「论文笔记」Tuplex: Data Science in Python at Native Code Speed
论文名称:Tuplex: Data Science in Python at Native Code Speed
作者:Leonhard Spiegelberg / Rahul Yesantharao / Malte Schwarzkopf / Tim Kraska
时间:2021
期刊或会议:SIGMOD2021
Introduction
使用Python编写的UDF:如今的数据科学pipelines通常依赖于用易于使用的Python编写的UDF(user-defined function,用户定义函数)。但是也有下面一些问题:
- 但是Python代码在字节码解释器中执行,它解释指令跟踪对象类型,管理内存和处理异常。这种基础设施带来了较大的开销。并且Python UDFs不能被容易地编译成机器码。
- 在Spark中使用UDF,则会有一部分代码执行Spark的操作符,然后一部分UDF代码则会使用Python的操作符,这就需要在python的解释器和JVM之间进行数据传输,阻止了跨UDF生成端到端优化的代码。
生成本机代码(native code):将Python UDF的内容生成像C++ code和LLVM IR的那样本机代码,是问题的解决方案之一。但是由于Python动态类型的复杂性,提前生成、编译和优化处理Python程序中,所有可能的代码路径是不可能的。要处理的情况数量很多,这使得即使是针对简单的UDF也很难编译优化代码。
Motivation
- 异常情况发生的情况比较少,对异常情况使用较慢的python解释器处理办法,对系统的总体性能影响不大。
- 将样本中的普通情况推广到常见情况,将代码编译的复杂性推迟到异常情况处理,这两种方案简化了代码的生成逻辑。
Method
OverView
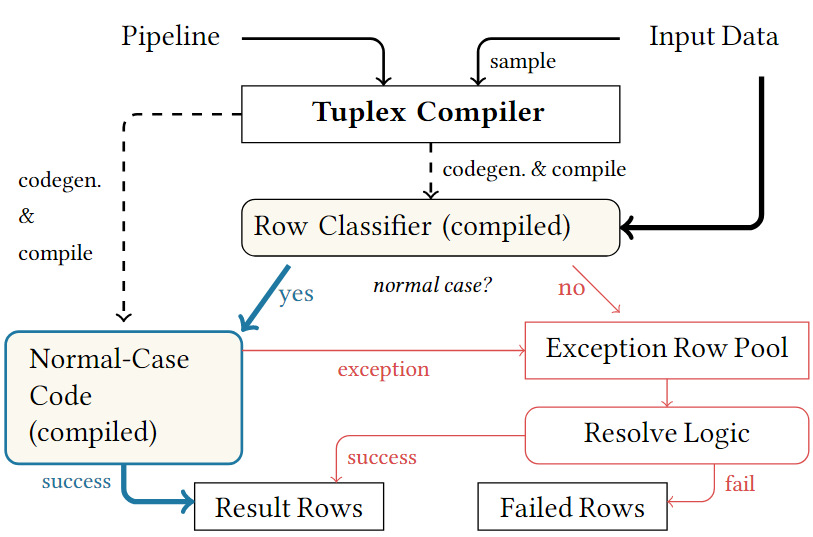
Tuplex 使用与PySpark相似的LINQ-style的API,进行UDF的编写,Tuplex在执行开始前将pipelines编译为端到端优化的native code,其实现依赖于dual-mode process,其建模了两种不同执行模型:
- 一种是在常规情况的执行会进行优化
- 另一种是异常情况的执行
流程:(如上图),
- Tuplex采样输入数据,并基于采样决定常规情况执行的预期类型以及控制流,Tuplex使用这个假设去生成和优化代码(Row Classifier),用于分类每一行是正常情况还是异常情况。
- 接着Tuplex执行pipeline。生成的分类代码对每一行执行一个简单的初始检查,以确定该行能否按照常规情况运行。如果对某一行检查失败,则将其放入到异常池(Exception Row Pool)中进行后处理,而大部分的行继续优化常规情况(Normal-Case)下的执行。
- 最后,在常规处理完成后,Tuplex尝试解决异常情况的行(Resolve Logic)。Tuplex使用通用的但是速度比较慢的代码或者使用Python解释器自动解决一些异常,而对于其他异常,则使用用户提供的解决方案。
- 如果解决方案成功,Tuplex合并异常行的处理结果到常规情况的结果中。如果失败了,则添加异常行到失败行池(pool of failed rows)中,并向用户报告。
Design
Tuplex必须保证Tuplex中的UDF执行行为与在Python执行器中一致。对于这个抽象只有两种例外
- Tuplex绝不会因为不能处理顶级异常而崩溃,而是模拟一个隐式捕获所有异常处理的程序,记录未解决的行
- Tuplex在UDF上的假设是纯粹且无状态的,这意味着他们重复的异常是没有可观察到的副作用的。
Establishing the Normal Case
Tuplex会记录样本中结构和数据类型的统计信息
-
Row Structure:输入会有不同的列数和列的顺序,Tuplex计算每个样本行的列,构建一个直方图,并选择prevalent的列作为normal case.
-
Type Deduction:Tuplex基于样本直方图中每个列类型进行类型推断。这种方法称谓数据驱动的类型推断,使用这个方式的原因在于Python udf缺乏足够的信息来进行静态类型推断而不产生歧义,并且因为输入数据中的实际类型可能与开发人员的假设不同。
比如有句号的数字字符串就是floats,总是0或1的整数,ture和false是booleans,带有JSON结构的字符串是字典,空值或显式字符串“NULL”的是None,对于其他检测不出来的就默认是string。
-
Option type(None):Tuplex使用样本来指导Normal Case的specialization。如果空值的频率超过阈值,则假定None为Normal Case,如果低于,则是Exeptional Case,如果在,则使用多态可选类型并进行必要的检查再生成代码。
Code Generation
Tuplex解析pipeline上的Python UDF代码,使用normal-case的types输入到抽象语法树(AST)中,然后生成用于每个UDF的LLVM IR。生成的代码可以假定一个静态类型赋值,而不是准备处理任何类型。此外,Tuplex依赖于数据分析设置的属性和LINQ-style的pipline API,对比与传统方法,其简化了代码生成,对任意的Python程序:
- 不会在解释器上产生副作用
- 没有跨行的状态
- 虽然UDF可能包含任意控制流,但是他们总是返回到调用操作符中,不能递归。
生成代码的过程包含:row classifier,optimized normal-case code path,general-case code path。
-
Row Classifier:其检查是否一行的每一列都是normal-case的结构和类型,如果是就直接在normal-case path上继续执行这一行。否则,生成的分类代码将复制他到exception row pool等待后续处理。
- 这个设计保证了normal-case过程关注核心UDF的逻辑,而不包括增加了复杂性和破坏控制流的异常处理解决代码。
-
Code Paths:所有的Tuplex’s生成的代码必须遵循执行必须与Python语义匹配的顶层不变性。Tuplex为每一个UDF跟踪Python的AST,为其遇到的语法结构生成对应的LLVM IR。只是对于normal-case和general-case的代码策略不同。
- 对于normal-case,在normal-case路径中仍然包含检测会在Python中出发异常的情况的代码。
- 对于general-case,general-case path总是假设每个列的最通用类型,此外其为实现可编译UDF的任何用户提供的解析器嵌入代码。
-
Memory Management:Tuple使用一个简单的slab分配器,从线程本地的预分配区域为UDF中的新变量提供内存,并在UDF返回并复制结果后释放整个区域。
-
Exception handling:为了模拟Python解释器的执行,Tuplex为一行生成和执行的代码必须没有偏离Python解释器中完全执行的可观察效果。下图展示了异常如何在不听的代码路径中传播。
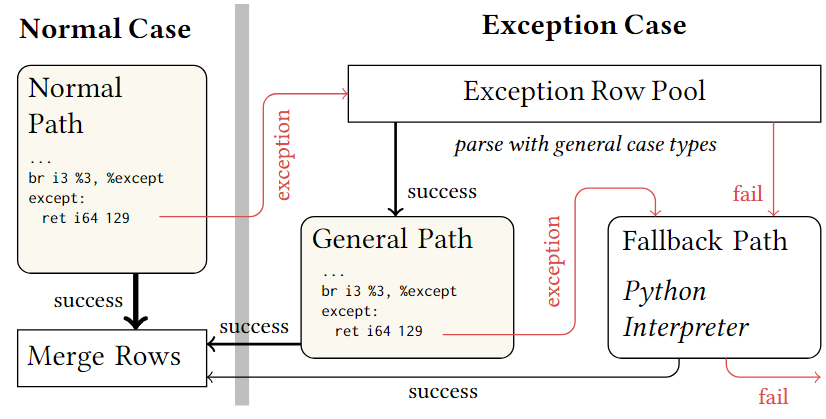
对于normal-case的row,生成代码即可,若在normal-case中检测到异常,则放入到Exception Row Pool中,在所有的normal-case row处理完成后,再处理ExceptionRow Pool中的row,如果row可以使用General Path解决并且不会出现异常,则与normal-case中生成的代码合并,如果出现了异常就传递到Fallback Path中。如果Exception Row Pool中的row不能使用General Path也直接传递到Fallback Path中,在Fallback Path中直接用Python解释器执行,如果能成功执行则将Normal-case生成的代码,和general-case处理成功的代码进行合并,反之则告知用户UDF存在无法解决的异常。
通常大部分的row都只执行一个path,很少会有row执行一个路径以上。
Execution
Tuplex有一个采用了逻辑优化的逻辑计划器(logical planner),一个用于分离pipeline不同stage执行的物理计划器(physical planner),还有一个用于处理实际代码生成的UDF compiler。
Stages:一个Stage是一系列操作符,包括UDF,他的两端是一个操作限定符,该操作符从内存中消耗物化数据或生成数据。Stages是代码生成的单元,Tuplex为每一个stage生成和执行normal-case和exception-case code path。
Joins
Tuplex使用hash join,在join的一段将记录物化,并在另一端进行流处理,以便查找哈希表。通常选择更小的一边作为build side,当物化join的输入时,结束这个Stage。对于,首先可以分为normal-case和exception-case两种情况,分别用和表示,同样的也可以,因此,要实现则需要将A中的集合和B中的集合两两之间join再取并集,于是有
Tuplex为join的build side执行所有的代码路径,并在执行另一端的任何代码之前解析其异常行为。如果构建方为B,那么其解决异常行的结果为,于是使用作为长stage的一部分,并且没有对进行物化。
Aggregates
Tuplex使用general和fallback code paths分别聚合normal-case rows和exception-case rows。在最后合并的步骤中,其结合分区聚合到最终的结果中。为了实现跨行跟踪累积状态,aggregation需要接受一个带有行参数和累加器参数的UDF,并返回一个更新的累加器,其在UDF中的表示为lambda acc,r: acc+r['col'],其中acc就是累加器参数。
Optimizations
只有在normal-case中才有优化,大概以下几种
- Logical optimizations:将选择操作(filter,projections)放到pipeline的开头是经典的数据库优化方式。系统将Python UDF当做一个黑箱,不能使用跨UDF的优化。Tuplex的logical planner分析每个UDF的Python AST去决定那些输入对象应该被保留,删除和修改,以便于只保留需要的列。
- UDF-specific optimizations:Tuplex为Python UDFs采用标准的编译优化,比如常量聚合。Tuplex将特定域UDF的优化作为LINQ-style pipeline的一部分应用。比如:在编译时一直字符串键的字典重写为元组,避免字符串操作;打平嵌套的元组,避免指针间接指向;优化common case的nullable value,即列的类型可以为NULL。
- Code generation optimizations:在normal-case path上,Tuplex取出了任何有关分类为异常类型的代码。比如对于
lambda m: m*1.609 if m else 0.0,的输入样本大部分为非0浮点数,Tuplex去除了整数向浮点数的转换,空值检查的代码,同时还取出了else分支。这使得生成的代码量从17个LLVM IR指令变为9个IR指令。如果common-case输入的值为null,Tuplex简化normal-case path为3个IR指令,并返回0。 - Compiler optimizations:一旦Tuplex为正常情况下的路径生成LLVM IR,它将对代码应用几个LLVM优化器传递
值得注意的是,因为优化要与Python中执行一致,因此并不是所有的优化方法都是可行的。
Implementation
使用LLVM 9’s ORC-JIT去编译生成的LLVM IR代码。当用户在Python module或Jupter Notebook调用时,提供一个实现好的C-extension。
Multithreaded Execution:在一个服务器上,运行执行器在线程池中。执行程序在单个任务中处理输入数据分区,并运行相同的代码。每个线程有他自己的bitmap-managed block manager来进行内存分配。当调用fallback path时,Tuplex请求父Python进程的全局解释器锁(GIL)。
Distributed Execution:在分布式集群中,许多服务器并行地处理输入数据。Tuplex分离每一个状态到许多数据并行的任务中,在一个Lambda function中运行每一个任务。driver machine生成LLVM IR,启动和监督Lambdas。
Exception handling:Tuplex使用特殊的返回码实现在normal-case和general-case path上的异常控制流。
Liminitations:原型支持许多编译优化代码,但是并不是所有Python语言特征。目前尚未支持while循环,生成表达式,try-except,set, async expressions, classes, obejcts, nested functions以及exernal modules。对于为支持的语言特性,Tuplex在执行过程中将绘图到UDF的Python解释器中进行执行。
Evaluation
End-to-End Performance
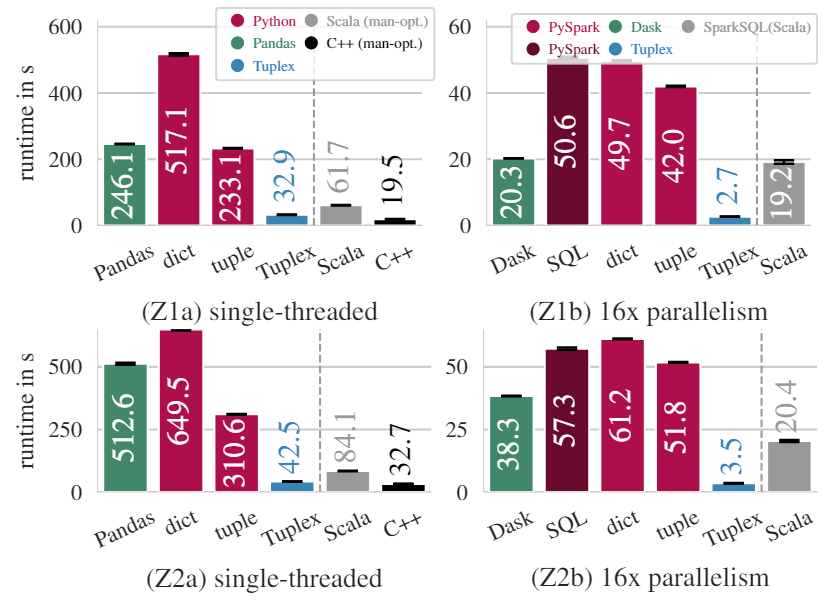
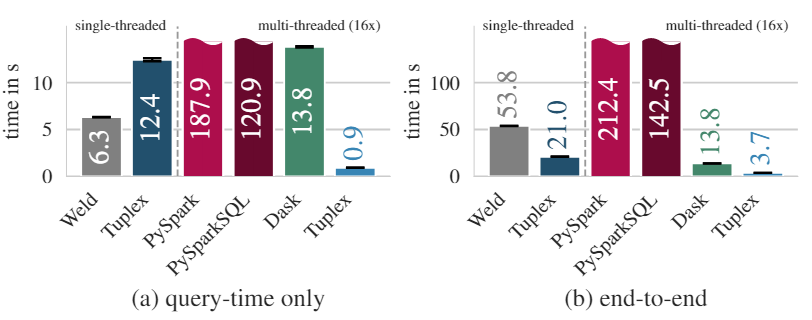
在Zillow数据上(有较多字符串处理)的实验结果,在单线程中(左边两幅)两条红色的Python是指分别使用dict和tuple解析行,从图中可以看出在单线程中,Tuplex经过端到端优化生成的代码处理速度是比较快的,与手动优化的C++非常接近。并且比Pandas和Scala的速度都要快。从图中还可以看到Pandas的速度是比tuple的CPython慢的,因为Pandas还有将numpy转化成Python list的开销。总之在单线程中,Tuplex有比较不错的表现
在16线程的实验中(右边两幅),Tuplex端到端的优化已经完全超过了其他的pipeline。这两个实验结果证实了Tuplex的代码生成和端到端优化为UDF-heavy的pipeline提供了性能上的提升。
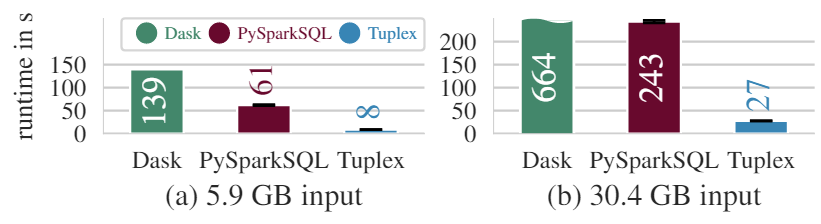
在Flights数据集中,某些列通常包含有空值,在这种情况下,Tuplex从他的样本中推断每个列的normal-case为空值的状态,并将解析异常行为所需的更加复杂的逻辑延迟到general-case code path中,从而有了更佳的效果。从图中也可以看到Tuplex执行速度更加快,PySparkSQL因为有对Join的SQL优化,因此速度会比Dask快。
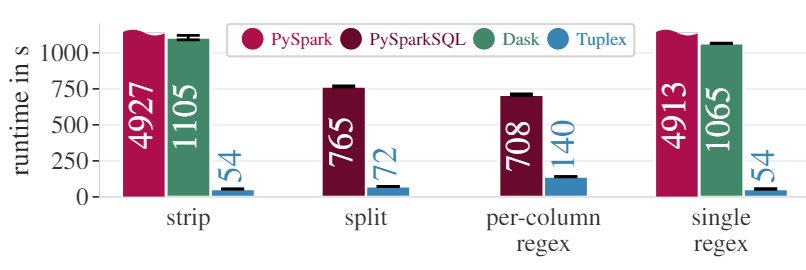
在Logs数据集中,处理这个数据集需要将日志拆分成列,然后如果其中一列与用户名模式匹配(正则表达式),则使用随机字符串重写其中一列。从图中数据也可以看到Tuplex在各个操作上的执行速度都要由于其他的内容,因为Dask执行split和per-column regex使用的是Python本身的解释器,所以没有数据展示。PySparkSQL可以使用类似split的SQL实现字符串的高效split,在per-column regex中也是使用SQL优化的正则解析,但是Tuplex仍然有较快的速度。Tuplex使用的PCRE2 regular expressions进行解析,他比java.util.regex(在Spark中使用)快8.85倍。
Exception Handling
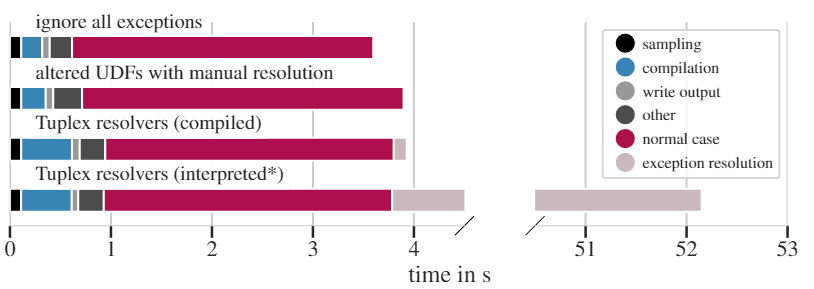
异常处理是在Zillow数据集的Z2上进行的实验,输入的56M行有百分之25是带有错误数据异常行。实验将Tuplex处理异常的方式分为3种
- 忽略并直接丢弃异常行
- 开发者在UDF中手动提供异常处理方案
- 使用Tuplex的解决方案
- 使用general path
- 使用Python的interpreter
实验结果如上图,不同的颜色表示Tuplex不同阶段的处理时间。
由于第一种方法直接舍弃了异常行,所以处理速度无疑是最快的。
在第二种方法中,在UDF中提供了异常处理的方案,异常处理效率比较高,但是增加了代码的编码复杂度。
而第三种方法,可以看到编译时间提高了,主要是Tuplex的general path在编译时会生成LLVM的IR,所以LLVM的编译也花费了一定时间。如果忽略编译速度,而只看数据处理速度,则这个方法是比第二种方法更加高效的,就算考虑编译速度,两者的差距也并不大,而且使用第三种方法不会增加开发者编写代码的复杂度。
对于第四种方法,由于直接使用了Python的interpreter所以异常处理过程通常都是最慢的。
Comparison To Other Systems
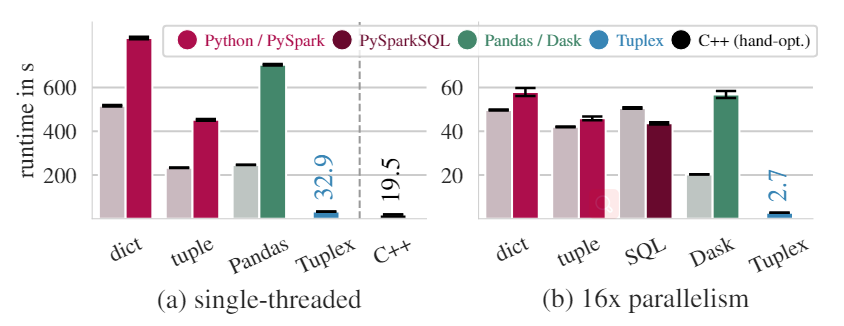
上图是和PyPy3进行编译的结果进行对比,其中每个颜色表示不同的方法,而灰色表示使用CPython解释对应方法的实验结果(即上面在End-to-End Performance的实验结果),可以看到是用PyPy3进行编译的效果在单线程中并不如直接使用CPthon进行解释,在多线程中使用PySpark的速度是CPython稍快一些,但是差距不大,而在PySparkSQL中则是使用PyPy的结果更快,在Dask中仍然是CPython占优。PyPy3效果不太好的原因可能是JIT编译和缓存的知识一些代码路径,而不是其他东西。尽管如此,从实验中仍然可以清楚地看到Tuplex的实验结果仍然是比PyPy3编译的结果好的,同时也与手工优化的C++的结果非常接近。
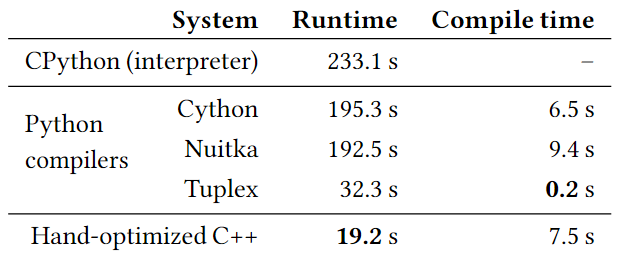
上图是和Cython,Nuitka对比的结果,至此使用的数据集是Zillow的Z1数据集。Cython和Nuitka将文件编译为共享库对象作为Python模块的替换项。从结果可以看出,Cython和Nuitka的执行速度是比CPython快速的,但是还是Tuplex的表现更加出色一些。预报为Tuplex使用native代码替换了C-API的调用,消除了不必要的检查,并使用了比使用CPython表示的Cython和Nuitka更有效的对象表示。
上图是在数据并行IR上的表现实验结果,这次使用的数据集是311数据集(cleaning workload)和TPC-H的Q6和Q19(filters and aggregations)。左边图是311,右边图是TPC-H。在查询时间中,在单线程中Tuplex的速度比Weld慢,但是Weld并没有解析字符串的能力,需要事先将字符串装换成整数,放入内存中,但是Tuplex的计算过程包括了编译,读取,转换等过程。在多线程中,Tuplex的表现仍然优于其他框架。
在TPC-H中,尽管Tuplex缺乏向量化的优化方式(Weld使用该方式),Tuplex的在filter和aggregation的表现仍然优于Weld。在多线程中Tuplex的表现仍然比其他的框架要快。Tuplex短刀端的性能提升,来自编译完整pipeline时,不是先加载数据后运行聚合,而是生成一个CSV解析器并将聚合代码内联到其中。
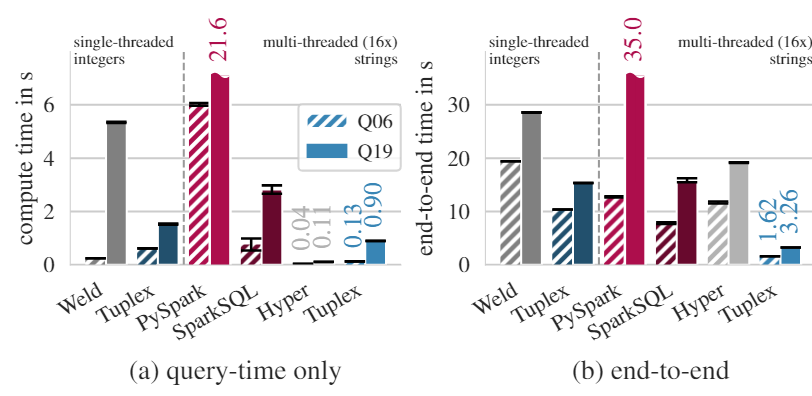
上图是在TPC-H Q6和Q19中,与SQL query compiler: Hyper进行对比。从查询上看Hyper有很好的SQL优化,加上在数据集上预先创建了索引,所以在查询上有很好的性能,而Tuplex需要进行一些处理,比如类型推断等,因此执行性能会比Hyper慢一些。而在端到端的优化中,Tuplex避免了预先创建索引,并通过生成的解析器将聚合与数据加载合并在一起。
Tuplex Performance Breakdown
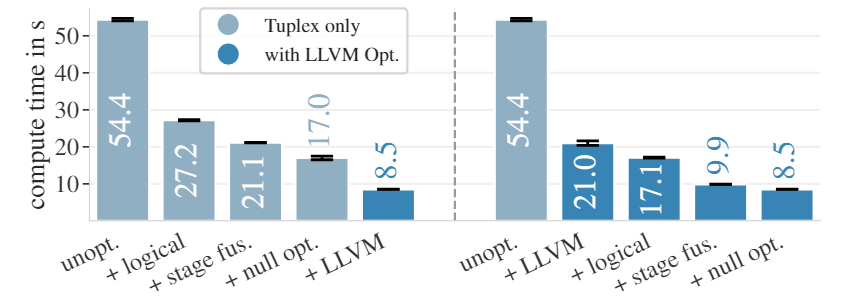
这个是特定设计对Tuplex的提升(实验是在flight数据集上进行的),左边这幅图,表示使用单独的优化方法(logical优化,stage fuse,空值优化)+Tuplex,最后一列是所有都用上之后使用LLVM优化,而右边图就是依次使用对应优化方法,每个方法都使用LLVM优化。从结果上看,每一个优化方法都对Tuplex的性能有提升。
Conclusion
- 数据中含有少量异常行将会导致Spark和Dask中难以正常运行,基于这一点,Tuplex提供了比较完善的异常处理方式(使用样本进行general-case path code生成,以及延迟处理exception pool中的异常),并且支持用户自定义异常处理。
- 将行表示为元组可以提高PySpark的性能,但是数字索引需要艰苦的工作才能实现。Tuplex避免了速度和可用性的权衡,对元组和字典(将字符串表示的字典重写为元组形式,避免字符串操作)具有相同的性能。
- 为了使null值与Dask/Pandas一起工作需要使用特殊的数据类型(比如,np.int64),而不是原生的Python类型,因为Pandas在None值上失败。基于这一点,Tuplex提供了对NULL的优化。
- 设计了特定目的运算符语义去帮助开发者避免UDF不同于Python code。比如SparkSQL的regex_extract在没有匹配是返回一个空的字符串,而Python用户希望返回NULL。这就导致了在SparkSQL中使用Python UDF在这种情况下将出现异常状况,而Tuplex本身的设计完全遵循在Python interpreter的结果一致的原则,因此Tuplex能够返回正确的结果。
Tuplex是一个新的数据分析系统,其将Python UDF便以为优化的native code。Tuplex的关键思想是双模处理,使UDF编译优化变得容易处理。
 微信
微信 支付宝
支付宝








