「论文笔记」PICASSO: Unleashing the Potential of GPU-centric Training for Wide-and-deep Recommender Systems
简要
针对的问题:
- 训练推荐系统中的GPU设备没有得到充分的利用,他们不能像CV和NLP领域那样实现预期的吞吐量提高。这个问题主要由两个特征引起
- 推荐模型包含了多达1000多个输入特征域,这引入了碎片化和内存密集型的操作
- 多组成特征交互子模块引入了大量的小型计算核
- 虽然定制的硬件能够对特定的WDL(Wide-and-Deep Learning)工作模式进行优化,但是需要考虑下面两个问题
- 有多种WDL设计,需要不同的工作模式(比如,特征域的数量,特征交互层的子模块),新的WDL模块每月都在出现。
- 对于公共云使用,处于预算和弹性考虑,首选商用硬件
- 通过详细分析大量的WDL工作流,得到下面的影响
- 由于有大量的特征域,WDL模型训练过程中有碎片化的操作,这通常会导致在加载操作中有比较大的开销
- embedding层由内存密集型和通信密集型的操作构成,而特征交互和MLP需要计算密集型的操作。在处理大量的嵌入参数时,计算资源将得不到充分利用,并导致像脉冲一样的GPU使用。
系统框架:PICASSO
- 创建细粒度embedding特征组,同一组内的操作被打包,以减少零碎操作的数量
- 来自不同组的操作从数据集和内核级交替进行,以提高硬件利用率
- 利用DRAM的大容量和GPU设备内存的高带宽,开发了数据分布感知缓存机制
主要贡献:
- 分析以GPU为中心的同步框架训练WDL模型时硬件利用率不高的原因
- 提出PICASSO通过软件系统的方式解决利用率不高的问题
- 构建了一个系统,其可以支持高达万亿参数和PB级的训练数据,在不增加预算的情况下平均实现6倍的训练性能加速。
分析工作负载的含义
WDL模型的结构
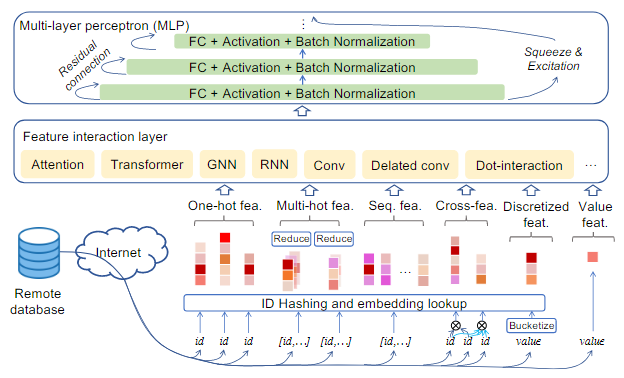
- 数据转化层(图中的最下面一层):以分类特征标识(ID)和密集特征向量的形式处理流训练数据
- embedding层:将稀疏分类特征的高维特征投影到低维embedding空间中,其内部主要由内存密集型的操作组成。
- 特征交互层:将embedding特征从embedding层中组织到几个不同的组中进行进一步处理,如图所示,可以使用Attention,Transformer和GNN等进行处理
- MLP:构建了多个全连接层,通过批训练数据提供最终的预测结果,在这一层中包含了很多计算密集型的结构单元。
WDL模型的分布式训练策略
- 参数服务策略(PS):训练数据分布在多个worker节点上,模型参数分配在多个服务节点上。worker会从server中拉取模型参数,使用本地训练数据进行训练,在一次迭代结束后,将相应的梯度信息传递给server,然后进行同步更新
- 数据并行策略(DP):训练数据分布在所有的wroker节点上,而模型参数复制到所有的wroker节点上,使用Allreduce的集合通信原语来聚合梯度,从而同步更新模型参数的本地副本。
- 模型并行策略(MP):存储所有参数在多个worker节点上,使用AllToAllv的集合通信原语在所有worker之间同步交换数据。
WDL工作负载的特征
从算法的角度来看,每个WDL层由一组操作构成,而不同的操作的执行通常需要各种硬件资源。
通常使用分布式系统训练的WDL模型所需的硬件资源通常可以分为3种类别:
- intra-node bandwidth(节点内带宽,DRAM和PCIe带宽)
- computing resource(计算资源,GPU流多线程处理器)
- inter-node bandwidth (节点间带宽,NVLink和以太网的带宽)
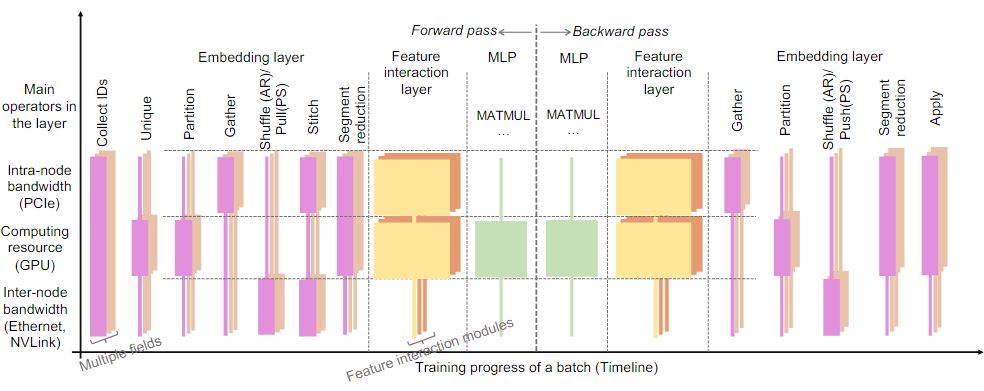
embedding层通常由下面的几个操作组成:
- Unique(消除冗余特征ID,减少内存访问开销)
- Partition(将类别特征ID分配到本地ID和远程ID中)
- Gather(从embedding表中查询本地ID)
- Shuffle(与远程worker通信以获取属于远程ID的特征embedding)
- Stitch(拼接本地查询特征embedding和远程特征embedding)
- SegmentReduction(根据语义池化特征embedding)
embedding层的操作大都是受到硬件资源的限制,而特征交互层和MLP的操作大都受到计算资源的限制。
在以GPU为中心的同步训练系统中,硬件资源的使用是零碎的,这意味着,在同一时间,训练将首先与一种类型的硬件资源,而其他类型的资源没有得到充分利用。
对比与CV和NLP,WDL的工作流有三个特征:
- embedding层和特征交互层涉及大量的小规模操作,这会产生显著的加载开销
- 在同一时间内,embedding层中不同特征域的相同操作可能会竞争相同的硬件资源,在硬件资源相对紧张时会限制系统的吞吐量
- 数据偏度将造成分布式系统中跨worker的硬件资源不平衡
PICASSO的系统设计
复合型分布式训练策略
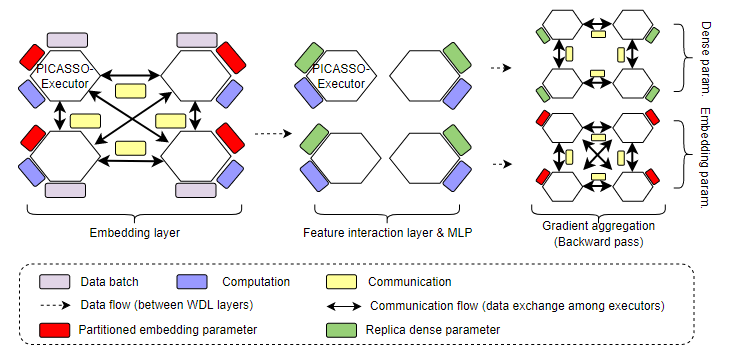
PICASSO设置了多个PICASSO-Executor,其中每个对应集群中的不同机器。每个PICASSO-Executor有异构硬件资源
- 计算资源:GPU流多线程处理器和CPU物理核
- 存储资源:GPU设备内存,DRAM,Intel持久内存以及SSD的多级内存子系统
- 通信资源:像NVLink,PCIe,InfiniBand以及Ethernet的分级互联
通过PICASSO-executor,PICASSO可以对WDL模型的不同层实现复合的分布式训练策略:
- embedding层:其中有大量的embedding参数,应该采用MP策略,embedding参数被分配到所有的PICASSO-Executor中,并存储在对应的分级内存子系统中,在所有的PICASSO-Executor中使用AllToAllv集合通信原语实现参数的同步交换。
- 特征交互层和MLP:比embedding层有更少的参数,应该采用DP策略。参数会被复制到所有的PICASSO-Executor中,并使用Allredcue原语进行聚合。
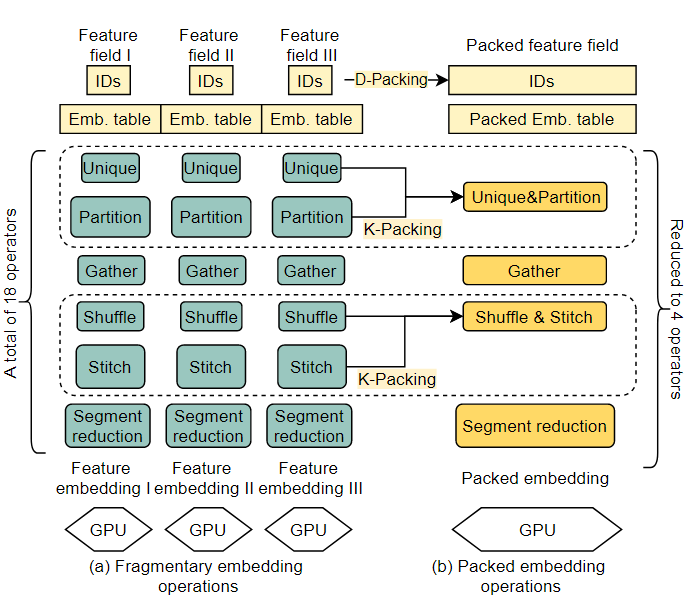
Packing
Data-Packing(D-Packing)
在embedding层中,当不同特征域的类别特征ID输入到相同的操作时,PICASSO结合这些类别特征到一个单一的packed ID tensor中,然后加载一个单一的操作(packed operation)去执行packed的数据。这显著减小了在GPU设备上加载大量操作的开销。这种方式会在有大量的并发查询请求时,收到hashmap的低级锁的影响。
因此要对直接的方式进行一定的修改,当他们的embedding表共享相同的特征维度时,将类别特征ID进行打包。
但是由于数据分布的偏度和较大的特征维度,一些打包操作仍然会遇到过多并发查询,从而影响hanshmap的吞吐量。
这里设计了一个通过估计打包操作参数量的方法评估执行开销:
N表示类别特征ID的数量,T表示打包的embedding表,表示embedding表的特征维度,表示类别特征ID的频率。N和将从warm-up的迭代的统计数据中获取。
如果打包操作超过了CalVParam(T)的平均值将会对这个embedding表进一步分成多个分片。举个例子,现在有一个packed操作A,其用于处理embedding表维度为8的数据,那么当embedding表维度为32时,就将32分成四份,分别用用4个A进行处理即可。
Kernel-Packing(K-Packing)
kernel融合是常见的深度学习系统优化方式,通常有两种类型
- 手动设计的大型kernel:错过了由不同硬件资源限制的交叉操作的机会
- 基于编译的代码生成:这个只能处理固定维度输入输出的数据。
在本文中,会根据对硬件资源的利用率分为三种类型:计算密集型kernel,内存密集型kernel,通信密集型kernel。
本文只融合类别相同的kernel,为在不同kernel组之间交叉执行留下机会。
综上所述,最后packing优化的流程(18个操作被优化成4个操作)如下图:
Interleaving
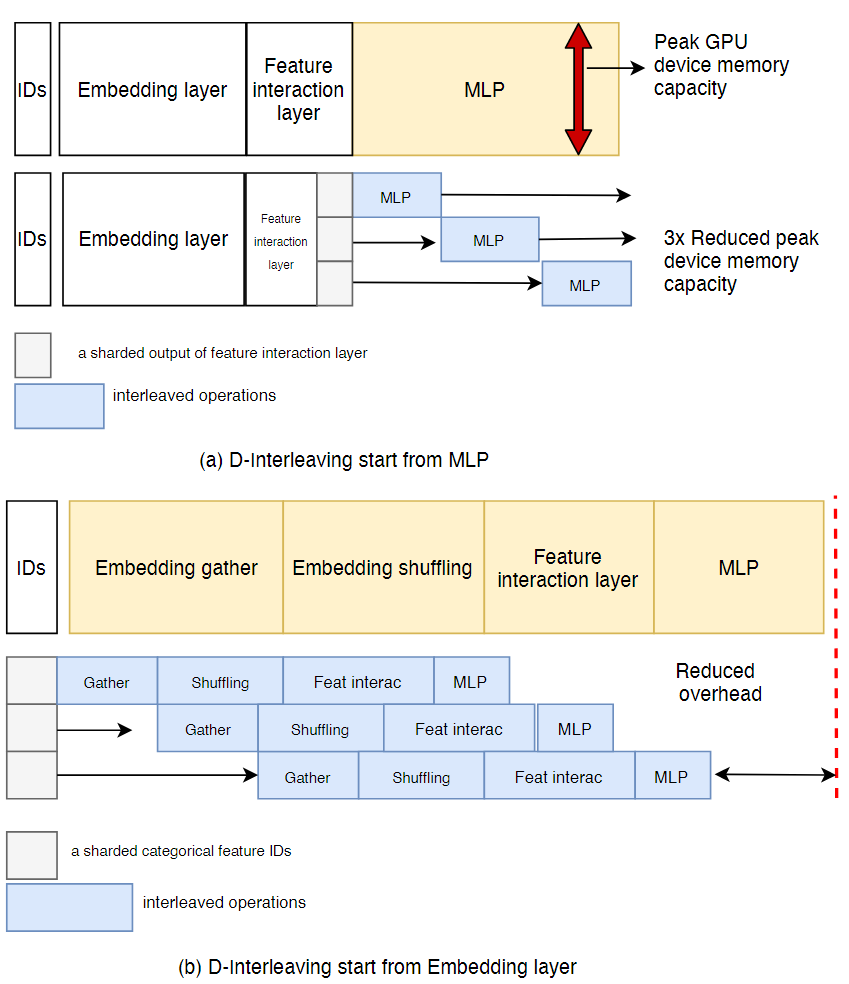
Data-Interleaving(D-Interleaving)
大规模的bs会出现out-of-memory的问题,但是大的bs对accuracy是有益的,因此PICASSO采用基于微批的数据交叉方法,允许用户在WDL模型的特定层中开始进行分片和交叉工作流。
如下面两个例子所示,
a:将特征交互层的输出划分为几个微批,并在MLP上使用D-Interleaving
b:将类别特征id划分为几个微批,并将D-Interleaving应用于其余的训练中
在执行过程中,将数据均匀地分为微批,以达到负载均衡,微批的大小可以通过下面的公式表示:
是估计的微批大小,表示操作的主要硬件资源的约束值(比如GPU设备的显存容量),表示操作的主要硬件资源的每个数据实例成本
Kernel-Interleaving(K-Interleaving)
在K-Packing中虽然融合了很多的操作,但是来自不同域的特征ID在相同的操作中仍然会竞争相应的硬件资源。在K-Interleaving中,会在packed操作组之间建立控制依赖关系,如下图所示:
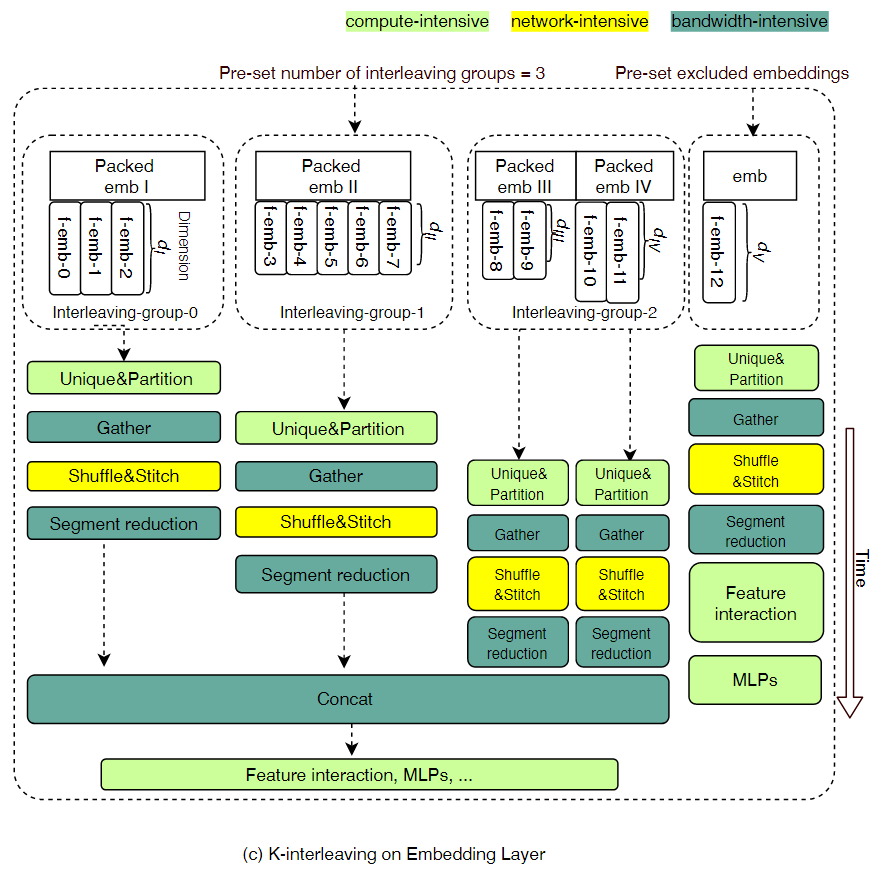
为了确保Interleaving group不会收到多种硬件资源的限制,首先需要确定每个Interleaving group的容量
和之前定义的相同,表示从操作的主要硬件资源中训练参数的开销(这里简单地将在embedding查询和交互的参数量作为开销)。
Caching
缓存被广泛因供应与系统技术中,利用分级存储子系统减少内存访问延迟。经过观察,20%的类别特征标签是经常被高频率查询的,基于这一点,提出了HybirdHash,用于解决两个硬件限制
- DRAM有很大的容量但是访问带宽比较低
- GPU设备内存有比较大的贷款,但是容量有限
如下图所示,在HybridHash中像一个hanshmap一样进行存储,获取以及更新embedding参数。
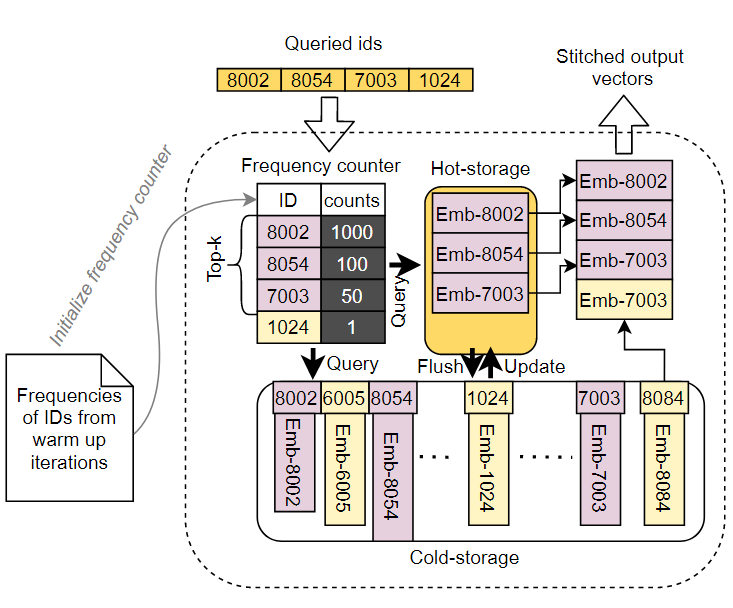
在这里,GPU设备内存是Hot-storage,DRAM是Cold-storage。
具体工作方式是,在预定义的预热迭代次数中,从hanshmap中记录每个查询ID的频率,从cold-storage中取出频率最高的前k个(k取决于hot-storage的容量)embedding到hot-storage中,在hot-storage中保留hottest的类别特征ID。之后大多数的ID查询任务会在hot-storage中完成,没能完成的任务也能才cold-storage中完成。此外,HybridHash能够拓展到多级缓存系统中(Intel’s持久化内存,SSD等)。HybridHash的算法为:
procedure:HYBRIDHASH(IDs,itr) CStore:cold storage to hold hashmap
HStore:hot storage作为缓存
FCounter:主机端记录ID频率的计数器
warmup_iters: Hybridhash预热的迭代次数
flush_iters: 通过CStore中的前K个特征更新HStore
IDs: 用于查询的类别特征ID
itr: 当且迭代
- if itr < warmup_iters then // 在预热期间
- for do // 遍历每一个ID
- FCounter(id) FCounter(id)+1 // 将频率记录到哈希表中
- feat(id) CStore(id)
- end for
- else // 预热结束后
- for do // 遍历每一个id
- if id在HStore中 then // id是否在hot-storage中
- feat_hot(id) HStore(id) // 取出hot-storage中的内容
- else
- feat_cold(id) CStore(id) // 否则取出cold-storage中的内容
- end if
- FCounter(id) FCounter(id) +1 // 访问频率+1
- end for
- feat = feat_hot feat_cold // 对结果进行聚合
- if itr%flush_iters = 0 then // 到达刷新次数后
- host_ids top-k(FCounter) // 取出哈希表中前K个hottest的 id
- HStore CStore(host_ids) // 放入到HStore中
- end if
- end if
- return feat
- end procedure







