论文名称:Multi-VAE: Learning Disentangled View-common and View-peculiar Visual Representations for Multi-view Clustering
作者:Jie Xu; Yazhou Ren; Huayi Tang; Xiaorong Pu; Xiaofeng Zhu; Ming Zeng; Lifang He
年份:2021-10
期刊或会议:2021 IEEE/CVF International Conference on Computer Vision (ICCV)
代码:https://github.com/SubmissionsIn/Multi-VAE
原文摘要
Multi-view clustering, a long-standing and important research problem, focuses on mining complementary information from diverse views. However, existing works often fuse multiple views’ representations or handle clustering in a common feature space, which may result in their entanglement especially for visual representations. To address this issue, we present a novel VAE-based multi-view clustering framework (Multi-VAE) by learning disentangled visual representations. Concretely, we define a view-common variable and multiple view-peculiar variables in the generative model. The prior of view-common variable obeys approximately discrete Gumbel Softmax distribution, which is introduced to extract the common cluster factor of multiple views. Meanwhile, the prior of view-peculiar variable follows continuous Gaussian distribution, which is used to represent each view’s peculiar visual factors. By controlling the mutual information capacity to disentangle the view common and view-peculiar representations, continuous visual information of multiple views can be separated so that their common discrete cluster information can be effectively mined. Experimental results demonstrate that Multi-VAE enjoys the disentangled and explainable visual representations, while obtaining superior clustering performance compared with state-of-the-art methods.
任务与存在问题
多视图聚类关注于从多个视图中挖掘互补信息,但现有的工作仍然存在一些问题:
- 现有的工作大豆融合多视图特征和在一个公共特征空间中处理聚类,这些都有可能使得不同视图的不同视觉表示缠绕在一起。
- 现有多视图聚类的方法核心瓶颈是其高复杂性,这使得处理大规模数据聚类任务不现实。
主要工作
提出一个通过学习离散视觉特征的新颖的基于VAE(变分自编码器)的多视图聚类框架(Multi-VAE)。在生成模型中定义视同公用变量和视图特定变量。其中视图公用变量的先验近似准许Gumbel Softmax分布,用于提取多视图中的公共聚类因子。同时视图特定变量的先验服从高斯分布,用于表示每个视图的特定视觉因子。通过控制交互信息的容量去离散化视图公共表示和视图特定表示,使得连续的多视图视觉信息被分离,以便于有效地挖掘他们共同的离散信息。
理论基础
- 聚类的目的是使用相似模式或特征将数据项分配到相同的组中。
- 深度学习的聚类方法客服了浅层模型的缺点,在集群性能上取得了相当大的进展。
- 多视图聚类可以得到更加包含在多视图数据中更加复杂的特征。
- 聚类信息是离散的,其是所有视图的最大公共视觉信息的一个抽象
- 每个视图的特有视觉信息是连续的,他们都对聚类有不同的影响
创新点
- 提出了一个称为Multi-view的新颖的多视图VAE框架,其引入视图公共变量和视图的特有变量,去挖掘离散的聚类因子和连续的视觉因子。
- 在这个模型中分离了所有视图的公共聚类表示和每个视图的特定视觉表示。通过这个方式在挖掘他们用于聚类的互补信息时减弱了多视图多余信息的干扰。
- Multi-VAE与其他忙伐相比,具有明显的聚类性能,此外他的复杂度与数据大小呈线性增长。这是第一次尝试通过学习离散表征和解释表征实现MVC。
提出的方法
模型结构图
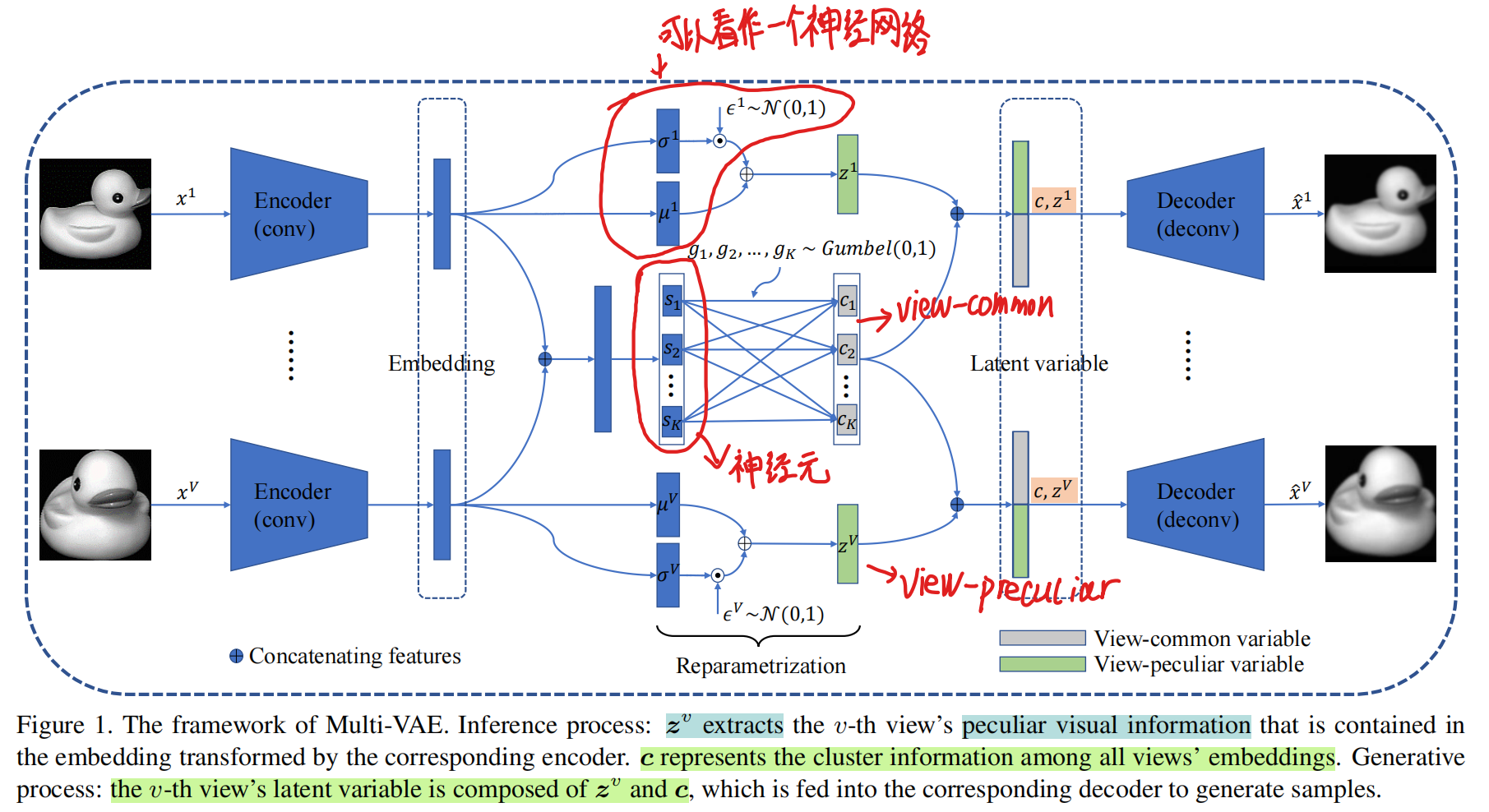
结构
给定多视图图像数据集{xi1,xi2,...,xiV}i=1N,每个样本有V个含有不同视觉信息的视图,N为数据的大小。多视图聚类的目标是将这些数据分成K个簇。
因为本文的动机是通过VAE学习多个视图的离散表示,在这里引入了独立的视图公共变量c∈RK,视图特定变量{z∈RZv}v=1V去建模多视图数据。通过联合概率得到生成的模型:
公式1:p(xv,zv,c)=p(xv∣zv,c)p(zv,c)=p(xv∣zv,c)p(zv)p(c),
其中视图公共变量c被所有视图共享,并表示他们的聚类信息。对于第v个视图,视图特定变量zv表示特定的数据信息(角度,大小,风格等)。让{xv}表示所有视图数据{x1,x2,…,xV},那么,c和zv的后验概率(posterior)可以分别用p(c∣{xv})和p(zv∣xv)表示。考虑到在VAE中计算完整的后验概率是苦难的,所以使用qϕ(c∣{xv})和qϕv(zv∣xv)进行参数化,通过ϕ和ϕv去近似后验概率。
推理过程
在推理过程中,将所有的嵌入特征拼接在一起以学习他们的公共特征(图中Embeding右边加号的位置)。设置K个神经元s={s1,s2,…,sK}(图中的s部分)得到视图公共语义变量c。其中c是一个one-hot编码表示。由于离散随机变量对神经网络的参数是不可微的,所以将视图公共变量的先验设置为独立聚云Gumbel Softmax分布的乘积,即p(c)=p(c1)p(c2)…p(cK),其中p(ck)∼Gumbel(0,1)。因此,近似的后验概率qϕ(c∣{xv})可以表示为:
公式2:qϕ(c∣{xv})=k=1∏Kqϕ(ck∣{xv}).
根据Gumbel-Max重构参数技巧,公式2可以进一步表示为
公式3:qϕ(ck∣{xv})=G(s)=∑i=1Kexp((logsi+gi)/τ)exp((logsk+gk)/τ)
其中gk∼Gumbel(0,1)和τ是活性参数,用于控制松弛。假设其他视觉信息是连续的,视图特特定变量的先验概率是标准正态分布p(zv)∼N(0,I),后验概率qϕv(zv∣xv)可以被分解的高斯分布参数化为:
公式4:qϕv(zv∣xv)=i=1∏Zvqϕv(ziv∣xv).
根据重构参数技巧,公式4可以等价于下面的式子
公式5:qϕv(ziv∣xv)=N(μiv,(σiv)2)=μiv+σivϵiv,
其中ϵiv∼N(0,1),μiv和σiv通过以第v个视图的嵌入特征为输入的神经网络进行参数化。
生成过程
每个视图的潜在变量包含视图公共变量c和视图特定变量zv。第v个视图的解码器输出(可能性)可以表示为:
公式6:x^v=pθv(xv∣zv,c)
在这个结构中,参数ϕ,{ϕ1,ϕ2,…,ϕV}和ϕ,{ϕ1,ϕ2,…,ϕV}是部分共享的。
变分下界
变分推理的目标是最大化观察到的多视图数据的可能性函数,通过Jensen不等式,模型的log可能性可以用下面的公式表示:
公式7:v=1∑Vlogp(xv)=v=1∑Vlog∫zvc∑p(xv,zv,c)dzv≥v=1∑VEq(zv,c∣{xv})[logq(zv,c∣{xv})p(xv,zv,c)]=v=1∑VLELBO(xv)
其中LELBO(xv)是第v个视图的证据下界(ELBO,evidence lower bound)。在变分推理中,最大化ELBO与最大化可能性是等价的。给定p(xv,zv,c)=p(xv∣zv,c)p(zv,c),每个视图的ELBO可以使用下面的公式表示:
公式8:LELBO(xv)=Eq(zv,c∣{xv})[logp(xv∣zv,c)]−DKL(q(zv,c∣{xv})∥p(zv,c))
假设视图公共变量和视图特定变量是条件独立的,则有q(zv,c∣{xv})=q(zv∣xv)q(c∣{xv}),先验概率p(zv,c)=p(zv)p(c)。KL散度DKL可以被分为两部分:
公式9:DKL(q(zv,c∣{xv})∥p(zv,c))=Eq(zv,c∣{xv})[logp(zv,c)q(zv,c∣{xv})]=Eq(zv∣xv)Eq(c∣{xv})[logp(zv)p(c)q(zv∣xv)q(c∣{xv})]=Eq(zv∣xv)Eq(c∣{xv})[logp(zv)q(zv∣xv)]+Eq(zv∣xv)Eq(c∣{xv})[logp(c)q(c∣{xv})]=DKL(q(zv∣xv)∣∣p(zv))+DKL(q(c∣{xv})∥p(c))
通过这个方式,c和zv的KL散度项被分离,这个设计可以用于视图离散化公共表示和视图特定表示。对于第v个视图的目标最大化过程变成:
公式10:LELBO(xv)=Eq(zv,c∣{xv})[logp(xv∣zv,c)]−DKL(q(zv∣xv)∣∣p(zv))−DKL(q(c∣{xv})∥p(c))
学习分离表征
KL散度项是潜在变量和数据之间的交互信息的上界。为了离散化模型的视图公共表示和视图特定表示,每个潜在变量应该编码更多的变量信息。因此在公式10中KL散度项的通道容量应该逐渐增加,定义用于视图公共变量和视图特定变量的KL散度项的控制容量分别为Cc和Cz。第v个视图的ELBO可以被表示为:
公式11:LELBO(xv)=Eq(zv,c∣{xv})[logp(xv∣zv,c)]−β∣DKL(q(c∣{xv})∥p(c))−Cc∣−β∣DKL(q(zv∣xv)∥p(zv))−Cz∣
其中β是权衡置信度。当p(c)为均匀类别分布(uniform categorical distribution)时,对于视同公共变量的KL散度是有界的:
公式12:DKL(q(c∣{xv})∥p(c))=i=1∑Kqilogpiqi=i=1∑Kqilog1/Kqi=−H(q)+logK≤logK
其中H表示熵,基于这个,令Cc=logK,他控制了c中编码的变分信息的最大容量。考虑不同的视图有不同的数据重建损失规模,因此进一步引入β去平衡所有视图的离散性。对于第v个视图,权重可以计算为:
公式13:βv=βmaxvEq(zv,c∣{xv})[logp(xv∣zv,c)]Eq(zv,c∣{xv})[logp(xv∣zv,c)].
总共的损失函数由三个部分组成:
公式14:Lloss =−∑v=1VLELBO(xv)=∑v=1Vβv∣DKL(q(c∣{xv})∥p(c))−Cc∣+∑v=1Vβv∣DKL(q(zv∣xv)∣∣p(zv))−Cz∣−∑v=1VEq(zv,c∣{xv})[logp(xv∣zv,c)]
其中,第一项和第二项的优化用于学习离散的视图公共表示和视图特定表示。第三项是可能性项,优化去保持VAE的重构质量。
Multi-VAE-C
从结构图中可以看出,所有的特征可以被分为{c,z1,z2,…,zV},每一组{c,zv}用于重建特征。通过这种方式,每个视图的特定视觉信息可以通过视觉特定表示zv提取,反过来,所有视图的共同聚类信息也可以通过视图公共表示c提取。因为c是one-hot形式的近似表示,第i个样本的聚类预测可以通过下面的式子进行计算:
公式15:yi=argjmax(cj)=argjmax(qϕ(cj∣{xiv})).
Multi-VAE-CZ
给定多视图视觉信息在用于聚类时是互补的,将分离的特征缩放到[0,1],拼接他们去形成一个全局的潜在表示[c;{zv}],然后将其输入到K-means中,从而获得另一个聚类预测。
优化Multi-VAE的算法
输入:多视图数据集{xi1,xi2,...,xiV}i=1N,聚类数K,权衡置信度β,最大控制容量Cz,Cc=logK,随机初始化参数ϕ和{ϕv,θv}v=1V
while 没有到达最大迭代次数 do:
- 通过编码器计算{sk}k=1K和{μv,δv}v=1V
- 使用带有参数化技巧的公式2和公式4推理qϕ(c∣{xv})和qϕv(zv∣xv)
- 通过解码器生成{pθv(xv∣zv,c)}v=1V
- 通过最小化公式14更新ϕ和{ϕv,θv}v=1V
end while
输出:离散的表征c和{zv}v=1V
实验方式
使用指标:聚类准确率ACC,归一化互信息NMI,调整兰德系数ARI,纯度Purity
- 在MNIST,Fashion,Product以及COIL上对比了Multi-VAE和其他SOTA的方法
- 可视化视图公共表征c和一些视图的视图特定表征zv,证实模型确实将这些特征离散化了
- 展示使用不同的视图表示(公共表示和每一个视图的特定表示)随着迭代次数的增加NMI指标的变化图,说明了公共表示c用于聚类的有效性。同时可视化了聚类过程。
- 通过使用提出的结构加上vanilla VAE,不使用控制容量,只使用视图特定表征的控制容量Cz,只使用视图公共表征的控制容量Cc,以及完整的结构进行消融实验。
- 分析了权衡置信度β和视图特定变量的最大控制容量Cz的敏感度,结论是这两个参数对模型并不敏感。







