论文名称:Reverse Graph Learning for Graph Neural Network
作者:Liang Peng; Rongyao Hu; Fei Kong; Jiangzhang Gan; Yujie Mo; Xiaoshuang Shi; Xiaofeng Zhu
时间:2022-4
期刊:IEEE Transactions on Neural Networks and Learning Systems
原文摘要
Graph neural networks (GNNs) conduct feature learning by taking into account the local structure preservation of the data to produce discriminative features, but need to address the following issues, i.e., 1) the initial graph containing faulty and missing edges often affect feature learning and 2) most GNN methods suffer from the issue of out-of-example since their training processes do not directly generate a prediction model to predict unseen data points. In this work, we propose a reverse GNN model to learn the graph from the intrinsic space of the original data points as well as to investigate a new out-of-sample extension method. As a result, the proposed method can output a high-quality graph to improve the quality of feature learning, while the new method of out-of-sample extension makes our reverse GNN method available for conducting supervised learning and semi-supervised learning. Experimental results on real-world datasets show that our method outputs competitive classifification performance, compared to state-of-the-art methods, in terms of semi-supervised node classifification, out-of-sample extension, random edge attack, link prediction, and image retrieval.
研究问题
图神经网络通过考虑数据的局部结构去产生有区别的特征,从而实现特征学习。但这个领域仍然存在两个问题
如果初始图包含存在缺陷或者缺失边,这个初始图通常会影响特征的学习。
包含有噪声和异常值的原始数据很容易导致两个数据节点的不正确关系
大部分的GNN方法不能解决out-of-example(外部数据)的问题,因为训练过程中,他们不是直接生成一个预测模型去预测不可见的数据点。
算法任务与应用:
有监督节点分类
通过使用外部数据拓展的有监督节点分类
随机边缘攻击(随机去除图的一些边)
连接预测(遮掩一部分边,看模型是能重新找回边)
图像检索
理论基础:
图神经网络能够捕获数据节点之间的局部集合结构,从非欧几里得数据中提取局部的,成分的以及判别的特征。
图神经网络的输入通常是原始数据和一个包含局部结构的初始图(数据点和他的邻居之间的相似性)。
图的底层信息对图神经网络模型至关重要,错误的信息(如不正确的边)和不足的信息(如缺失的边)将会传递给网络构建,误导模型,限制其有效性
低质量的图不能产生判别信息
创新点:
反转图学习:原始数据的表征通常含有噪声和荣誉,因此,在原始数据上构建的初始图结构是不可靠的,低质量的。为了解决这一问题,提出了翻转图学习,这个图是从原始数据的本质空间(intrinsic space)构建的。因此噪声问题会被缓解。反转图学习也可以根据特征学习的更新自适应地调整。
外部样本拓展:将每个不可见数据点的特征分配为其最近邻节点的特征。本文的方法在反转图学习层中,从原始数据的本质空间得到初始图,以保证获得真正接近的节点。
提出方法:
问题定义(节点分类为例)
为了执行传递特征表示,同时考虑数据节点之间的数据对关系,GNN模型通常会有几个隐藏层,每一层包括特征学习和邻接节点聚合。GNN的第l+1层的图卷积操作,可以用下面的公式表示:
公式 1 : H l + 1 = σ ( D − 1 2 A D − 1 2 H l W l ) 公式1:\mathbf{H}^{l+1}=\sigma(\mathbf{D}^{-\frac 12}\mathbf{A}\mathbf{D}^{-\frac{1}{2}}\mathbf{H}^l\mathbf{W}^l)
公式 1 : H l + 1 = σ ( D − 2 1 A D − 2 1 H l W l )
其中D ∈ R n × n \mathbf{D} \in \mathbf{R}^{n \times n} D ∈ R n × n A ∈ R n × n \mathbf{A} \in \mathbb{R}^{n \times n} A ∈ R n × n 拉普拉斯矩阵 ,W l ∈ R d l × d l + 1 \mathbf{W}^{l} \in \mathbb{R}^{d_{l} \times d_{l+1}} W l ∈ R d l × d l + 1 d l d_l d l d l + 1 d_{l+1} d l + 1 σ ( . ) \sigma(.) σ ( . ) Z Z Z
公式 2 : O = Softmax ( Linear ( Z ) ) 公式2:\mathbf{O}=\operatorname{Softmax}(\text { Linear }(\mathbf{Z}))
公式 2 : O = Softmax ( Linear ( Z ))
其中L i n e a r ( ⋅ ) Linear(\cdot) L in e a r ( ⋅ ) O ∈ R n × c \mathbf{O} \in \mathbb{R}^{n \times c} O ∈ R n × c c c c
公式 3 : L G N N = − ∑ v i ∈ Y L ( y i log ( o i ) + ( 1 − y i ) log ( 1 − o i ) ) 公式3:\mathcal{L}_{\mathrm{GNN}}=-\sum_{\mathrm{v}_{i} \in Y_{L}}\left(y_{i} \log \left(o_{i}\right)+\left(1-y_{i}\right) \log \left(1-o_{i}\right)\right)
公式 3 : L GNN = − v i ∈ Y L ∑ ( y i log ( o i ) + ( 1 − y i ) log ( 1 − o i ) )
其中Y L Y_L Y L y i y_i y i o i o_i o i
公式 4 : L = L G N N + γ L G L 公式4:\mathcal{L}=\mathcal{L}_{\mathrm{GNN}}+\gamma \mathcal{L}_{\mathrm{GL}}
公式 4 : L = L GNN + γ L GL
其中γ \gamma γ L G L \mathcal{L}_{\mathrm{GL}} L GL
公式 5 : L G L : min S ∑ i , j = 1 n ∥ x i − x j ∥ 2 2 s i j + ∥ S ∥ F 2 s.t., ∑ j = 1 n s i j = 1 , s i j > 0 , i , j = 1 , … , n 公式5:\begin{aligned}
\mathcal{L}_{\mathrm{GL}}: & \min _{\mathbf{S}} \sum_{i, j=1}^{n}\left\|\mathbf{x}_{i}-\mathbf{x}_{j}\right\|_{2}^{2} s_{i j}+\|\mathbf{S}\|_{F}^{2} \\
\text { s.t., } & \sum_{j=1}^{n} s_{i j}=1, \quad s_{i j}>0, i, j=1, \ldots, n
\end{aligned}
公式 5 : L GL : s.t., S min i , j = 1 ∑ n ∥ x i − x j ∥ 2 2 s ij + ∥ S ∥ F 2 j = 1 ∑ n s ij = 1 , s ij > 0 , i , j = 1 , … , n
其中s i j s_{ij} s ij x i \mathbf{x}_i x i x j \mathbf{x}_j x j
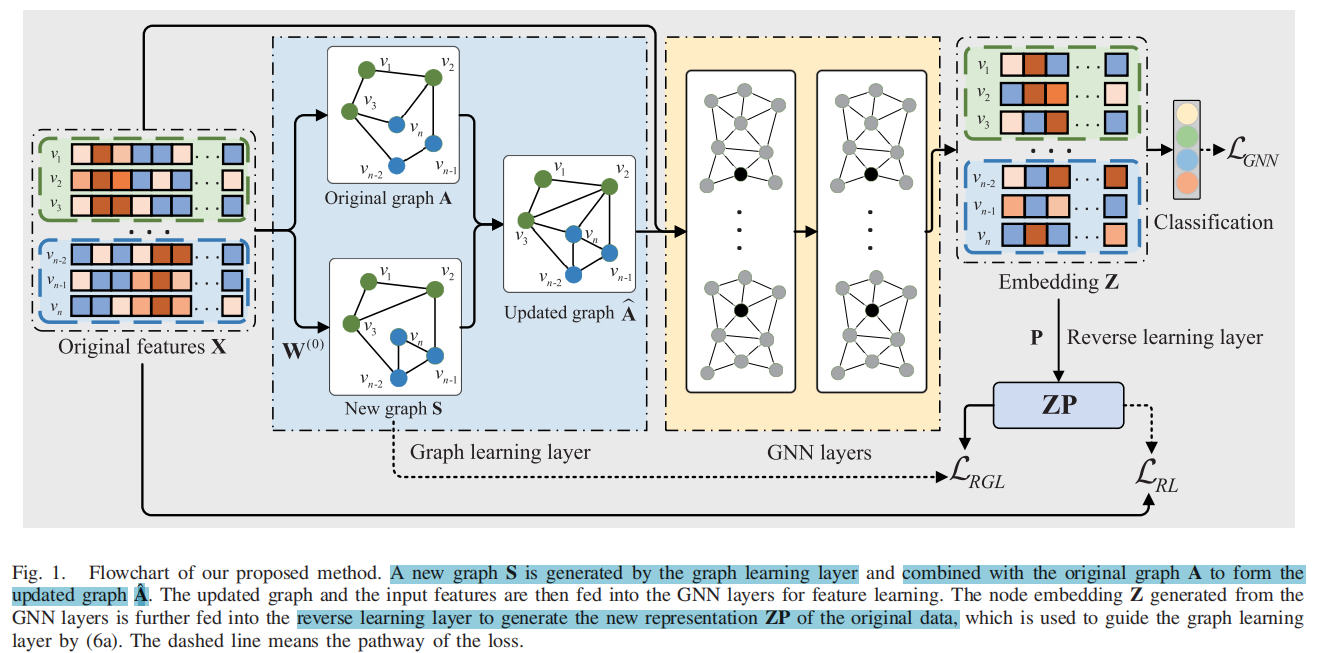
提出模型结构图:
反转图学习(对应图中含有ZP的一列)
X = { x 1 , x 2 , … , x n } ∈ R n × D \mathbf{X}=\left\{\mathbf{x}_{1}, \mathbf{x}_{2}, \ldots, \mathbf{x}_{n}\right\} \in \mathbb{R}^{n \times D} X = { x 1 , x 2 , … , x n } ∈ R n × D X \mathcal{X} X v i v_i v i z i ∈ R 1 × d \mathbf{z}_{i} \in \mathbb{R}^{1 \times d} z i ∈ R 1 × d 反转图嵌入 通过满足语义一致性和结构一致性去保护数据在本质空间的局部结构。
语义一致性保护原始语义信息,结构一致性保护数据点在输入空间X \mathcal{X} X 翻转图嵌入 z i P \mathbf{z}_{i} \mathbf{P} z i P z j P \mathbf{z}_{j} \mathbf{P} z j P v i v_i v i v j v_j v j X X X P \mathbf{P} P Z P \mathbf{ZP} ZP
在这个反转图学习中,公式5中的被改写为:
公式 6 : { L R G L : min S ∑ i j n ∥ z i P − z j P ∥ 2 2 s i j + ∥ S ∥ F 2 s.t., ∑ j = 1 n s i j = 1 , s i j > 0 , i , j = 1 , … , n L R L : min P , P T P = I ∥ X − Z P ∥ F 2 公式6:\left\{\begin{aligned}
\mathcal{L}_{\mathrm{RGL}}: & \min _{\mathbf{S}} \sum_{i j}^{n}\left\|\mathbf{z}_{i} \mathbf{P}-\mathbf{z}_{j} \mathbf{P}\right\|_{2}^{2} s_{i j}+\|\mathbf{S}\|_{F}^{2} \\
& \text { s.t., } \sum_{j=1}^{n} s_{i j}=1, \quad s_{i j}>0, i, j=1, \ldots, n \\
\mathcal{L}_{\mathrm{RL}}: & \min _{\mathbf{P}, \mathbf{P}^{T} \mathbf{P}=\mathbf{I}}\|\mathbf{X}-\mathbf{Z P}\|_{F}^{2}
\end{aligned}\right.
公式 6 : ⎩ ⎨ ⎧ L RGL : L RL : S min ij ∑ n ∥ z i P − z j P ∥ 2 2 s ij + ∥ S ∥ F 2 s.t., j = 1 ∑ n s ij = 1 , s ij > 0 , i , j = 1 , … , n P , P T P = I min ∥ X − ZP ∥ F 2
其中P T P^T P T P P P I I I L R G L \mathcal{L}_{RGL} L RG L s i j s_{ij} s ij z i \mathbf{z}_i z i z j \mathbf{z}_j z j Z Z Z v i v_i v i v j v_j v j ∥ z i P − z j P ∥ 2 2 \left\|\mathbf{z}_{i} \mathbf{P}-\mathbf{z}_{j} \mathbf{P}\right\|_{2}^{2} ∥ z i P − z j P ∥ 2 2 s i j s_{ij} s ij
L R L \mathcal{L}_{RL} L R L X \mathbf{X} X Z \mathbf{Z} Z ∥ X − Z P ∥ \|\mathbf{X}-\mathbf{Z P}\| ∥ X − ZP ∥ X X X Z P ZP ZP Z P ZP ZP
本文的方法从GNN中得到的新表征Z Z Z P P P
用于新图的相似度指标学习
在本问题出的GNN模型的第一层中,目的是优化表示两个数据点之间新表示的成对关系的新图S。使用余弦距离去定义新图S边的权重
公式 7 : s i j = cos ( x i W ( 0 ) , x j W ( 0 ) ) 公式7:s_{i j}=\cos \left(\mathbf{x}_{i} \mathbf{W}^{(0)}, \mathbf{x}_{j} \mathbf{W}^{(0)}\right)
公式 7 : s ij = cos ( x i W ( 0 ) , x j W ( 0 ) )
其中s i j s_{i j} s ij v i v_i v i v j v_j v j s i j ∈ [ 0 , 1 ] s_{i j} \in[0,1] s ij ∈ [ 0 , 1 ] W ( 0 ) ∈ R D × d ′ ( d ′ ≤ D ) \mathbf{W}^{(0)} \in \mathbf{R}^{D \times d^{\prime}}\left(d^{\prime} \leq D\right) W ( 0 ) ∈ R D × d ′ ( d ′ ≤ D ) 通过保持每个节点的前k个相邻节点的相似度(边权),并将其他节点设置为0,从而获得一个稀疏图S 。然后在对S进行归一化,使其满足∑ j = 1 n s i j = 1 , s i j > 0 \sum_{j=1}^{n} s_{i j}=1, s_{i j}>0 ∑ j = 1 n s ij = 1 , s ij > 0
在更新S的过程中,也要利用初始图A去保证S的更新能寻回缺失的边,S的更新公式可以使用下面的方式表示:
公式 8 : A ^ = ( 1 − η ) A + η S 公式8:\hat{\mathbf{A}}=(1-\eta) \mathbf{A}+\eta \mathbf{S}
公式 8 : A ^ = ( 1 − η ) A + η S
其中η \eta η S \mathbf{S} S A \mathbf{A} A A ^ \hat{A} A ^
目标函数
GNNlayer(图中图神经网络的部分)可以用下面的公式表示:
公式 9 : Z = σ ( A ^ σ ( A ^ X W ( 1 ) ) W ( 2 ) ) 公式9:\mathbf{Z}=\sigma\left(\hat{\mathbf{A}} \sigma\left(\hat{\mathbf{A}} \mathbf{X} \mathbf{W}^{(1)}\right) \mathbf{W}^{(2)}\right)
公式 9 : Z = σ ( A ^ σ ( A ^ X W ( 1 ) ) W ( 2 ) )
W ( 1 ) \mathbf{W}^{(1)} W ( 1 ) W ( 2 ) \mathbf{W}^{(2)} W ( 2 )
目标函数可以用下面的公式表示:
公式 10 : L = L G N N + β L R G L + γ L R L 公式10:\mathcal{L}=\mathcal{L}_{\mathrm{GNN}}+\beta \mathcal{L}_{\mathrm{RGL}}+\gamma \mathcal{L}_{\mathrm{RL}}
公式 10 : L = L GNN + β L RGL + γ L RL
β \beta β γ \gamma γ L G N N ⇒ L R G L ⇒ L R L \mathcal{L}_{\mathrm{GNN}} \Rightarrow \mathcal{L}_{\mathrm{RGL}} \Rightarrow \mathcal{L}_{\mathrm{RL}} L GNN ⇒ L RGL ⇒ L RL
先固定GNN的参数W ( 1 ) \mathbf{W}^{(1)} W ( 1 ) W ( 2 ) \mathbf{W}^{(2)} W ( 2 ) P \mathbf{P} P
然后固定参数P \mathbf{P} P W ( 0 ) \mathbf{W}^{(0)} W ( 0 ) W ( 1 ) \mathbf{W}^{(1)} W ( 1 ) W ( 2 ) \mathbf{W}^{(2)} W ( 2 )
外部数据样本拓展
查询扩展(QE)将不可见数据点的特征分配为其K个最近邻的加权平均值,来解决外部数据样本的问题。但是这个方法受限于从高维原始数据中构建的最近邻节点的质量 。
本文通过图学习层,提出优化最近邻节点的选择,具体来说,在整个网络训练完成后,可以得到图学习层的W ( 0 ) \mathbf{W}^{(0)} W ( 0 ) W ( 1 ) \mathbf{W}^{(1)} W ( 1 ) W ( 2 ) \mathbf{W}^{(2)} W ( 2 ) P \mathbf{P} P x q \mathbf{x}_q x q W ( 0 ) \mathbf{W}^{(0)} W ( 0 ) x q \mathbf{x}_q x q X t r a i n \mathbf{X}_{train} X t r ain
公式 11 : S q = cos ( x q W ( 0 ) , X train W ( 0 ) ) 公式11:\mathbf{S}_{q}=\cos \left(\mathbf{x}_{q} \mathbf{W}^{(0)}, \mathbf{X}_{\text {train }} \mathbf{W}^{(0)}\right)
公式 11 : S q = cos ( x q W ( 0 ) , X train W ( 0 ) )
然后通过下面的公式选择其邻居
公式 12 : N q ← topk ( S q ) 公式12:\mathcal{N}_{q} \leftarrow \operatorname{topk}\left(\mathbf{S}_{q}\right)
公式 12 : N q ← topk ( S q )
在一个隐藏层中,不确定数据节点的表示是k个最近邻的邻居的加权平均值和其在前一层的表示f p ( l ) \mathbf{f}^{(l)}_p f p ( l )
公式 13 : H q ( l ) = σ ( W ( l ) ( ∑ x p ∈ N q s q p f p ( l ) + H q ( l − 1 ) ) ) 公式13:\mathbf{H}_{q}^{(l)}=\sigma\left(\mathbf{W}^{(l)}\left(\sum_{\mathbf{x}_{p} \in \mathcal{N}_{q}} \mathbf{s}_{q p} \mathbf{f}_{p}^{(l)}+\mathbf{H}_{q}^{(l-1)}\right)\right)
公式 13 : H q ( l ) = σ W ( l ) x p ∈ N q ∑ s qp f p ( l ) + H q ( l − 1 )
本文的方法解决外部数据样本的主要思想是从数据点的本质空间中发现不可见数据点的邻居,并使用高质量的自适应地更新。本文也通过在训练过程中生成一个易于理解的映射函数去预测不可见数据点,本文的方法从公式6中的新表示学习潜在图结构。
实验方式:
对5个任务(节点有监督分类,使用外部数据拓展的有监督学习节点分类,随机边缘攻击,连接预测,图像检索)上使用11个公开数据集与现有12个方法进行对比实验,主要指标是分类的准确率(accuracy)。
在消融实验中
反转图学习的有效性:使用反转图学习与QE方法结合提出了一种新的方法,用于解决外部样本问题,结果是比原本的QE效果要好。
参数敏感度分析:
在之前提到的生成新图S的过程中,设置的最近邻超参数k,对于这个模型的效果是敏感的
对使用初始图A和新图S进行更新时的超参数η \eta η
损失函数中的β \beta β γ \gamma γ