简要
在推荐系统中大部分的方法为所有的特征固定了embedding的纬度,这可能会收到以下影响:
- embedding可能包含数百亿个参数,导致高内存使用和计算成本
- 过度参数化低频特征可能导致过拟合,甚至产生意外噪声
此外,高频特征需要更多的参数来传递有效的信息。
提出单次嵌入维度搜索方法(SSEDS),能够通过使用单次embedding剪枝操作有效的分配每个特征域对应的维度同时保持模型的推荐准确率。
如何自动地为不同的特征分配embedding维度是很重要的问题,本文称为embedding维度搜索(EDS)问题。
这个问题需要解决两个挑战
- 如何识别各个特征域的embedding维度
- 识别embedding每个维度的重要性,然后去除不重要的相关维度,以实现自动获取混合维度embedding
- 标记每个特征域的embedding维度,同时保持其他的不变。然后通过评估他对损失函数的影响,计算每个维度的显著分数,以此表达维度的重要性。
- 如何通过一种有效的方式搜索embedding维度
- 通过观察显著分数,可以对所有特征域的embnedding维度进行降序排列,并根据给定的参数预算保留有限的部分。
- 如何聚合SSEDS到传统的推荐模型中
- 首先以标准的方式对传统模型进行预训练,然后通过使用single-shot embedding pruning获得具有混合维度embedding的超薄模型,接着使用预训练和混合embedding初始化和重新训练slim模型,并为每个特征字段引入额外的变换矩阵来对齐维度,以便进一步的特征交互操作。
贡献点:
-
提出有效的单词嵌入搜索方法SSEDS,引入了一个通过一次前向-反向传播就能识别每个特征域的每个embedding维度的重要性。
-
SSDES是模型不可知的,提出利用线性变换矩阵来对齐不同特征域的维度,使其能够无缝集成到各种基本的推荐模型中。还能灵活地控制袖箭参数的数量,以满足不同的参数预算要求。
方法
问题描述
基于特征的推荐系统的典型训练数据D通常由用户点击记录构成,每个点击记录(x,y)∈D的表示为:
(x,y)=({x1,x2,…,xm},y)
其中x={x1,x2,…,xm}表示原始特征向量,由于用户和物品相关的m个特征域拼接而成。y是一个二元标签(1表示点击,0表示不点击),描述了用户对给定物品的喜好。对于每个特征域,他通常包含一个确定数量的独一无二的特征,因此第i个域的特征向量xi∈x通常被编码为高维稀疏one-hot或者multi-hot的向量。为了进一步提取用户的喜好,大部分现代基于特征的推荐系统将xi∈Rni(ni是在第i个域的独一无二的特征的数量)映射到低维密集空间ei=Vixi中。其中Vi∈Rd×ni第i个特征域的embedding表,d是共享在所有域的embedding维度。整个embedding表V={V1,V2,..,Vm}可以通过链接每个域的所有嵌入表来获得。
因此,基于特征的推荐系统f的目标是预测用户是否会点击这个物品的概率p
p=f(x∣V,Θ)
其中Θ表示模型的其他参数
最后,为了得到混合维度embedding,基于EDS方法的embedding剪枝的目标是根据parameter budge κ∈(0,1],从整个embedding表中识别和去除一定数量的embedding维度,同时最小化损失函数
V∗,Θ∗=V,ΘargminL(V,Θ;D), s.t. ∥V∗∥0<κ∥V∥0
其中L是损失函数,∥⋅∥0表示L0范数,最终优化剪枝的嵌入表所期望的非零参数V∗。
SSEDS
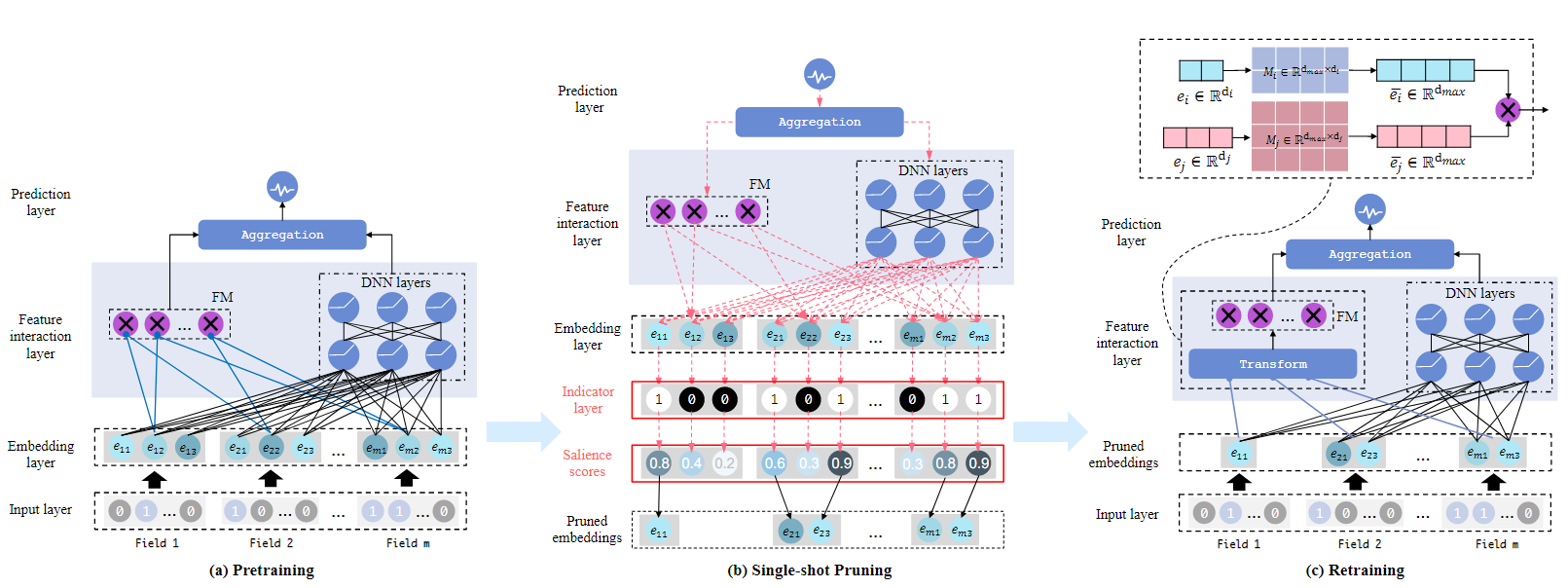
SSEDS有三个阶段,Pretraining,Single-shot Pruning,Retraining。在Pretraining阶段是使用标准的方式训练统一维度的推荐模型,通过标准的方法的over-parameterized embedding会更加具有表达性。在Single-shot Pruning阶段会首先计算每个embedding维度的显著份额数,然后降序排序,然后以序列的方式去除维度,直至到达预先定义的参数预算,从而获得混合维度的embedding。最后的Retraining阶段,由于传统模型在特征交互层中需要相同的维度,因此在直接使用混合维度的embedding之前,需要使用转化矩阵,将混合维度的embedding与特征交互层的参数进行对齐,然后再进行训练。通过这样的方式,混合维度embedding能够轻易地聚合到出传统模型的结构上。
Pretraining
对于每一个训练实例,嵌入层使用原始特征x={x1,x2,...,xm}作为输入,并将其通过公式1:ei=Vixi映射到embedding e={e1,e2,...,em}中。然后使用特征交互层的特征交互操作g(⋅)去捕获这些embedding V中的隐式交互关系:
公式2:z=g( V,Θ)
当z作为要输入到最后的预测层的特征,其得到预测可能性p的过程如下公式所示:
公式3:p=sigmoid(z)
在embedding层和特征交互层的可学习参数分别为V和Θ。损失函数L(V,Θ;D)用于测量模型预测可能性p和ground-truth标签y的差异,通过下面的公式
公式4:L(V,Θ;D)=−{x,y}∈D∑{y⋅log(p)+(1−y)⋅log(1−p)}
通过最小化损失L(V,Θ;D),可以得到最优的在所有特征域上具有统一embedding维度d的embedding表 V^ ,以及其他的参数Θ^。
Single-shot Pruning
在这里引入了一个显著性标注去区分每一个域i∈{1,...,m}以及每一个维度j∈{1,...,d}中的每一个 V^ij的embedding维度的重要性。引入了一个二元参数的辅助指标层α={α1,α2,...,αm},αi∈[0,1]d×ni。然后对于期望的参数开销κ,可以重新定义目标函数为:
公式5:minV^,Θ^,L(V^⊙α,Θ^;D) s.t. α∈{0,1}d×∑imni,∥α∥0<κ∥V∥0
其中⊙表示Hadamard乘积。α和V^有相同的大小,然而本文不尝试直接最优化公式5,而是利用α去决定每个embedding维度的重要性。具体来说,本文会通过标记他同时保持其他维度不改变embedding值的方式独立地测量第i个域的第j个维度对损失函数的有效性,接着测量loss值的变化
公式6:ΔLi,j=L(V^⊙1,Θ^;D)−L(V^⊙(1−ϵi,j),Θ^;D)
其中1是一个全为1,维度为 ∑imni×d的矩阵,指标矩阵ϵi,j∈{0,1}∑imni×d是一个二元向量,其除了在第i个域的第j个维度上,其他地方全为0。然而,计算所有的ΔLi,j是非常昂贵的。另一方面L对于α是不可微的。因此简化α的二元约束到[0,1]之间,这样在α=1时,ΔLi,j可以近似地用梯度∂L/∂αi,j(表示为gi,j(V^,Θ^;Db))表示。
公式7:ΔLi,j≈gi,j(V^,Θ^;Db)=∂αi,j∂L(V^⊙α,Θ^;Db)α=1=δ→0limδL(V^⊙α,Θ^;Db)−L(V^⊙(α−δϵi,j),Θ^;Db)α=1
通过这种方式,能够通过只通过一次前向-反向传播,自动地在数据集D的mini-batch(表示为Db)上,有效地计算所有的gi,j(V^,Θ^;Db)。gi,j(V^,Θ^;Db)的数值比较大意味着相应维度对损失函数的影响更好(积极或消极),因此应该保留。基于这个假设,第i个域的第j个维度的显著性分数si,j为gi,j(V^,Θ^;Db)的归一化值。
公式8:si,j=∑i=0m∑j=0dgi,j(V^,Θ^;Db)gi,j(V^,Θ^;Db)
在得到所有的显著性分数si,j后,将他们进行降序排列,然后序列化地去除低显著性分数的维度,直至到达参数预算κ,αi,j的计算方式如下:
公式9:αi,j=I(si,j−s~≥0),∀i∈{1,…,m},j∈{1,…,d} s.t. ∥α∥0<κ∥V∥0
其中 I(⋅)是指标函数,分位数的值s~自动地由参数预算决定。
Retraining
在完成剪枝后,混合维度embedding表V={V1,⋯,Vq}q≤m2,Vi∈Rdi×ni会被自动地获得,其中di是第i个域的搜索空间,q是剪枝后域的数量。然而传统推荐模型,比如FM和DeepFM由于特征交互操作,要求输入的embedding维度一致。为了使剪枝的embedding能够聚合到多个模型结构中,需要对齐embedding维度到不同的域中。本文利用一个简单而有效的方法去对齐维度,具体来说,本文只引入q个域变换矩阵M={M1,…,Mq},Mi∈Rdmax×di,其中dmax=max(d1,⋯,dq)是对齐embedding维度等于所有搜索维度中的最大维度。本文可以得到对于特征xi对齐后的embedding ei∈Rdmax。
公式10:ei=MiVixi
值得注意的是,我们只引入了一小部分的额外参数。此外,Mi能够提高剪枝embedding Vˉ的表示能力
- 他们被映射到具有更多视角用于表达的更高维度空间
- Mi在i域中的所有特征实例中共享。
因此他们共同的特征被进一步建模。在对其之后传统推荐模型在第i个域和第j个域之间的点积操作<⋅>能够被执行
公式11:<ei,ej>
此外点积操作,剪枝的embedding也容易适应到其他特征交互操作中。比如,DNN层只需要去适应输入层的维度,以匹配embedding层输出的维度。
在对其之后,需要重新训练embedding表Vˉ,转换矩阵M,最终轻量模型的其他模型参数 Θˉ 。
伪代码
算法1:SSEDS算法
要求:训练数据D,基本模型f(V,Θ),参数预算κ,损失函数L
确保:混合维度embedding表V∗使得∣∣V∗∣∣0<κ∣∣V∣∣0
- Pretraining:
- 优化V和Θ: V^,Θ^←fV,Θ属于基本模型f
- Single-shot Pruning
- 采样一个mini-batch的数据集Db∼D
- 识别第i个域的第j个维度的显著性分数sij(公式8)
- 降序排序sij
- 剪枝embedding表Vˉ←V^(公式9)
- Retraining
- 对齐embedding维度(公式10)
- 重训练轻量模型V∗,Θ∗←V^,Θ^







