「论文阅读(简)」Vision GNN: An Image is Worth Graph of Nodes
期刊:Vision GNN: An Image is Worth Graph of Nodes
作者:Kai Han, Yunhe Wang, Jianyuan Guo, Yehui Tang, Enhua Wu
时间:2022. 7
期刊:arxiv
原文摘要
Network architecture plays a key role in the deep learning-based computer vision system. The widely-used convolutional neural network and transformer treat the image as a grid or sequence structure, which is not flexible to capture irregular and complex objects. In this paper, we propose to represent the image as a graph structure and introduce a new Vision GNN (ViG) architecture to extract graph level feature for visual tasks. We first split the image to a number of patches which are viewed as nodes, and construct a graph by connecting the nearest neighbors. Based on the graph representation of images, we build our ViG model to transform and exchange information among all the nodes. ViG consists of two basic modules: Grapher module with graph convolution for aggregating and updating graph information, and FFN module with two linear layers for node feature transformation. Both isotropic and pyramid architectures of ViG are built with different model sizes. Extensive experiments on image recognition and object detection tasks demonstrate the superiority of our ViG architecture. We hope this pioneering study of GNN on general visual tasks will provide useful inspiration and experience for future research.
理论基础
不同的网络结构会使用不同的方式处理输入图片,如下图:
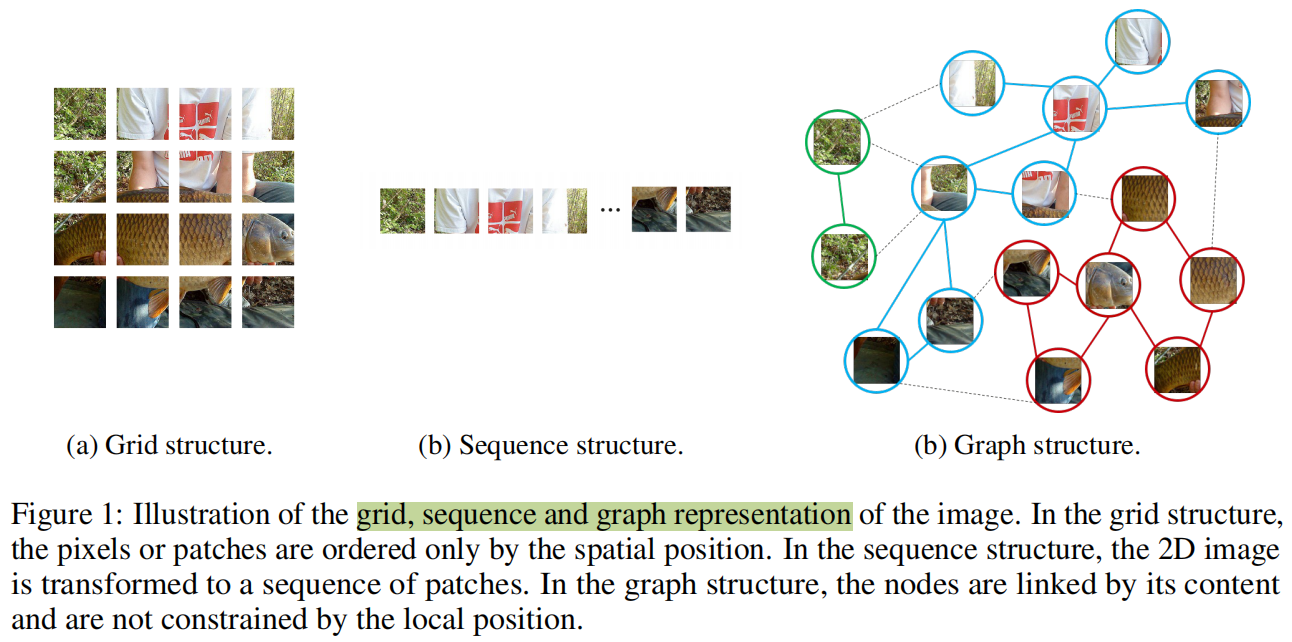
任务与存在问题
- 对于目标识别任务,因为目标不是方形而是不规则的,所以通常在之前的网络中使用的网格和序列结构在处理图像上是冗余和不灵活的。
- GCNs中的过度平滑现象(over-smoothing phenomenon)会降低节点特征的独特性,导致视觉识别性能下降。
主要工作和创新点
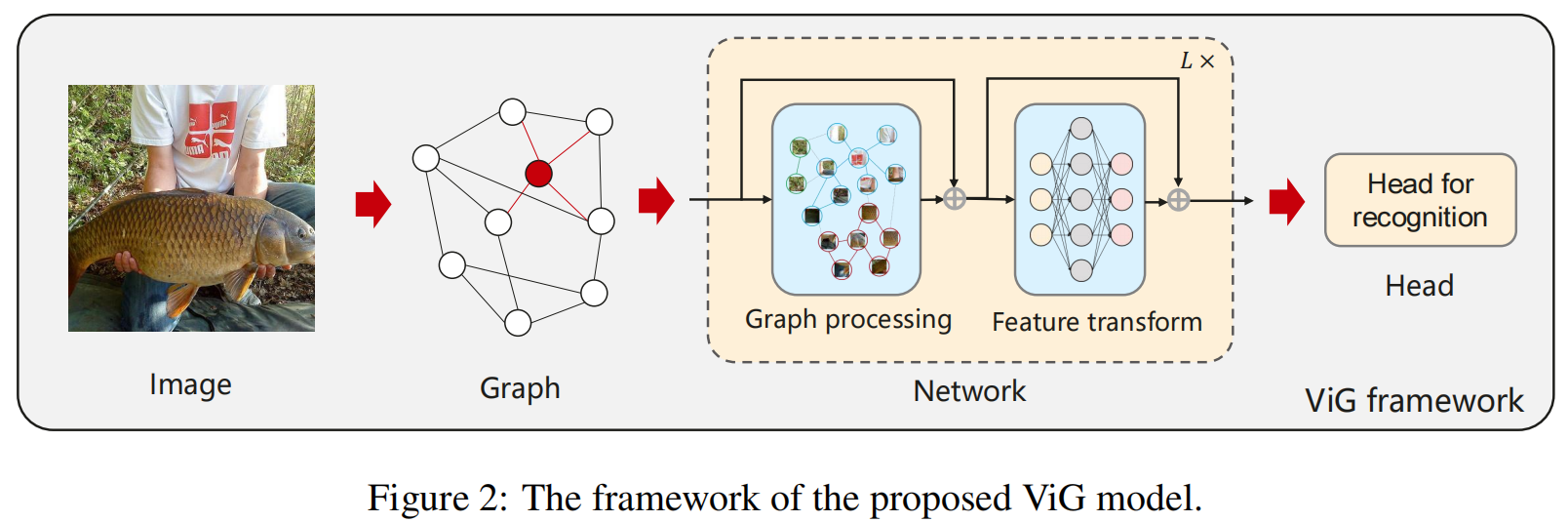
基于图的图像表示,作者构建了数据图神经网络(ViG)用于视觉任务,其将图像分成一定数量的patch,并将这patch视为一个节点。在构建完图后,使用ViG模型转化和提取所有节点中的信息。ViG可以包括两个部分:Grapher和FFN(feed-forward network)。
Grapher基于图卷积构造并用于图信息处理。为了减轻传统GNN模型的过度平滑现象,使用FFN来进行节点信息转化和激励节点的多样性。
提出的方法
ViG Block
图结构的图像
对于一张的图像,将其分成N个patch。通过转化每个patch为一个特征向量,则,其中是特征的维度,。这些特征可以被认为是无向的节点集合,可以用表示。对于每一个节点,找到他的K个最接近的邻居,为所有的直接添加一条从到的边。然后得到一个图,其中表示所有的边。使用表示为图构建过程。
图像图表示的优点为:
- 图是一种广义的数据结构,网格和序列可以看做是一种特殊的图
- 对比于网格和序列图建模图像中不规则的复杂对象是更加灵活的
- 一个对象可以看成一个组件的组成部分(比如人由四支,头和躯干构成),图结构能够构建这些部分的连接。
- GNN的先进研究可以用于解决视觉任务
图像图表示的缺点(我自己的拙见):
- 很明显,如果将图像分成多个补丁的话,假设我们拍摄一张人的图像A,然后可以很好地构建一个图来描述他,但是,对于同样一个人,现在我们用广角拍摄这个人形成图像B(拍摄距离变远,人的形状缩小),如果我们还按照之前分补丁的方式,那么这个补丁对于人的特征是不是就会和之前不一样。如果再按照相同的方式构建图来描述图片,对于同一个人,只是设置了不同的拍摄距离,就会使得这个图的结构质量变低。
- 当然如果说上面的说法是吹毛求疵的话,也是有道理的,就是只缩小一点特征的变化也不应该变化太大,那我再极限一点,换了一个直升机上的摄影机进行拍摄,假设人的大小正好变成只有一个补丁能覆盖,但是其分辨率仍然没有变化,那么如果按照之前的方式建图得到的无用节点就会变得很多,很难说这样的一个图还时一个质量比较高的图。
- 因此感觉还得用什么方式,在构建图的时候动态适应一下图像的情况,比如引入注意力机制,在构图前将最吸引人的部分重点缩放或者加权之类的操作,当然注意力机制并不是万能的,有时候效果也比较差。这是我目前觉得这种建图方法仍然存在的一个问题。
- 或者按照这种方式建图的时候,在构建边计算权值时,设置一个阈值,如果边的权重低于某个值就直接舍弃这个边,然后建图完成后,观察是否存在无度的节点,将其删除。但是这又会导致一个问题,就是输入不固定,对于代码实现可能存在问题。也可以换种思路,就是给这样的节点赋值特征为0,或者添加权重降低他的表示能力。
图级别处理(Graph-level processing)
一般来说,首先是从特征开始,首先构造一个基于特征的图:。图卷积层可以通过聚合他邻居节点的特征来交换节点之间的信息。具体来说,图卷积的操作可以表示为:
其中和分别是聚合的可学习权重和更行操作的权重。更准确来说,聚合操作通过邻居节点的聚合特征计算节点的表示。更新操作进一步合并聚合特征:
其中是的邻居节点集合,在这里使用max-relative graph convolution实现其简单和高效:
其中省略了bias,上述的graph-level processing可以被描述为:
现在进一步介绍图卷积的多头更新操作,聚合特征手写被分到h个头,比如,然后这些头分别使用不同的权重进行更新。所有的头能够并行地进行更新,然后concate他们的结构,最终得到下面的公式:
多头更新操作允许模型更新多个表示子空间中的信息,这有益于特征的多样性。
ViG block
为了减轻过度平滑的问题,在ViG block中引入了更多的特征转化和非线性激活。在图卷积前后采用一个线性层,将节点特征映射到同一个域中,增加特征多样性。在图卷积之后会引入一个非线性激活函数以避免层坍塌。本文将更新的模块称为Grapher,给定输入特征,Grapher可以表达为:
其中和是全连接层的权重,是激活函数,可以是ReLU和GeLU,其中bias被省略了。
为了进一步提高特征转换能力和缓解过度平滑现象,在每个节点上利用前馈网络(FFN),FFN是一个含有两个全连接层的简单多层感知机(MPL)
其中和是全连接层的参数,省略bias。FFN的隐藏维度通常比要大。在Grapher和FFN中,在每一个全连接层或者图卷积层之后都会跟一个batch normalization,他在公式6和7中省略了。Grapher和FFN的组合构成了ViG block,并称为构建网络的基本单元。基于图像的图表示和ViG block,构建了ViG网络用于视觉任务如下图所示:
网络结构
在本文中主要提出了各向同性的ViG结构和金字塔的ViG结构
各向同性ViG结构(Isotropic architecture)
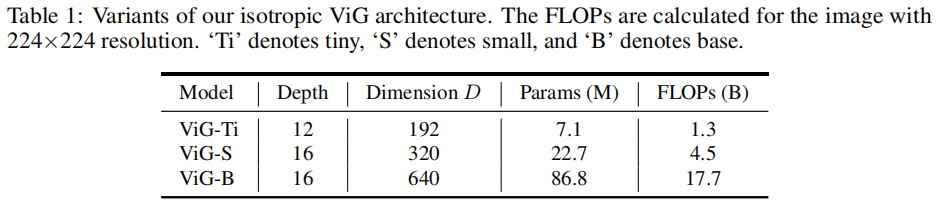
这个结构意味着主体再整个网络中具有相同大小和形状的特征。本文建立了三种不同模型尺寸的各向同性ViG结构,分别是ViG-Ti,S和B。节点的数量设置为。为了逐渐扩大receptive field,在这三种模型中,随着隐藏层的深度变深,相邻节点K的数量从9个线性增加到18个。头的数量默认设置为,具体细节如下表:
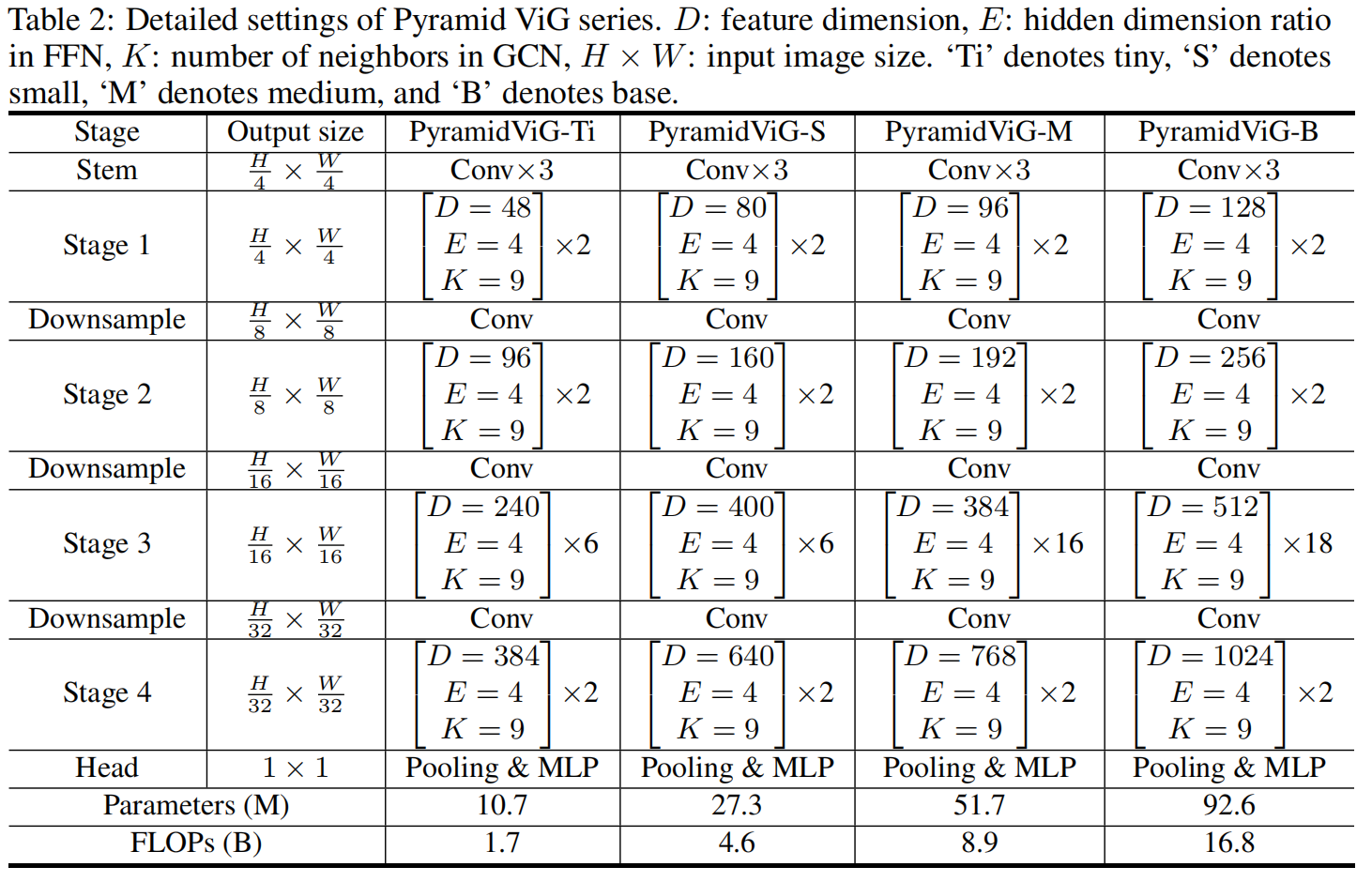
金字塔ViG结构(Pyramid architecture)
这个结构随着层数变深,通过提取空间尺寸逐渐缩小的特征,考虑了图像的多尺度特征。因此,本文使用最先进的设计,构建了4种版本的金字塔ViG模型,具体细节如下表:
位置编码(positional encoding)
为了表示节点的位置信息,为每一个节点特征添加了一个位置编码向量:
其中。这个绝对的位置编码被用于各向同性结构和金字塔结构的ViG。对于金字塔结构的ViG,作者进一步引入了相对位置编码,正如Swin Transformer设计的那样。节点和的相对位置距离为,并将其加入到特征距离中,用于构造图。
实验方式
任务:图像识别和目标检测
数据集:ImageNet,COCO 2017
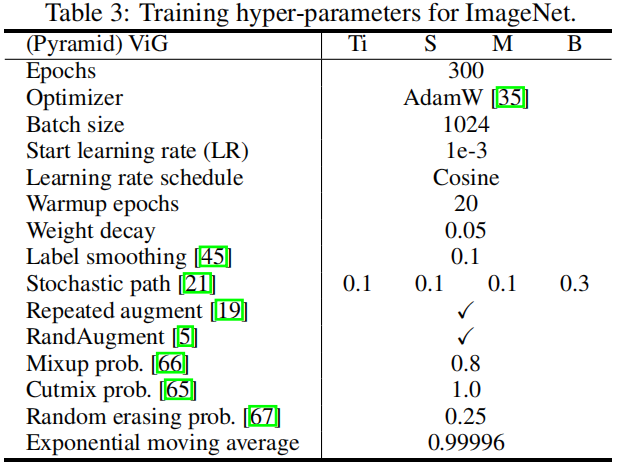
训练参数:
ImageNet的结果
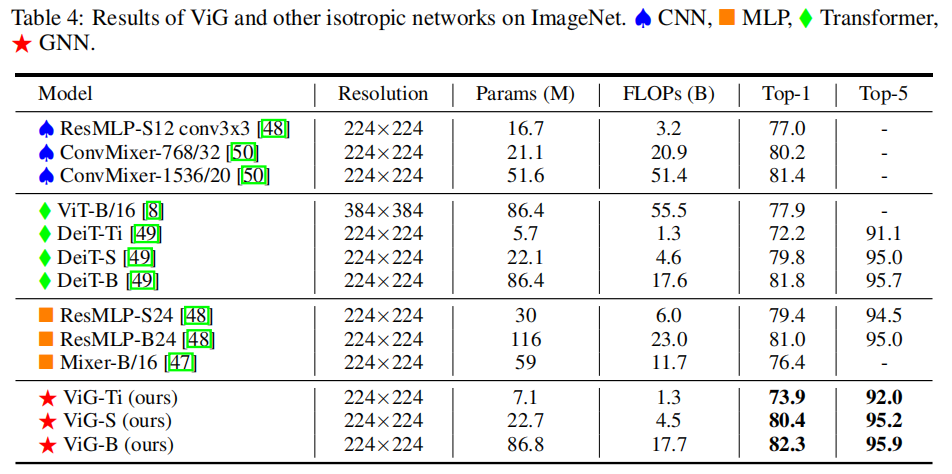
各向异性ViG与其他各向异性模型对比的实验结果如下:
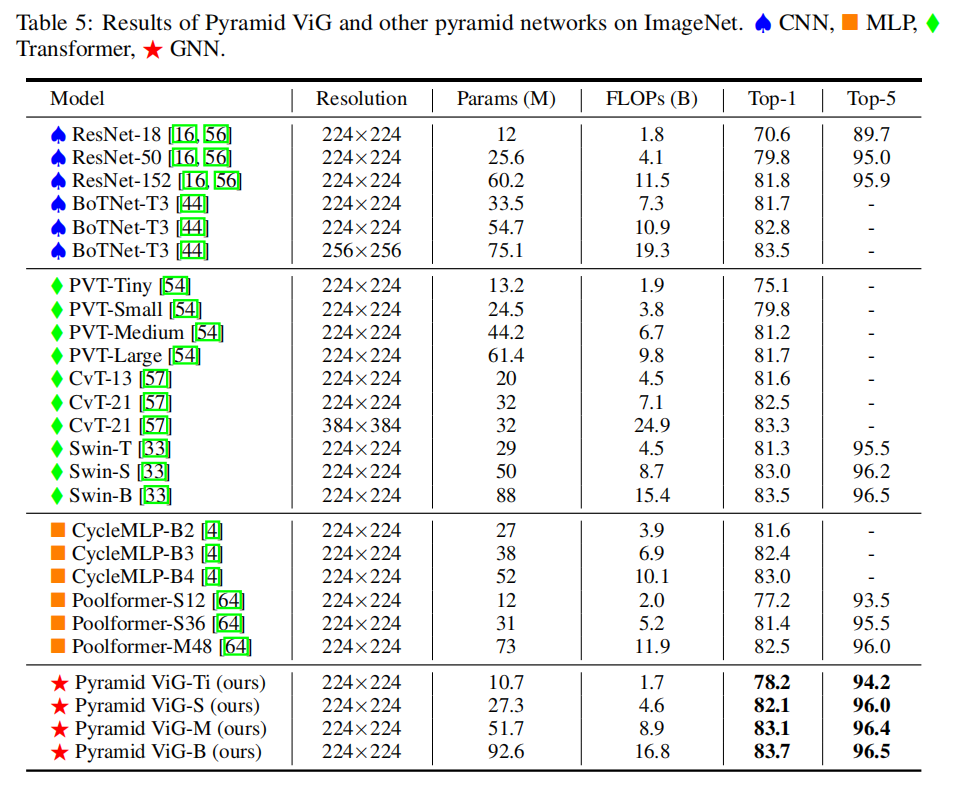
金字塔ViG与其他金字塔模型对比的实验结果如下:
消融实验
- 不同类型的图卷积方式,比如EdgeConv,GIN,GraphASGE,Max-Relative GraphConv
- 对是否使用Graph和FFN进行消融实验
- 对在构建图像的图结构时设置的最近邻邻居数K进行不同数值的分析(调整这个超参数的数值)
- 在Graph-level processing中更新聚合特征时,设置的多头更新的超参数h进行不同数值的分析(调整这个超参数)
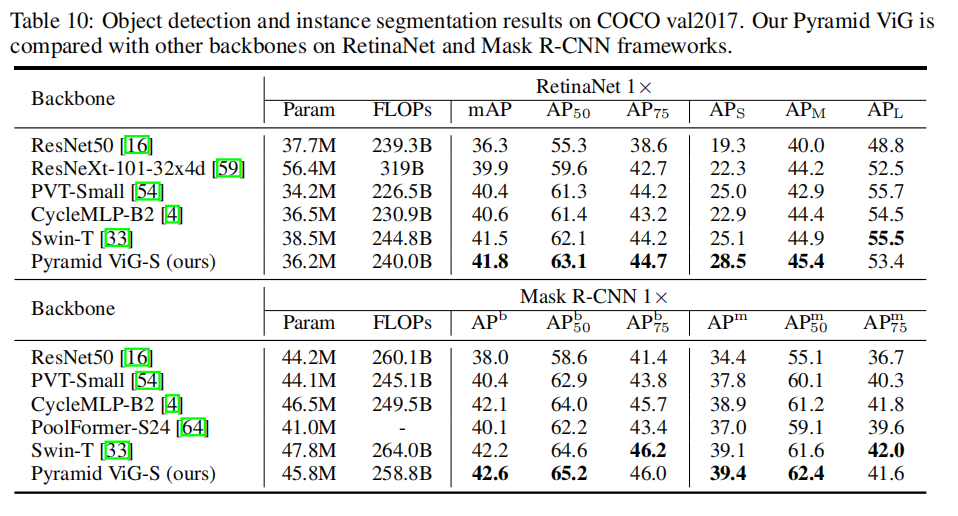
目标检测的结果
使用ViG去替换RetinaNet和Mask R-CNN的主干网络