「论文笔记」User-Defined Operators: Efficiently Integrating Custom Algorithms into Modern Databases
论文名称:User-Defined Operators: Efficiently Integrating Custom Algorithms into Modern Databases
作者:Moritz Sichert, Thomas Neumann
时间:2022
期刊或会议:PVLDB2022
文章要解决什么问题?
本文要解决的问题就是在RDBMS上有效率地进行数据分析,如何在数据库中直接设计相应的数据分析算法,以更加高效地进行数据分析。
文章为什么要解决这个问题?
现在有很多数据分析系统用于处理数量日益增长的数据,并使用其解决各种各样的问题。现有的数据分析系统存在下面的问题:
- 这样的数据分析系统大都是脱离数据源自主架构并自主运行的。用于数据分析的数据大都存储在RDBMS中,要想给数据分析系统直接使用则需要从RDBMS中导出数据形成CSV文件,再将CSV文件导入到数据分析系统中。这样导入导出的操作是非常耗时的。
- 此外数据从RDBMS中提取之后,系统的许多有益特征也随之消失,比如ACID特征将不会被保证。
作者的动机(为什么想得出来这个方案)
根据之前提到的两个问题,作者就会思考能不能直接将数据分析算法直接集成到数据库系统中,于是有了下面的两个分析。
分析SQL存在的局限性
数据科学家们通常喜欢使用Spark,TensorFlow以及基于MapReduce形式的系统,即使他们不能像Umbra,DuckDB这些数据库系统一样达到主存的性能。在数据科学家常用的系统中,算法是可以通过过程性变成语言描述的,与SQL相比,这些语言更适合制定现代数据分析中使用的算法。数据分析算法通常是迭代的,可以通过使用包含变量赋值和控制语句的代码自然地表示。(这个想法,后面带动了使用用户自定义的代码实现算法的方案)
而SQL语句通常是声明式的set-oriented的,SQL在执行查询方面为查询引擎提供了很大的灵活性,但是要给SQL添加新功能并不容易。SQL查询的执行与每个数据库系统的特定查询引擎紧密耦合,因此向SQL添加新功能需要对数据内部进行深入了解。(这个想法,带动了后面将编写的代码转换成中间代码,在系统查询执行过程中直接使用。)
分析SQL解决局限性的方式
在SQL中,通过使用递归的CTE(公用表表达式)实现命令式的控制流。此外一些RDBMS还为SQL提供了命令式的拓展,比如T-SQL,PL/pgSQL等。这些命令式的拓展允许用户编写用户自定义的函数(UDF),UDF可以被标准的SQL查询调用,查询引擎也可以直接执行包含UDF的查询。理论上使用UDF能够比递归CTE更容易地写出更复杂的算法,但是这些命令式语言编写的函数通常执行得很慢。(慢的问题与后面使用内联的方式减小开销有比较相关的联系。)
分析不同类型的数据分析
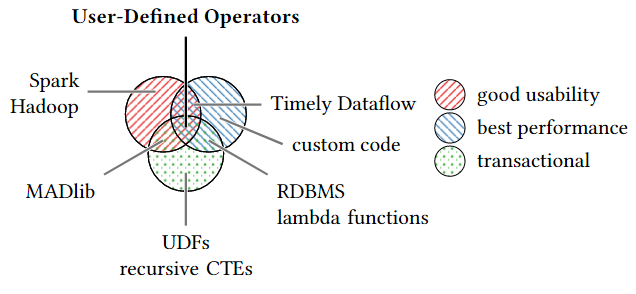
基于SQL的方法可以保证数据的一致性,但不允许轻松实现自定义算法。
Spark和Timely Dataflow这样的分析框架可以自动拓展用户编写的代码,但是无法达到定制编写的代码或具有主存速度的线代RDBMS的吞吐量。
基于上面的分析,作者提出了用户定义操作符(User-Defined Operators,UDOs),其能利用数据库系统中的ACID事物进行数据分析,并且允许用户使用自己喜欢的编程语言进行代码编写。
提出的方法
UDO的使用有以下3个优点
- 可用性:UDO可以为同用户提供简单的API,用户可以使用自己喜欢的编程语言实现自己的算法,并且UDO在数据库内部会被转化为常规的运算符,可以借助数据库系统的查询引擎直接执行。
- 性能:UDO可以优化查询,并且在Umbra数据库系统中,能够生成与数据库专家编写的复杂本机操作符一样的代码,并且能够直接在数据库中直接执行,不需要导入导出数据的操作。
- 一致性:UDO直接集成到RDBMS的查询引擎中,保留了系统所保证的所有ACID属性。
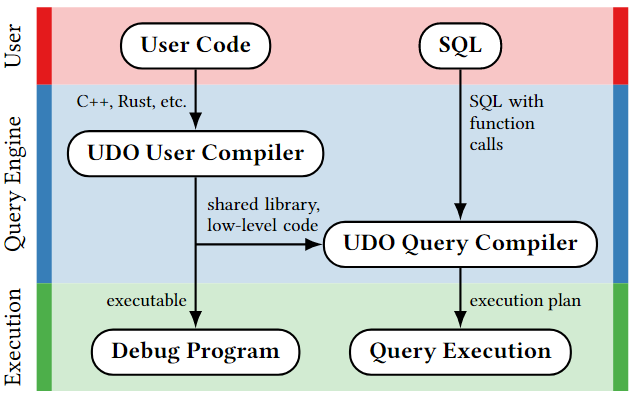
上图是UDO的整体结构,首先需要对UDO的代码进行分析和处理,以检测代码中的错误,然后使用UDO User Compiler 将UDO转化为查询引擎可以使用的表示方式。同时他可以直接生成Debug Program,用于对独立与数据库系统的用户代码进行调试。接着使用UDO Query Compiler将查询引擎获取处理过的用户代码并将其集成到SQL查询生成的查询计划中。他将UDO表示为代数运算符。
举个例子:博客的作者希望按类别分析文章,并想知道“lifestyle”类别的博客文章有多少篇,其他类别的文章有多少篇。
于是用户可以编写如下代码进行实现

UDO User Compiler
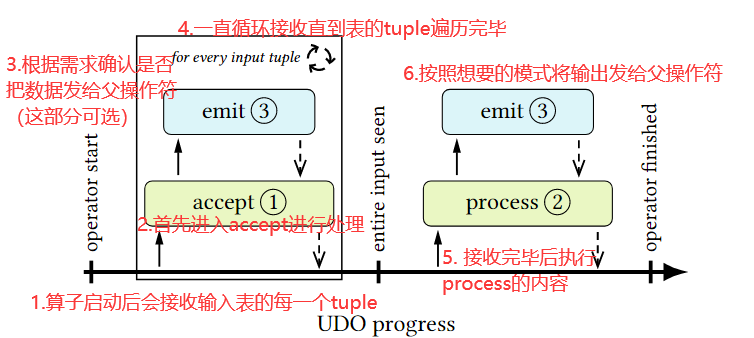
从上面的代码可以看出,UDO需要拥有至少3个方法,对应例子中1~3
accept和图中描述的一样,用于重复接收输入的数据表中的每一个元组,并在其内部进行处理并进行存储。
process也和图中描述的一样,在accept接收完所有的参数之后对存储内容进行统一处理。
emit函数可以接受单个数组作为参数,由UDO User Complier提供,可以被accept和process函数调用,会将结果发給UDO父操作符,上面的例子就是直接发送给from的那部分。
可以看到结构图中,UDO User Compiler还会提供一个可执行的Debug Program,与传统的使用外部调试工具以及数据库内部设计测试工具不同,这个程序利用了用户自定义的特性,可以自定义测试代码,并调用UDO User Complier提供的emit输出对应的参数。
为了更好地匹配数据库系统执行的特征,UDO还运行多线程并并发调用accept和process函数。
在代码生成查询引擎中的实现
Umbra是一个主存优先的系统,他会将SQL转换为关系代数之后,使用produce-consumer模型(生产者-消费者模型)为查询生成客户代码。由于客户代码生成代价较大,所以不会直接生成机器码,而是使用中间表示Umbra IR。
C++ UDO User Complier提供了一些可以使用的类和函数的定义。accept和process函数是由用户自己实现,并且必须带有的基类成员函数。emit函数是该类的另一个预定义成员函数。由于用户辨析的函数是类的成员函数,所以也可以使用UDO代码的成员变量从而跨accept和process的调用管理状态。
UDO User Complier会生成一个object file(使用ELF格式,可以由支持ELF的任何其他C++编译器生成)和一个LLVM模块(Clang编译器专用)。这两个模块方便UDO Query Complier潜在地将UDO代码与数据库系统生成的其余查询代码内联。
我感觉UDO User Complier这部分描述地不是很明白,这部分给我的感觉就是规定一个框架的代码应该怎么写,而没有像后面的Query Complier那样说代码生成的过程。
嗯。好像又说了一下这个东西会生成什么,我估计这一部分就是使用对应语言提供的编译器生成相应的中间代码,所以只讲了框架代码应该怎么写,编译过程就由对应的编译器实现,最后知道输出了什么东西。
UDO Query Compiler
UDO Query Complier接受User Compiler生成的构件,比如共享库,对象库或低级中间语言,并实现标准的代数运算符,他必须与数据库系统的任何其他操作符相同,并且这个实现的操作符必须由数据库系统的查询引擎直接实现,并且在设计上要求使用数据库内部。
在代码生成查询引擎中的实现
UDO Query Compiler会收到来自User Compiler的Object file和LLVM模块,并将其集成到一个查询计算中去。在查询中UDO被表示为关系代数运算符。可以接受由UDO User Compiler处理的任何UDO,并将其集成到现有的查询中,因为他被视为任何其他现有的代数运算符,因此与所有的DBMS组件无缝衔接。虽然跨的一般优化是不可行的,但是表示输入的子树和包含的子树优化是可行的。
Produce-Consume 模型
Umbra使用Produce-Consume模型为关系代数生成代码,这个模型中,每个代数运算实现produce和consume两个函数来生成代码,生成其输出时调用produce代码。举个例子,使用这个模型实现哈希表聚合,选择操作,表格扫描。
comsume代码什么时候调用好像没说清楚,我感觉应该是在要将结果传递给父函数时才使用consume函数

上面的三种操作符的代码在使用过程中通常是交错的,如下图所示

UDO的代码生成
本文也使用Produce-Consume模型生成UDO的代码,和其他的代数运算符一样,也需要两个produce和consume两个函数去发送生成的代码。集成accept函数很简单,consume函数必须调用accept函数,因为consume函数生成处理单个元组的代码,而accept函数接受单个元组,因此这两个函数是对应的。相似的,在produce生成的代码中代用process函数,可以确保在第一次调用process之前,看到所有输入都被处理完成。下面的例子展示了的produce和consume的定义

UDO Query Complier使用emit_helper替换用户代码中所有emit。通过这种方式,UDO对用户代码和其他关系代数操作符都是完全透明的。内置操作符可以直接使用的produce和consume函数,用户可以使用API函数process,accept和emit。下图是用替换选择代数操作,在这个例子中假设UDO只调用accept中的emit函数,而不实现process,图中的虚线表示emit_helper只有在UDO代码调用了emit时,emit_helper才会被间接调用。

下面的例子用UDO替换了聚合操作,可以看到原本要定义的哈希表不需要了,只是在遍历R的时候调用accept函数进行元组处理,但是由于这个过程UDO不用emit所以不会调用emit_helper,而在process中UDO要输出聚合结果,所以会调用emit,所以调用了emit_helper

UDO函数内联
文中好像讲了上面的两张图中存在一个低级函数反复调用的问题,为了提高性能所以要减小调用次数,这个我不太明白是什么意思?
首先是他说的反复调用的函数是指什么,emit_helper吗?那为什么反复调用这个函数会产生开销呢?
答:就是在调用User Code中会产生相应的上下文切换的情况,切换上下文其实是需要进行调度的,所以会产生一定的开销。反复调用这个函数,那么他跳转的次数就更多了。
切换到LLVM模式对提升性能有什么意义?
答:LLVM和C++相似,他是直接把函数的内容写入到对应的地方,如果想再次使用的时候就使用goto的方式回到对应的地方就可以了。
还有就是后面提到内连函数导致代码大小的增加是为什么?
答:就是如果使用内联的方式的话不做优化的情况下,对于每个emit在编译过程中都相当于再写一次相应的代码,如果emit调用次数很多的话,那emit对应的位置都要写上对应的代码,这样就会出现代码爆炸的情况。因此系统要求emit最多使用一次,但是如果是循环使用了emit(比如上面例子中的循环输出)则可以使用goto的方式跳转到对应位置执行代码再goto回来。
Umbra支持不同的执行模式,包括LLVM。为了实现UDO代码的内连,C++代码被编译到LLVM中,当执行查询时,Object file被加载到内存中,生成的代码对位于object file中的函数使用真正的低级函数调用。Object file只会在create时生成一次,因此不会引起高级编译器的编译开销。
当自适应执行框架检测到长时间运行的查询时,编译引擎为整个查询计划生成LLVM代码,在这种情况下,将搜索所有调用object file中的accept,process或emit函数的调用指令,并用它们的LLVM表示替换它们。切换到LLVM模式不是查询之前做的静态决策,而是在执行引擎运行是做出的。
并发执行
Umbra会生成在所有可用CPU核上并发处理所有查询的代码。为了实现最佳性能,还必须生成可以并发执行的代码。代码生成框架和morsel-driven驱动的调度程序确保了任何关系代数运算符的consume函数生成的代码能够被并发调用。由于中的consume实现生成了一个accept调用,这也意味着accept中用户编写的代码也会并发执行。
这也要求accept,process应该是线程安全的,应该使用线程安全的数据结构和同步的习惯用法比如互斥或原子操作。因为这些函数还可能调用了emit函数,因此emit函数也应该保证线程安全。
实现条件
- 全局状态和并发查询:
- 原因:用户代码可以是任意的代码,因此可以使用全局状态,但是在全局状态在突变是会有不好的表现,但如C++标准库中一样,全局状态可以更科学地实现一些函数。全局状态的另一种用法是线程局部变量,使算法的并行更加方便。
- 方案:UDO User Complier(线程局部)不禁止使用全局变量,因为要维护并发运行的独立查询隔离,以不违反ACID属性,所以UDO Query Complier为每个正在执行的UDO的每个实例维护完全独立的全局和线程局部状态。因此当一个包含UDO的新查询启动时,他的全局状态始终反应一个干净的状态,并且不受使用相同UDO的任何其他查询的影响。
- 链接运行时依赖项:
- 原因:执行C++或C的代码需要在运行时加载几个依赖项,比如C++和C的标准库,但是直接加入会干扰系统的其余部分。
- 方案:系统报了一个定制的运行时连接器,可以将所需的运行时库作为对象库或静态库加载,并将他们加载到现有的数据库进程中。连接器获取从UDO代码生成的Object file,并将其与运行时依赖链接起来。连接器还支持分配全局和线程本地状态,这允许实现对并发UDO的全局状态严格分离。
- 安全性:
- 原因:内置关系运算符的生成代码由数据库专家编写,通常很少会发生错误,但是UDO的代码由用户编写,用户可能对系统不了解,甚至是恶意用户。在文章距离的Umbra系统中,生成的代码直接内联到查询代码中,具有与查询仙童的功能和特权,UDO的Bug可能会导致数据库崩溃,恶意行为者可以利用这一点作为一个容易的特权升级。
- 方案:为了防止内存错误,可以使用Rust,其编译的LLVM可以保证内存安全,但是对于恶意代码的处理并不容易,目前实现的UDO不能与不可信的代码一起使用。





