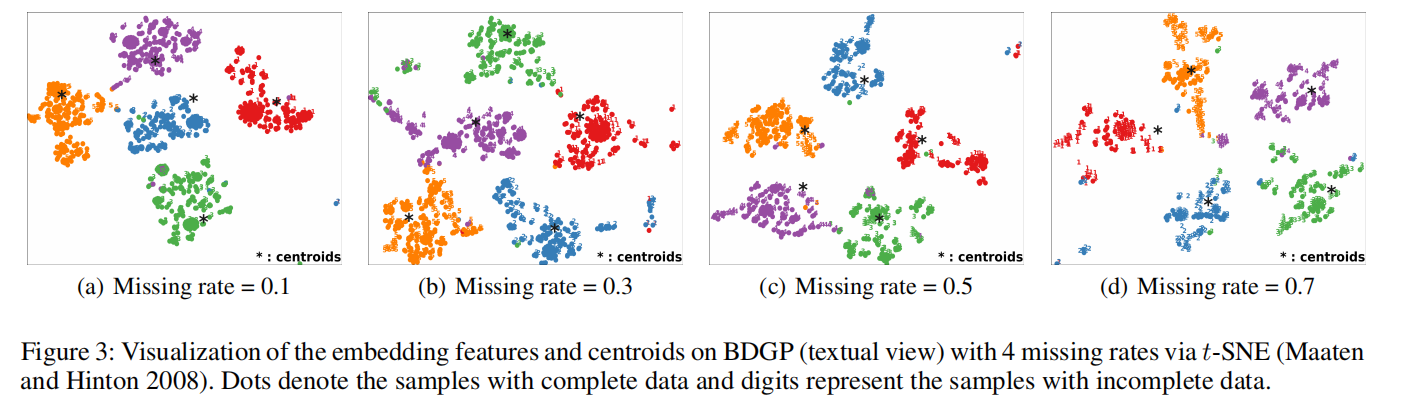
在丢失率(missing rate)从0.1变化到0.7时,所有方法的聚类表现,而DIMVC在大部分情况下仍然保持较好的聚类效果。
原因:
如果多视图数据的丢失率变高,多视图中的互补信息变少。这是所有方法聚类质量下降的原因
归类方法需要数据分布的估计,因此当丢失率变高时,计算误差增大。
融合方法会受到低质量视图的影响,尤其是不完整多视图学习。
学习嵌入特征和中心的过程如下图: