「书籍阅读」智能计算系统
这篇博客用于记录《智能计算系统》一书中的一些关键内容,由于前4章都是深度学习相关知识,我已经基本了解,所以不需要记录太多内容
第5章
TF1的设计原则
TF1的计算图机制
求导方式
- 手动求导:用链式法则求解梯度公式
- 优点:直接带入数字就可以得到结果
- 缺点:无法通用或复用
- 数值求导:利用导数的原始定义求解
- 优点:可以向用户隐藏求导细节
- 缺点:计算量大,运行速度慢,引入舍入误差(roundoff error)和截断误差(truncation error)
- 符号求导:利用求导规则对表达式自动操作,可能产生“表达式膨胀的问题”。
自动求导:在给定前向计算过程后,由编程框架自动推导方向计算图,完成导数计算是一种介于符号求导和数值求导之间的方法。其首先实现了一批常用基本算子的求导表达式(比如,这个结果,就要在sin这个操作的类中,注册其求导方法为cos),保留中间结果,最后求互整个函数的导数。
控制流
TF1使用不同的控制流算子的不同组合来实现各种复杂控制流场景。
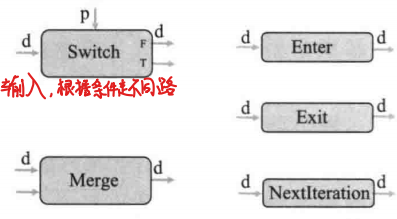
执行帧:TF1每个算子都会在一个执行帧中执行,其通过专门的控制流逻辑来创建和管理。在没有数据以来的前提下,不同的执行帧中的算子可以并行执行。
控制流基本算子:
- Swtich算子:根据输入条件,选择将输入数据输出到T/F两个不同的端口上。当输入数据和输入条件同时有效时执行。
- Merge算子:同一个时刻最多有一个输入数据有效,一旦某个输入数据有效,算子就会执行,将有效数据进行传递,通常情况下不会同时有效。
- Enter算子:Enter(name),将当前有效输入传入到名为name的执行帧中,主要用于主帧向子帧传递数据。一旦Enter的输入有效,就会自己执行。当第一个Enter算子执行时,执行帧就会建立起来。
- Exit算子:将输入传递给父帧,即子帧的计算结果传递给父帧。Exit算子可以类比为函数的返回值。每个执行帧可以由多个Exit算子,每个Exit算子异步执行。
- NextIteration算子:将输入传递给执行帧的迭代器,进入下一层迭代中。
基于这些算子,TF1进一步封装了cond和循环操作while_loop两个控制流API。
- 条件操作:
cond- 格式:
cond(pred, true_fn,false_fn) - 含义:如果
pred为真,返回true_fn的结果,否则返回false_fn的结果 - 举个例子:
tf.cond(x>y,lambda:tf.substract(x,y),lambda:tf.add(x,x))的实现 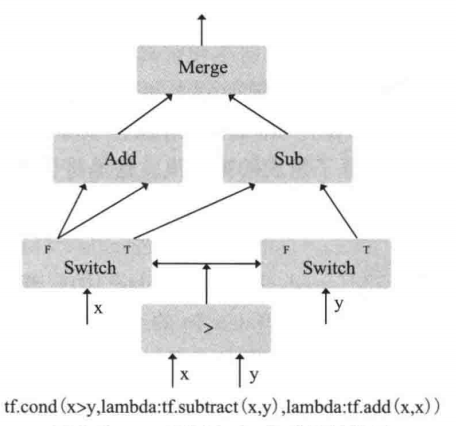
- x和y作为算子的输入,然后根据>的条件,如果x>y为T,则实现x与y相加的结果,如果x>y为F,则左边的算子走F的通道(x+x),右边的Swtich算子则不执行。最后根据Add和Sub算子中有效数据,作为Merge算子的输出。
- 格式:
- 循环操作:
while_loop- 格式:
while_loop(pred,body,loop_vars) - 含义:在满足
pred的条件下,反复执行body,其中loop_vars是父执行帧传递给循环控制执行帧的输入张量列表 - 举个例子:
tf.while_loop(lambda i:i<16, lambda i:tf.multiply(i,2), [4]) 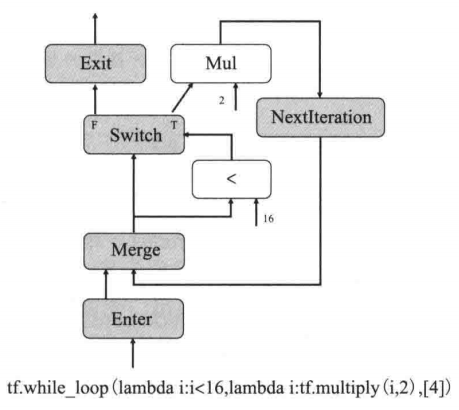
- 从下往上看,Enter算子注册了这个while_loop的执行帧,然后使用Merge算子进行输入流选择,由于初始化时只有Enter上来的输入,所以是Enter算子传递的数据会通过Merge算子传出,然后根据条件状态,在Switch算子中进行分支,如果是T,则执行x2的操作,进入NextIteration算子,然后输出值进入Merge算子中,此时因为Enter算子没有输入了,所以Merge算子会通过NextIteration算子的输出值,如果Switch算子为F,则进入Exit算子,结束执行帧输出最终的结果。
- 格式:
执行模式
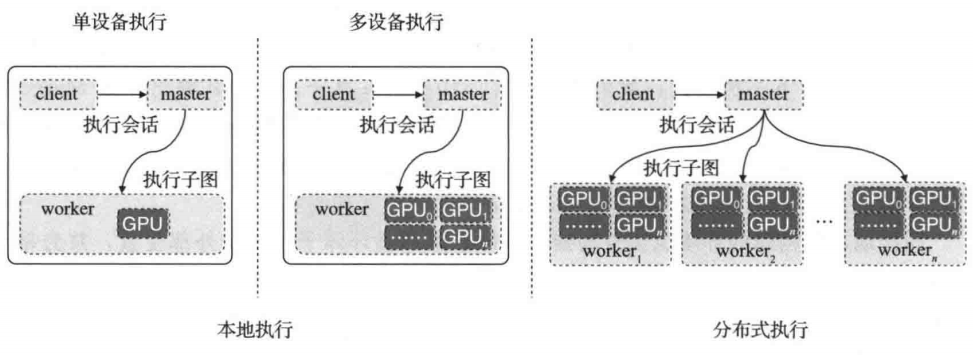
TF1的计算图执行通常包括客户端(client)、主控(master)进程以及一个或多个工作进程(worker process)。TF1提供了本地执行和分布式执行两种执行方式。
本地执行:客户端,主控进程以及工作进程都在只有一个操作系统的单一物理机上运行
分布式执行:支持客户端、主控进程以及工作进程在不同机器上执行。
基本流程:计算图中的节点按照图中的依赖关系顺序执行,TF调度器会持续见识未被执行的节点,一旦某个节点所依赖的前驱节点数量为0(即入度为0时,感觉有点像拓扑序列),该节点处于就绪状态,就会被立即放入预执行队列中,执行器会从预执行队列中取出节点,并根据节点信息,选择合适的设备创建相应算子交给设备端来执行。当某个节点执行结束后,所欲依赖该节点的依赖信息将被更新。
计算图的本地执行
计算图剪枝(prune)
目的:得到本地运行所需的最小子图。
主要由两部分组成:
- 取出计算图中与最终输出节点无关的边和节点
- 给输入输出节点建立和外接的交互
在本地执行模式下,TF通过FunctionCallFrame函数调用帧来解决输入输出值传递的问题。具体做法就是在每个输入节点前插入Arg节点,在每个输出节点后面加入RetVal节点,方便使用FuncitonCallFrame传递参数和抓取结果。最后,所有的输入节点连接到Source节点上,并通过控制依赖边相连。同样的,所有的输出节点连接到Sink节点上,也通过控制边相连,最终形成完整的计算图。
去除无关节点和边的过程,则是从输出节点开始进行快读搜索遍历,对在遍历过程中没有接触到的节点和边进行删除。遍历完成之后可能会生成多个连通图,此时需要将每个连通图的入度为0的节点通过控制依赖边与Source节点相连,出度为0的点通过控制依赖边和Sink节点相连,从而形成完整的计算图。
计算图分配(placement)
目的:解决在多设备运行环境中,计算图节点在哪个设备上执行的问题。
用户可以执行指定某个操作的计算设备,也可以指定那些计算节点需要绑定(co-locate)在同一个设备上。对于为执行的计算节点,再利用特定算法自动将节点分配到不同设备上,提高计算效率。
基础的设备划分算法采用贪心策略来对每个节点进行分配,从Source节点开始,算法模拟每个节点在支持该节点的所有不同设备上的执行情况,得到不同设备上该节点的执行开销。该算法不仅考虑代价模型中当前节点的计算开销,还包括输入数据拷贝到该节点的数据通信开销。显然,由于该设备分配算法每次都只关注当前节点,导致得到的结果仅仅是局部最优,无法保证全局最优。但TF提供了额外的接口,使得用户可以给设备分配算法提供额外帮助信息或限制信息,以达到高效的设备分配。
计算图优化(optimization)
TF图优化由Grappler模块来实现,用户可以利用此模块实现定制的优化方法。图优化可以根据不同的硬件结构调整计算调度策略,从而获得更快的计算调度策略。
典型的优化方法:
- ConstFold(包括常量折叠等优化)
- 在分型静态计算图的过程中,检测到有的常量节点可以被提前计算,用得到的结果生成新的节点来代替原来的常量节点,从而减少运行时计算量的方法。
- 主要由三个关键函数组成
MaterializeShapes:处理Shape相关的节点,通过静态计算图已有的信息推算出形状结果后,用结果来代替原来的节点FoldGraph:该函数会对每个节点的输入进行检测,如果检测到输入均为常量节点,则提前计算出值来完整替换当前的节点。SimplifyGraph:该函数则聚焦于简化节点中的常量运算,比如Mul(c1,Mul(tensor,c2))简化为Mul(tensor,c1*c2)
- Arithmetic(包括算术简化等):公共子表达式消除和算术简化
- tensor+tensor+tensor转化为3*tensor
- (mat1+s1)+(mat2+s2)转化成(mat1+mat2)+(s1+s2),其中s1和s2是标量
- Layout(包括布局优化等):主要针对GPU运算,TF默认使用NHWC的格式,而在GPU中NCHW更加高效,在布局优化中可以使用NHWC2NCHW和NCHW2NHWC这两个转化节点。
- Remapper(包括算子融合等):一般指算子融合,即出现频率比较高的子图用一个单独算子来代替,提高计算效率。融合后的算子,该部分子图的调度开销就被完全消除了。
- Conv2D+BiasAdd+Activation
- Conv2D+FusedBatchNorm+Activation
计算图切分(partition)
指在计算图的一系列优化完成之后,将计算图放到多个设备上计算,每个设备对应一个切分子图(partition graph),需要解决通信问题。
在新图中,所有的跨设备边被替换成一对由Send和Recv组成的节点,并限定所有使用目标张量的节点都使用同一个Recv节点。Send/Recv节点向不同的设备或工作机传递数据通讯需求。在Recv没有得到有效数据之前,图的运行会被阻塞主。主控机只需要向不同的工作传递运行请求,不需要负责不同工作机之间的同步问题。这使得TensorFlow系统有良好的可拓展性和更高的执行策略。
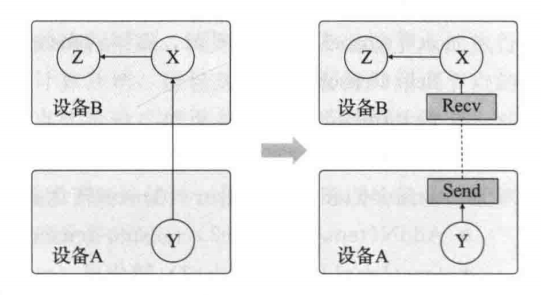
计算图的分布式执行
在图分配后为每个设备都创建了一个子图,在工作进程通信的Send/Recv节点通过远程通信机制(TCP,RDMA)进行数据传输。
分布式通信
可以分为两类:点到点通信(point-to-point communication)和集合通信(collective communication)。
TF实行了集合通信的基本算子:
- all_sum:将所有输入张量相加得到一个张量,并将其输出到每个输入张量对应的设备上
- all_prod:将所有输入张量对应维度的元素相加得到一个张量,并将其输出到每个输入张量对应的设备上
- all_min:将所有输入张量对应维度的元素取最小值得到一个张量,并将其输出到每个输入张量对应的设备上
- all_max:将所有输入张量对应维度的元素取最大值得到一个张量,并将其输出到每个输入张量对应的设备上
- reduce_sum:将所有输入张量相加得到一个张量,并返回这个结果
- broadcast:将输入张量广播给所有的设备
容错机制
TF会检查Send和Recv节点传输的正确性,同时主控机会定期检查每个工作机的状态。当检查到系统发生错误时,整个计算图的执行过程就会立即停止,然后可由用户重新启动执行。用户在训练过程中可以保存中间状态,用于立即回复到出错前的状态。
TF系统实现
整体架构
第一部分是面向各种语言的语言包,第二部分是C/C++API,面向有较高性能需求的用户。第三部分是TF的后端代码。如下图:
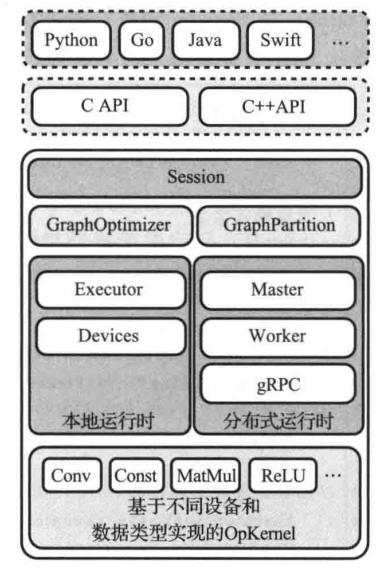
核心后端代码从结构上可以分为以下部分:
- core/common_runtime和core/distributed_runtime:运行时部分,有本地运行时core/common_runtime和分布式运行时distributed_runtime。本地运行时包括执行器逻辑和设备管理,分布式运行时包括主控进程、工作进程和远程通信等。
- core/framework:框架部分,包括TF基本数据结构定义,如Graph、Node、function、OpKernel(计算核函数)等定义
- core/graph:计算图部分,包括计算图的构建和切分
- core/grappler:图优化部分,计算图的优化以及计算图代价模型建立
- core/kernels:计算核函数部分,主要包括计算核函数(Conv,MatMul,ReLU)的具体实现
- core/ops:计算节点部分,包括计算节点注册逻辑
计算图执行模块
Session执行
Session是用户和TF运行时的接口,在Session接受到输入数据时,便可开始运行。一般情况下,每个设备都会有一个执行器(Executor),负责本设备上计算子图的执行。通过利用CPU上多线程或GPU上多Stream机制,执行器可以最大化地实现降低延迟和增加吞吐的目标。
Run函数是Session执行的核心所里,在其中完成计算的执行,包括传参、运行和返回。函数调用帧(FunctionCallFrame)是Session和执行器进行交互的窗口,feed和fetch分别是输入和输出参数。执行器从feed中获取输入并执行结果写入fetch中。在准备好执行环境后,Session会调用RunInternal函数开始执行计算。在其中会启动多个并行执行器,同时会创建执行器的barrier,确保所有的执行器都执行完。RunInternal函数执行完毕后,返回到Run函数继续执行,处理计算图得到最终的运算结果。
执行器逻辑
执行流(stream):一个能够存储计算任务的队列,队列中的计算任务按照进入队列的顺序执行。
设备在执行计算任务时会存在不同的流,流与流之间的计算任务可以并行执行,流内的计算任务串行执行。执行器分配图中每个节点到对应的流的原则是:有数据依赖的节点分配到同一流中,无数据依赖的节点分配到不同流中。分配完流之后,执行器启动ScheduleReady函数开始异步执行计算图中的节点,执行器调用完RunAsync函数后,返回主逻辑,等待执行结束。
ScheduleReady主要是对队列中每个节点都调用Process方法进行处理,其中主要处理两个队列:ready队列是预之心队列,inline_ready是当前现成要处理的队列。如果inline_ready为空(最开始为空),则使用新的现成分别处理ready中的每个节点。当inline_ready不为空时,若节点都是低开销的,则逐一放到inline_ready队列中,如果节点是高开销的,当inline_ready队列为空则将首个高开销的节点放入inline_ready队列中,否则高开销的节点都会使用新的线程去执行。
在Process中,会真正进行节点的运算,主要完成:为OpKernel设置运行参数,为OpKernel准备输入、设置计算参数,调用设备计算,处理计算输出,传播输出并更新节点间的依赖关系,完成后处理并可能启动新的ScheduleReady函数。TF的计算核函数又两种运行模式:同步和异步。绝大部分算子是同步计算模式,Send/Recv算子是异步计算模式。因为Send和Recv算子的运行时间是高开销且不确定的,Process如果等待Send/Recv至其执行完成会严重影响整体执行效率,实际上,类似GPU这种具有执行流概念的设备,核函数并不是真正同步运行,调用完Compute函数只表示计算任务已经下发到了执行流中。
设备抽象和管理
设备是TF运行的实体,每个设备都负责一个子图的运算。TF使用注册机制来管理设备,开发者可以通过注册接口支持自定义设备,为了支持注册机制,TF定义了抽象的设备类。本地设备(CPU和GPU)都会基于LocalDevice再创建自己的设备类,深度学习处理器也可以基于LocalDevice创建自己的设备类。
网络和通信
TF中不同设备和机器间的同喜都有Send和Recv节点进行,而Send和Recv使用Rendezvous机制完成数据交互,其是一个基于生产者-消费之模型设计的抽象类。每个Rendezvous实例拥有一个通道表,其中记录了每对Send/Recv的广西和状态。不同的通道拥有唯一的键值,该键值是有生产者和消费者的消息产生的。生产者使用Send方法将数据传到特定通道,消费者使用Recv方法从特定通道中获取这组数据。生产者可以通过通道传输连续的多组数据,消费者可以按照发送顺序获得这组数据。消费者可以在任意时刻调用Recv方法来获取数据,也可以使用回调或阻塞的方法来获取数据。不论哪种方法,消费者都能在数据有效时尽快得到数据,生产者在任何时候对不会被阻塞。
- 发送方法(Send):Tensor生产者会在Send节点中调用Rendezvous的Send方法,将Tensor(val)和状态(is_dead)等信息发送到特定的键值通道上。
- 接收方法(Recv):由于Recv节点不知道何时数据才是有效的,因此采用异步回调模式。一旦读取的Tensor有效,回调函数便会被调用,完成Recv节点后续的操作。
本地通信:LocalRendezvouslmpl
主要是给本地运行时使用的,这个类中主要工鞥呢是实现了具体的Send和Recv函数。
Send函数:如果键值通道队列为空或者队列中只有Send节点的信息,则继续把新的信息放入队列中;如果队列中有Recv节点的信息,则直接把这个Send节点信息通过Recv节点的回调函数传给Recv节点。
Recv函数:主要逻辑是RecvAsync,如果队列中已经有Send节点信息,那么直接把该Send节点信息处理掉;如果队列为空或者只有Recv节点信息,则继续将本次Recv节点信息放入队列中。
远程通信:RemoteRendezvous
主要用于远程数据的交互,在TF中使用RPC通信机制实现远程通信。
BaseRemoteRendezvous类中定义,如果源和目的是同一个工作进程,则调用本地的RecvAsync,否则调用远程Recv方法。
RpcRemoteRendezvous继承了BaseRemoteRendezvous类,使用PRC远程调用方法获得远端的数据。RecvFromRemoteAsync的核心是准备并启动RpcRecvTensorCall类型的过程调用,用于获取远程的Tensor。其中最终会调用worker的RecvTesnorAsyn发起相应请求。
算子实现
每个算子都有自己的属性,可以由用户设置,也可以在建立Graph时由上下文推导而来,最常见的属性是设置算子的数据类型。OpKernel是算子的特定执行,依赖于底层硬件。基于不同设备、不同数据类型,算子可以由不同的OpKernel实现:既可以使用底层硬件提供的高性能库,也可以采用特定的编程语言。TF通过注册机制来支持不同算子和相应的OpKernel函数。
OpKernel的家孙可以是同步的也可以是异步的,但所有的OpKernel的Compute方法都必须要保证线程安全。大部分的OpKernel是同步计算的模式,这些OpKernel应该集成OpKernel类并覆写Compute方法,在Compute方法中完成需要做的工作遍立即返回,表示该算子已经结束计算。和通信相关的Opkernel,如Send和Recv,则需要采用异步执行方式。需要继承AsyncOpKernel并覆盖ComputeAsync方法。




