论文名称:Dual Contrastive Prediction for Incomplete Multi-View Representation Learning
作者:Yijie Lin; Yuanbiao Gou; Xiaotian Liu; Jinfeng Bai; Jiancheng Lv; Xi Peng
期刊:IEEE Transactions on Pattern Analysis and Machine Intelligence
时间:2022-8
原文摘要
In this article, we propose a unifified framework to solve the following two challenging problems in incomplete multi-view representation learning: i) how to learn a consistent representation unifying different views, and ii) how to recover the missing views. To address the challenges, we provide an information theoretical framework under which the consistency learning and data recovery are treated as a whole. With the theoretical framework, we propose a novel objective function which jointly solves the aforementioned two problems and achieves a provable suffificient and minimal representation. In detail, the consistency learning is performed by maximizing the mutual information of different views through contrastive learning, and the missing views are recovered by minimizing the conditional entropy through dual prediction. To the best of our knowledge, this is one of the fifirst works to theoretically unify the cross-view consistency learning and data recovery for representation learning. Extensive experimental results show that the proposed method remarkably outperforms 20 competitive multi-view learning methods on six datasets in terms of clustering, classifification, and human action recognition. The code could be accessed from https://pengxi.me .
理论基础
多视图表征学习(MVRL)的目的是学习一个函数f f f
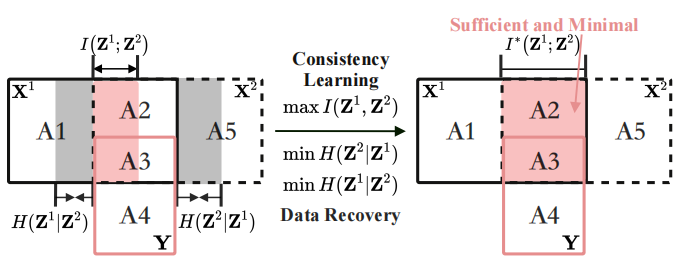
在上图X 1 \mathbf{X}^1 X 1 X 2 \mathbf{X}^2 X 2 Z 1 \mathbf{Z}^1 Z 1 Z 2 \mathbf{Z}^2 Z 2 X 1 = A 1 ∪ A 2 ∪ A 3 \mathbf{X}^1=\mathrm{A} 1 \cup \mathrm{A} 2 \cup \mathrm{A} 3 X 1 = A 1 ∪ A 2 ∪ A 3 X 2 = A 2 ∪ A 3 ∪ A 3 \mathbf{X}^2=\mathrm{A} 2 \cup \mathrm{A} 3 \cup \mathrm{A} 3 X 2 = A 2 ∪ A 3 ∪ A 3 ( Y = A 3 ∪ A 4 ) (\mathbf{Y}=\mathrm{A} 3 \cup \mathrm{A} 4) ( Y = A 3 ∪ A 4 ) A 1 ( ( H ( X 1 ∣ X 2 ) ) ) A1(\left(H\left(\mathbf{X}^1 \mid \mathbf{X}^2\right)\right)) A 1 ( ( H ( X 1 ∣ X 2 ) ) ) A 5 ( H ( X 2 ∣ X 1 ) ) A5\left(H\left(\mathbf{X}^2 \mid \mathbf{X}^1\right)\right) A 5 ( H ( X 2 ∣ X 1 ) ) X 1 \mathbf{X}^1 X 1 X 2 \mathbf{X}^2 X 2 A 2 ( I ( X 1 ; X 2 ∣ Y ) ) \mathrm{A} 2\left(I\left(\mathbf{X}^1 ; \mathbf{X}^2 \mid \mathbf{Y}\right)\right) A 2 ( I ( X 1 ; X 2 ∣ Y ) ) A 3 ( I ( X 1 ; X 2 ; Y ) ) \mathrm{A} 3\left(I\left(\mathbf{X}^1 ; \mathbf{X}^2 ; \mathbf{Y}\right)\right) A 3 ( I ( X 1 ; X 2 ; Y ) ) X 1 \mathbf{X}^1 X 1 X 2 \mathbf{X}^2 X 2 A 3 A3 A 3 A 2 A2 A 2 A 4 ( H ( Y ∣ X 1 , X 2 ) ) A4\left(H\left(\mathbf{Y} \mid \mathbf{X}^1, \mathbf{X}^2\right)\right) A 4 ( H ( Y ∣ X 1 , X 2 ) )
本文分别使用互信息(红色的面积)I ( Z 1 ; Z 2 ) I\left(\mathbf{Z}^1 ; \mathbf{Z}^2\right) I ( Z 1 ; Z 2 ) H ( Z i ∣ Z j ) H\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right.) H ( Z i ∣ Z j ) I ( Z 1 ; Z 2 ) I\left(\mathbf{Z}^1 ; \mathbf{Z}^2\right) I ( Z 1 ; Z 2 ) H ( Z i ∣ Z j ) H\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right) H ( Z i ∣ Z j ) A 3 ∈ Z i \mathrm{A} 3 \in \mathbf{Z}^i A 3 ∈ Z i ( A 1 ∪ A 5 ) ∉ Z i (\mathrm{A} 1 \cup \mathrm{A} 5) \notin \mathbf{Z}^i ( A 1 ∪ A 5 ) ∈ / Z i A 2 ∈ Z i A2 \in \mathbf{Z}^i A 2 ∈ Z i
充分的representation指为下游任务学习了足够的信息
最小的representation指所有与任务无关的信息都以一个固定的间隙被删除
任务与存在的问题
不完整视图问题(IMP)需要解决两个问题
如何从不同的视图中学习一致性表征
如何在不完整的数据中恢复缺失的视图
主要工作和创新点
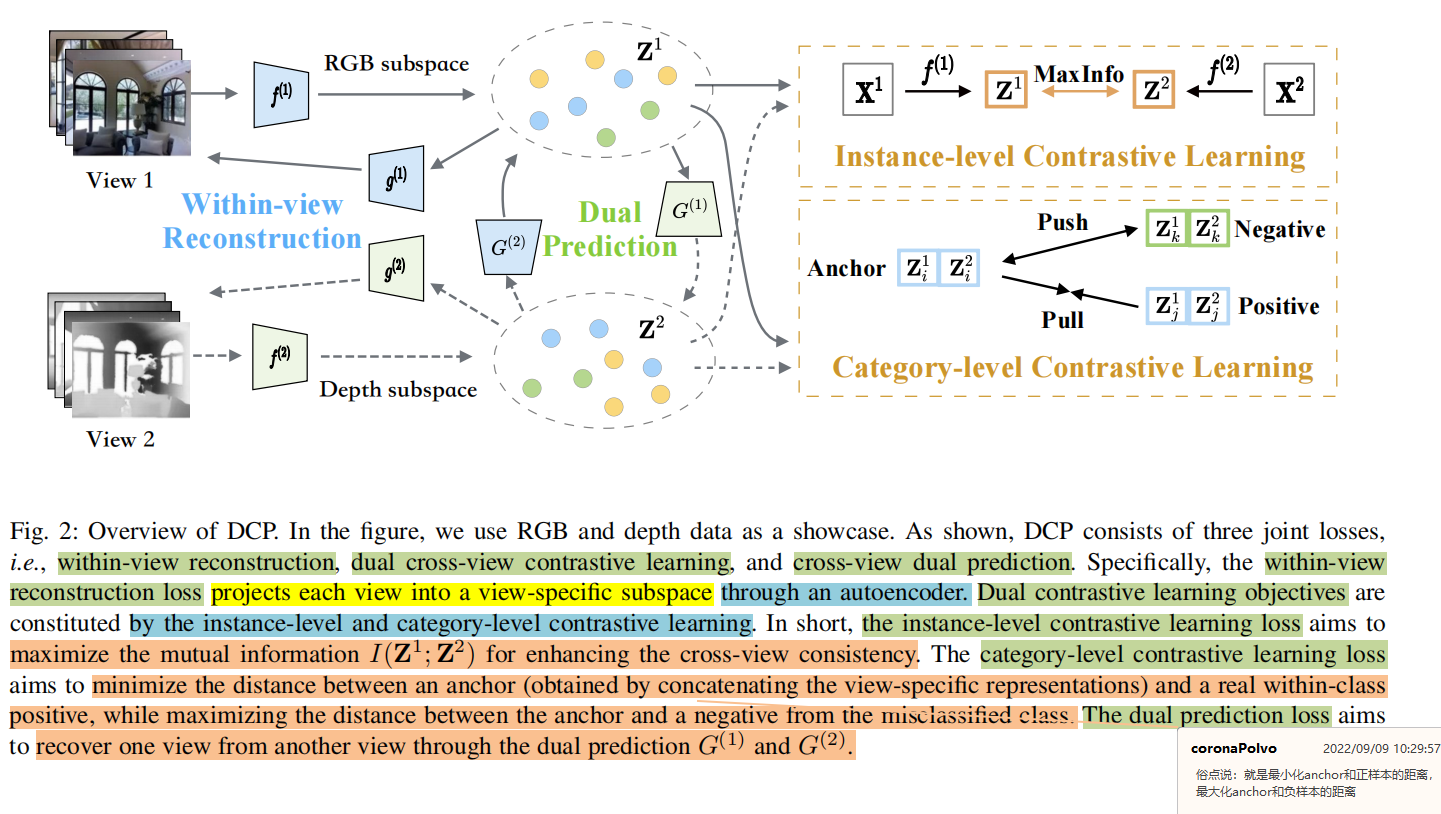
本文提出了一个不完整多视图表征学习方法,称为双对比预测(Dual Contrastive Prediction, DCP)。DCP映射高维数据到一个潜在空间中,这个空间的跨视图一致性和数据恢复性收到三个联合损失的监督
视图内重构损失:学习视图特定的representation同时保留原始信息
双对比损失:通过最大化互信息I ( Z 1 ; Z 2 ) I\left(\mathbf{Z}^1 ; \mathbf{Z}^2\right) I ( Z 1 ; Z 2 )
双预测损失:通过最小化条件熵H ( Z 1 ∣ Z 2 ) H\left(\mathbf{Z}^1 \mid \mathbf{Z}^2\right.) H ( Z 1 ∣ Z 2 ) H ( Z 2 ∣ Z 1 ) H\left(\mathbf{Z}^2 \mid \mathbf{Z}^1\right.) H ( Z 2 ∣ Z 1 )
主要贡献:
在信息论的框架下,交叉视图一致性学习和数据恢复的内在联系。
提出DCP通过双对比损失和双预测损失分别得到信息一致性和数据恢复性
为了利用可用的标签信息,DCP设计并利用了实例级别和类级别的对比损失以增强representation的可分性。
提出的方法
X 1 \mathbf{X}^1 X 1 X 2 \mathbf{X}^2 X 2 Y \mathbf{Y} Y Z i \mathbf{Z}^i Z i X i \mathbf{X}^i X i f ( i ) : Z i ( X i ) f^{(i)}:\mathbf{Z}^i(\mathbf{X}^i) f ( i ) : Z i ( X i ) i = 1 , 2 i=1,2 i = 1 , 2 H ( A ) H(A) H ( A ) H ( A ∣ B ) H(A|B) H ( A ∣ B ) I ( A ; B ) I(A;B) I ( A ; B ) I ( A ; B ∣ C ) I(A;B|C) I ( A ; B ∣ C )
定义1 :跨视图一致性
给定视图特定的representation Z i \mathbf{Z}^i Z i Z j \mathbf{Z}^j Z j Z ′ ∈ τ ( X j ) \mathbf{Z}^{\prime}\in\tau(\mathbf{X}^j) Z ′ ∈ τ ( X j ) Z ′ ′ ∈ τ ( X i ) \mathbf{Z}^{\prime\prime}\in\tau(\mathbf{X}^i) Z ′′ ∈ τ ( X i ) τ ( X v ) \tau(\mathbf{X}^v) τ ( X v ) X v \mathbf{X}^v X v I ( Z i , Z j ) ≥ I ( Z i ; Z ′ ) I(\mathbf{Z}^i,\mathbf{Z}^j)\geq I(\mathbf{Z}^i;\mathbf{Z}^{\prime}) I ( Z i , Z j ) ≥ I ( Z i ; Z ′ ) I ( Z i , Z j ) ≥ I ( Z ′ ′ ; Z j ) I(\mathbf{Z}^i,\mathbf{Z}^j)\geq I(\mathbf{Z}^{\prime\prime};\mathbf{Z}^j) I ( Z i , Z j ) ≥ I ( Z ′′ ; Z j ) Z i \mathbf{Z}^i Z i Z j \mathbf{Z}^j Z j
定义2 :跨视图可恢复性
给定representation Z i \mathbf{Z}^i Z i Z ′ ∈ τ ( X j ) \mathbf{Z}^{\prime}\in\tau(\mathbf{X}^j) Z ′ ∈ τ ( X j ) H ( Z i ∣ Z j ) ≤ H ( Z i ∣ Z ′ ) H(\mathbf{Z}^i|\mathbf{Z}^j)\leq H(\mathbf{Z}^i|\mathbf{Z}^{\prime}) H ( Z i ∣ Z j ) ≤ H ( Z i ∣ Z ′ ) Z i \mathbf{Z}^i Z i H ( Z i ∣ Z j ) = 0 H(\mathbf{Z}^i|\mathbf{Z}^j)=0 H ( Z i ∣ Z j ) = 0 Z i \mathbf{Z}^i Z i
定义2中的恢复指的是恢复视图的公共信息,而不是全部信息,恢复公共信息有助于提高框架在下游任务中的表现。
理论1 :一致性和可恢复性的等价性
若representation Z i \mathbf{Z}^i Z i Z j \mathbf{Z}^j Z j Z i \mathbf{Z}^i Z i Z j \mathbf{Z}^j Z j Z j \mathbf{Z}^j Z j Z i \mathbf{Z}^i Z i
假设1 :多视图数据的同等充分性
对于下游任务,每一个视图的sufficency是近似相等的,比如保持I ( X 1 ; Y ) = I ( X 2 ; Y ) = I ( X 1 ; X 2 ; Y ) I\left(\mathbf{X}^1 ; \mathbf{Y}\right)=I\left(\mathbf{X}^2 ; \mathbf{Y}\right)=I\left(\mathbf{X}^1 ; \mathbf{X}^2 ; \mathbf{Y}\right) I ( X 1 ; Y ) = I ( X 2 ; Y ) = I ( X 1 ; X 2 ; Y )
观点1 :I ( X 1 ; Y ∣ X 2 ) = I ( X 2 ; Y ∣ X 1 ) = 0 I\left(\mathbf{X}^1 ; \mathbf{Y} \mid \mathbf{X}^2\right)=I\left(\mathbf{X}^2 ; \mathbf{Y} \mid \mathbf{X}^1\right)=0 I ( X 1 ; Y ∣ X 2 ) = I ( X 2 ; Y ∣ X 1 ) = 0
定义3 :Sufficient Representation
对于representation Z 1 \mathbf{Z}^1 Z 1 Z 2 \mathbf{Z}^2 Z 2 I ( Z 1 ; Y ) = I ( Z 2 ; Y ) = I ( X 1 ; X 2 ; Y ) I\left(\mathbf{Z}^1 ; \mathbf{Y}\right)=I\left(\mathbf{Z}^2 ; \mathbf{Y}\right)=I\left(\mathbf{X}^1 ; \mathbf{X}^2 ; \mathbf{Y}\right) I ( Z 1 ; Y ) = I ( Z 2 ; Y ) = I ( X 1 ; X 2 ; Y ) Z 1 \mathbf{Z}^1 Z 1 Z 2 \mathbf{Z}^2 Z 2
定义4 :Minimal Representation
对于representation Z 1 \mathbf{Z}^1 Z 1 Z 2 \mathbf{Z}^2 Z 2 I ( Z 1 ; X 1 ∣ Y ) = I ( Z 2 ; X 2 ∣ Y ) = I ( X 1 ; X 2 ∣ Y ) I\left(\mathbf{Z}^1 ; \mathbf{X}^1 \mid \mathbf{Y}\right)=I\left(\mathbf{Z}^2 ; \mathbf{X}^2 \mid \mathbf{Y}\right)=I\left(\mathbf{X}^1 ; \mathbf{X}^2 \mid \mathbf{Y}\right) I ( Z 1 ; X 1 ∣ Y ) = I ( Z 2 ; X 2 ∣ Y ) = I ( X 1 ; X 2 ∣ Y ) Z 1 \mathbf{Z}^1 Z 1 Z 2 \mathbf{Z}^2 Z 2 I ( X 1 ; X 2 ∣ Y ) I\left(\mathbf{X}^1 ; \mathbf{X}^2 \mid \mathbf{Y}\right) I ( X 1 ; X 2 ∣ Y )
损失函数
sufficient和minimal的MVRL的通用形式为:
公式 1 : max I ( Z 1 ; Z 2 ) s . t . min H ( Z 1 ∣ Z 2 ) , min H ( Z 2 ∣ Z 1 ) 公式1:
\begin{aligned}
& \max I\left(\mathbf{Z}^1 ; \mathbf{Z}^2\right)\\
& s.t. \min H\left(\mathbf{Z}^1 \mid \mathbf{Z}^2\right), \min H\left(\mathbf{Z}^2 \mid \mathbf{Z}^1\right)
\end{aligned}
公式 1 : max I ( Z 1 ; Z 2 ) s . t . min H ( Z 1 ∣ Z 2 ) , min H ( Z 2 ∣ Z 1 )
上图是DCP的结构图,其由3个联合学习目标组成,视图内重构损失L r e c \mathcal{L}_{rec} L rec L c l \mathcal{L}_{cl} L c l L p r e \mathcal{L}_{pre} L p re
公式 2 : L = L c l + λ 1 L p r e + λ 2 L r e c 公式2:\mathcal{L}=\mathcal{L}_{cl}+\lambda_1\mathcal{L}_{pre}+\lambda_2\mathcal{L}_{rec}
公式 2 : L = L c l + λ 1 L p re + λ 2 L rec
其中λ 1 \lambda_1 λ 1 λ 2 \lambda_2 λ 2 L p r e \mathcal{L}_{pre} L p re L r e c \mathcal{L}_{rec} L rec
视图内重构损失
对于给定的数据集X ‾ = { X ‾ ( 1 , 2 ) , X ‾ ( 1 ) , X ‾ ( 2 ) } \overline{\mathbf{X}}=\left\{\overline{\mathbf{X}}^{(1,2)}, \overline{\mathbf{X}}^{(1)}, \overline{\mathbf{X}}^{(2)}\right\} X = { X ( 1 , 2 ) , X ( 1 ) , X ( 2 ) } X ‾ ( 1 , 2 ) , X ‾ ( 1 ) \overline{\mathbf{X}}^{(1,2)}, \overline{\mathbf{X}}^{(1)} X ( 1 , 2 ) , X ( 1 ) X ‾ ( 2 ) \overline{\mathbf{X}}^{(2)} X ( 2 ) X ‾ ( 1 , 2 ) \overline{\mathbf{X}}^{(1,2)} X ( 1 , 2 ) X v \mathbf{X}^v X v
第v个视图的数据通过一个特定的编码器得到representation Z v \mathbf{Z}^v Z v L r e c \mathcal{L}_{rec} L rec
公式 3 : L r e c = ∑ v = 1 2 ∑ t = 1 m ∥ X t v − g ( v ) ( Z t v ) ∥ 2 2 公式3:\mathcal{L}_{r e c}=\sum_{v=1}^2 \sum_{t=1}^m\left\|\mathbf{X}_t^v-g^{(v)}\left(\mathbf{Z}_t^v\right)\right\|_2^2
公式 3 : L rec = v = 1 ∑ 2 t = 1 ∑ m X t v − g ( v ) ( Z t v ) 2 2
其中X t v \mathbf{X}_t^v X t v X v \mathbf{X}^v X v g ( v ) g^{(v)} g ( v ) Z t v \mathbf{Z}_t^v Z t v
公式 4 : Z t v = f ( v ) ( X t v ) , 公式4:\mathbf{Z}_t^v=f^{(v)}\left(\mathbf{X}_t^v\right),
公式 4 : Z t v = f ( v ) ( X t v ) ,
其中f ( v ) f^{(v)} f ( v )
双对比学习损失
使用对比学习来最大化多视图的一致性,以克服在不完整视图表征学习中的一致性学习挑战。其由实例级和类级约束损失构成,可以用下面的公式表示
公式 5 : L c l = L i c l + L c c l , 公式5:\mathcal{L}_{c l}=\mathcal{L}_{i c l}+\mathcal{L}_{c c l},
公式 5 : L c l = L i c l + L cc l ,
其中实例级对比损失 L i c l \mathcal{L}_{i c l} L i c l L c c l \mathcal{L}_{c c l} L cc l
实例级对比学习 :在使用自编码器学习的潜在特征空间中,使用对比学习最大化跨不同视图的一致性。本文提出直接最大化不同视图的representation之间的互信息。可以用下面的公式表示:
公式 6 : L i c l = − ∑ t = 1 m ( I ( Z t 1 ; Z t 2 ) + α ( H ( Z t 1 ) + H ( Z t 2 ) ) ) , 公式6:\mathcal{L}_{i c l}=-\sum_{t=1}^m\left(I\left(\mathbf{Z}_t^1 ; \mathbf{Z}_t^2\right)+\alpha\left(H\left(\mathbf{Z}_t^1\right)+H\left(\mathbf{Z}_t^2\right)\right)\right),
公式 6 : L i c l = − t = 1 ∑ m ( I ( Z t 1 ; Z t 2 ) + α ( H ( Z t 1 ) + H ( Z t 2 ) ) ) ,
其中I I I H H H α = 9 \alpha=9 α = 9
{ Z i } i = 1 2 \left\{\mathbf{Z}^i\right\}_{i=1}^2 { Z i } i = 1 2 z z z z ′ z^{\prime} z ′ P ∈ R D × D \mathbf{P} \in \mathcal{R}^{D \times D} P ∈ R D × D P ( z , z ′ ) \mathcal{P}\left(z, z^{\prime}\right) P ( z , z ′ )
公式 7 : P = 1 m ∑ t = 1 m Z t 1 ( Z t 2 ) ⊤ 公式7:\mathbf{P}=\frac{1}{m} \sum_{t=1}^m \mathbf{Z}_t^1\left(\mathbf{Z}_t^2\right)^{\top}
公式 7 : P = m 1 t = 1 ∑ m Z t 1 ( Z t 2 ) ⊤
边缘概率分布P ( z = d ) \mathcal{P}(z=d) P ( z = d ) P ( z ′ = d ′ ) \mathcal{P}\left(z^{\prime}=d^{\prime}\right) P ( z ′ = d ′ ) P d \mathbf{P}_d P d P d ′ \mathbf{P}_d^{\prime} P d ′ P \mathbf{P} P d d d d ′ d^{\prime} d ′
公式 8 : L i c l = − ∑ d = 1 D ∑ d ′ = 1 D P d d ′ ln P d d ′ P d α + 1 ⋅ P d ′ α + 1 , 公式8:\mathcal{L}_{i c l}=-\sum_{d=1}^D \sum_{d^{\prime}=1}^D \mathbf{P}_{d d^{\prime}} \ln \frac{\mathbf{P}_{d d^{\prime}}}{\mathbf{P}_d^{\alpha+1} \cdot \mathbf{P}_{d^{\prime}}^{\alpha+1}},
公式 8 : L i c l = − d = 1 ∑ D d ′ = 1 ∑ D P d d ′ ln P d α + 1 ⋅ P d ′ α + 1 P d d ′ ,
其中P d d ′ \mathbf{P}_{d d^{\prime}} P d d ′ P \mathbf{P} P d d d d ′ d^{\prime} d ′ α \alpha α
类级对比学习 :利用可用的标签信息去引导representation学习,在无监督学习中则不使用类级对比损失函数L c c l \mathcal{L}_{ccl} L cc l Z t = [ Z t 1 ; Z t 2 ] \mathbf{Z}_t=\left[\mathbf{Z}_t^1 ; \mathbf{Z}_t^2\right] Z t = [ Z t 1 ; Z t 2 ] L c c l \mathcal{L}_{ccl} L cc l [ ; ] [;] [ ; ]
公式 9 : L c c l = ∑ t m [ E Z ∼ T ( y ) S ( Z , Z t ) − E Z ∼ T ( g t ) S ( Z , Z t ) + γ ] + 公式9:\mathcal{L}_{c c l}=\sum_t^m\left[\mathbb{E}_{\mathbf{Z} \sim \mathcal{T}(y)} S\left(\mathbf{Z}, \mathbf{Z}_t\right)-\mathbb{E}_{\mathbf{Z} \sim \mathcal{T}(g t)} S\left(\mathbf{Z}, \mathbf{Z}_t\right)+\gamma\right]_{+}
公式 9 : L cc l = t ∑ m [ E Z ∼ T ( y ) S ( Z , Z t ) − E Z ∼ T ( g t ) S ( Z , Z t ) + γ ] +
其中g t g t g t Z t , S ( Z , Z t ) = Z T Z t \mathbf{Z}_t, S\left(\mathbf{Z}, \mathbf{Z}_t\right)=\mathbf{Z}^T \mathbf{Z}_t Z t , S ( Z , Z t ) = Z T Z t Z t , S ( Z , Z t ) = Z T Z t \mathbf{Z}_t, S\left(\mathbf{Z}, \mathbf{Z}_t\right)=\mathbf{Z}^T \mathbf{Z}_t Z t , S ( Z , Z t ) = Z T Z t T ( g t ) \mathcal{T}(g t) T ( g t ) g t gt g t T ( y ) \mathcal{T}(y) T ( y ) y y y γ \gamma γ γ = 0 \gamma=0 γ = 0 γ = 1 \gamma=1 γ = 1 y y y
公式 10 : y = arg max y ∈ Y E Z ∼ T ( y ) S ( Z , Z t ) . 公式10:y=\underset{y \in \mathcal{Y}}{\arg \max } \mathbb{E}_{\mathbf{Z} \sim \mathcal{T}(y)} S\left(\mathbf{Z}, \mathbf{Z}_t\right) .
公式 10 : y = y ∈ Y arg max E Z ∼ T ( y ) S ( Z , Z t ) .
双预测损失
使用一个变分分布Q ( Z i ∣ Z j ) \mathcal{Q}\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right) Q ( Z i ∣ Z j ) E P Z i , Z j [ log P ( Z i ∣ Z j ) ] \mathbb{E}_{\mathcal{P}_{\mathbf{Z}^i, \mathbf{Z}^j}}\left[\log \mathcal{P}\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right)\right] E P Z i , Z j [ log P ( Z i ∣ Z j ) ] H ( Z i ∣ Z j ) H\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right) H ( Z i ∣ Z j ) Q \mathcal{Q} Q N ( Z i ∣ G ( j ) ( Z j ) , σ I ) \mathcal{N}\left(\mathbf{Z}^i \mid G^{(j)}\left(\mathbf{Z}^j\right), \sigma \mathbf{I}\right) N ( Z i ∣ G ( j ) ( Z j ) , σ I ) σ I \sigma \mathbf{I} σ I G ( j ) ( ⋅ ) G^{(j)}(\cdot) G ( j ) ( ⋅ ) Z j \mathbf{Z}^j Z j Z i \mathbf{Z}^i Z i E P Z i , Z j [ log Q ( Z i ∣ Z j ) ] \mathbb{E}_{\mathcal{P}_{\mathbf{Z}^i, \mathbf{Z}^j}}\left[\log \mathcal{Q}\left(\mathbf{Z}^i \mid \mathbf{Z}^j\right)\right] E P Z i , Z j [ log Q ( Z i ∣ Z j ) ]
公式 11 : min E P Z i , Z j ∥ G ( j ) ( Z j ) − Z i ∥ 2 2 公式11:\min \mathbb{E}_{\mathcal{P}_{\mathbf{Z}^i, \mathbf{Z}^j}}\left\|G^{(j)}\left(\mathbf{Z}^j\right)-\mathbf{Z}^i\right\|_2^2
公式 11 : min E P Z i , Z j G ( j ) ( Z j ) − Z i 2 2
考虑两个视图数据,双预测损失可以用下面的形式表示:
公式 12 : L pre = ∥ G ( 1 ) ( Z 1 ) − Z 2 ∥ 2 2 + ∥ G ( 2 ) ( Z 2 ) − Z 1 ∥ 2 2 公式12:\mathcal{L}_{\text {pre }}=\left\|G^{(1)}\left(\mathbf{Z}^1\right)-\mathbf{Z}^2\right\|_2^2+\left\|G^{(2)}\left(\mathbf{Z}^2\right)-\mathbf{Z}^1\right\|_2^2
公式 12 : L pre = G ( 1 ) ( Z 1 ) − Z 2 2 2 + G ( 2 ) ( Z 2 ) − Z 1 2 2
在训练完成后,使用整个数据集到网络中,并得到所有视图的representation,对于缺失视图(X ‾ ( 1 ) , X ‾ ( 2 ) \overline{\mathbf{X}}^{(1)}, \overline{\mathbf{X}}^{(2)} X ( 1 ) , X ( 2 ) Z ‾ ( j ) \overline{\mathbf{Z}}^{(j)} Z ( j ) Z ^ ( i ) \hat{\mathbf{Z}}^{(i)} Z ^ ( i )
公式 13 : Z ^ ( i ) = G ( j ) ( Z ‾ ( j ) ) = G ( j ) ( f ( j ) ( X ‾ ( j ) ) ) 公式13:\hat{\mathbf{Z}}^{(i)}=G^{(j)}\left(\overline{\mathbf{Z}}^{(j)}\right)=G^{(j)}\left(f^{(j)}\left(\overline{\mathbf{X}}^{(j)}\right)\right)
公式 13 : Z ^ ( i ) = G ( j ) ( Z ( j ) ) = G ( j ) ( f ( j ) ( X ( j ) ) )
其中Z ‾ ( j ) \overline{\mathbf{Z}}^{(j)} Z ( j ) X ‾ ( j ) \overline{\mathbf{X}}^{(j)} X ( j ) Z \mathbf{Z} Z Z = [ Z 1 ; Z 2 ] \mathbf{Z}=\left[\mathbf{Z}^1 ; \mathbf{Z}^2\right] Z = [ Z 1 ; Z 2 ] Z = [ Z ^ ( 1 ) ; Z ‾ ( 2 ) ] \mathbf{Z}=\left[\hat{\mathbf{Z}}^{(1)} ; \overline{\mathbf{Z}}^{(2)}\right] Z = [ Z ^ ( 1 ) ; Z ( 2 ) ] Z = [ Z ‾ ( 1 ) ; Z ^ ( 2 ) ] \mathbf{Z}=\left[\overline{\mathbf{Z}}^{(1)} ; \hat{\mathbf{Z}}^{(2)}\right] Z = [ Z ( 1 ) ; Z ^ ( 2 ) ]
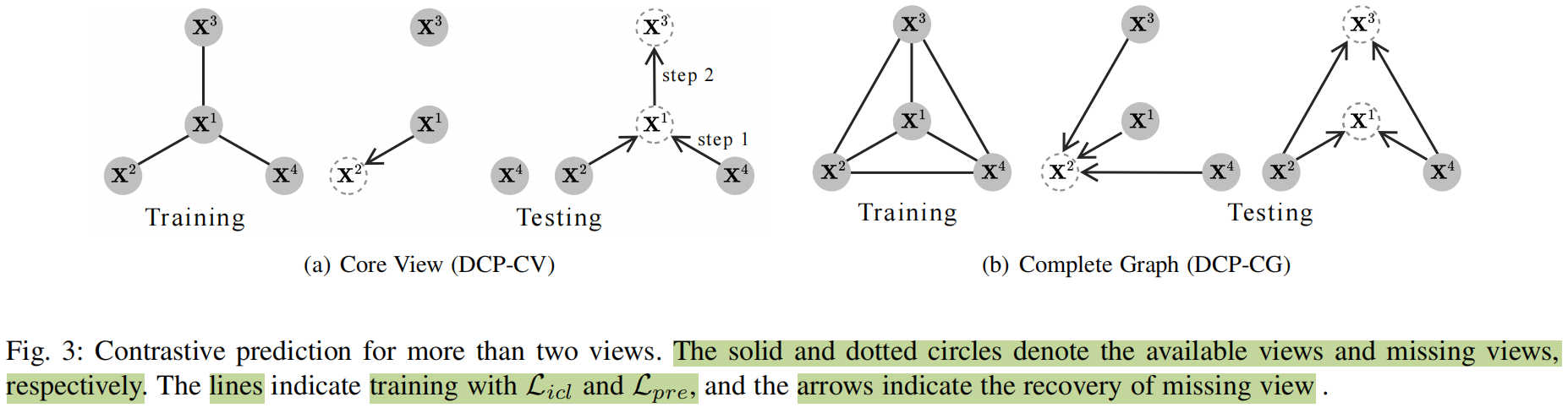
用于多个视图的对比预测
有两种通用的公式去解决多个视图的对比预测问题:基于核心视图的方法(DCP-CV),基于完整图的方法(DCP-CG)
给定有V V V { X i } i = 1 V \left\{\mathbf{X}^i\right\}_{i=1}^V { X i } i = 1 V X 1 \mathbf{X}^1 X 1 X j \mathbf{X}^j X j
公式 14 : L D C P − C V = ∑ i = 2 V L i p ( Z 1 , Z i ) + λ 2 ∑ i = 1 V L rec ( Z i ) + L c d 公式14:\mathcal{L}_{\mathrm{DCP}-\mathrm{CV}}=\sum_{i=2}^V \mathcal{L}_{i p}\left(\mathbf{Z}^1, \mathbf{Z}^i\right)+\lambda_2 \sum_{i=1}^V \mathcal{L}_{\text {rec }}\left(\mathbf{Z}^i\right)+\mathcal{L}_{c d}
公式 14 : L DCP − CV = i = 2 ∑ V L i p ( Z 1 , Z i ) + λ 2 i = 1 ∑ V L rec ( Z i ) + L c d
其中L i p = L i c l + λ 1 L p r e , λ 1 \mathcal{L}_{i p}=\mathcal{L}_{i c l}+\lambda_1 \mathcal{L}_{p r e}, \lambda_1 L i p = L i c l + λ 1 L p re , λ 1 λ 1 \lambda_1 λ 1 λ 2 \lambda_2 λ 2 L ccl \mathcal{L}_{\text {ccl }} L ccl
DCP-CG在所有可能的视图对上执行实例级对比学习和双约束,
公式 15 : L D C P − C G = ∑ 1 ≤ i < j ≤ V L i p ( Z i , Z j ) + λ 2 ∑ i = 1 V L r e c ( Z i ) + L c c l 公式15:\mathcal{L}_{\mathrm{DCP-CG}}=\sum_{1 \leq i<j \leq V} \mathcal{L}_{i p}\left(\mathbf{Z}^i, \mathbf{Z}^j\right)+\lambda_2 \sum_{i=1}^V \mathcal{L}_{r e c}\left(\mathbf{Z}^i\right)+\mathcal{L}_{c c l}
公式 15 : L DCP − CG = 1 ≤ i < j ≤ V ∑ L i p ( Z i , Z j ) + λ 2 i = 1 ∑ V L rec ( Z i ) + L cc l
虽然DCP-CV和DCP-CG都能够学习足够和最小的representation,但我们推荐后者的原因如下:一方面,为了一致性学习,DCP-CG将捕获更多的信息,因为所有的视图对都在学习阶段被包含和利用。DCP-CG视图最大化v ( v − 1 ) / 2 v(v-1)/2 v ( v − 1 ) /2 v − 1 v-1 v − 1