「论文笔记」Hercules: Heterogeneity-Aware Inference Serving for At-Scale Personalized Recommendation
简要
现象:数据中心的深度学习推荐系统具有许多独特的工作负载特征和系统需求——模型多样性、云规模的系统异构行和时变负载模式。这些都需要特定于应用程序的解决方案来提高执行效率。
问题:
-
模型多样性:推荐模型的迅速发展,以支持新的用例,并实现更高的预测精度。这种不同算法结构导致了不同的性能瓶颈。最先进的推荐模型的计算和内存强度可以变化1~2个数量级。
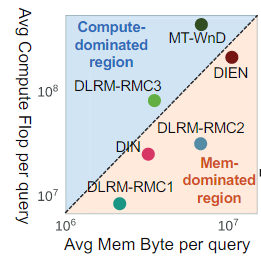
-
云规模的系统异构:各种各样的系统架构可以在数据中心中共存,其原因如下:
- 系统升级会周期性的发生,不同微架构的服务器一代又一代地出现
- 特定领域的加速器越来越多地部署在数据中心,以最大化执行效率
-
时变负载模式:查询到达服从泊松分布,查询大小呈明显的重尾分布。动态变化的条件要求调度程序在不同级别运行,以快速适应和响应负载变化。
-
最优调度鞠策高度依赖于模型和硬件,并且需要一个有效的搜索机制来充分探索所有SLA(服务级协议)目标在模型并行、操作员并行和数据并行维度上的大调度空间。但现有的任务调度器设计缺乏遍历整个并行空间的能力。
方案:
Herules——heterogeneity-aware recommendation using latency- and energy-conscious scheduler—tailor-designed for at-scale neural recommendation inferences.(用于大规模神经推荐推理的使用为低延迟和节能调度量身设计的异构注意推荐)
其有两个阶段:
- 脱机分析阶段:Hercules详尽地探索了任务调度的并行空间,并未工作负载/服务器类型对的所有排列派生了一个效率元组
- 在线分析阶段:Hercules在集群及使用效率元组进行异构感知发放,解决约束优化问题最大限度地降低数据中心资源成本。
贡献:
- 将广大的设计空间转化为一个约束优化问题,提出一个有效的搜索方法,其能为异构注意的集群调度进行有效地探索并行空间,并识别最优的执行方案。
- 与最先进的SLA感知调度程序相比,本文为任务调度确定了未探索的并行空间,实现了1.03x到9x的延迟受限的吞吐量改进。
- Herucles可以实现高达47.7%的集群容量和23.7%预置电源节省最先进的贪婪调度器,使得集群资源效率变得更高。
Insights
- 对于进一步促进延迟限制吞吐量(QPS)和能源效率(QPS-per-Watt)方面,在模型调度上的并行维度和工作流不平衡的底层探索仍然有显著的提升空间(观测到同样是20个线程,一核20线程和2核,每核10线程的性能表现不一样,后者可以取得更高的执行效率。还观测到当worker的数量增加时,CPU存在的idle时间会变长)
- GPU这样的加速器受益于模型共存和查询融合的并发探索,与最先进的调度器相比,实现了7.87倍的吞吐量和3.36倍的能源效率提升,但是由于内存容量优先,他们无法容纳大型模型。(观测是使用三个不同的推荐模型,使用三种不同的策略(无模型共存无查询融合,单模型共存,模型共存+查询融合)进行评测,使用了模型共存+查询融合策略的推荐模型都取得了最好的表现)
- 尽管具有异构感知能力,但当多个工作负载竞争相同的服务器类型时,最先进的贪婪调度器无法正确分配服务器,导致次优的解决方案
Hercules设计
总览
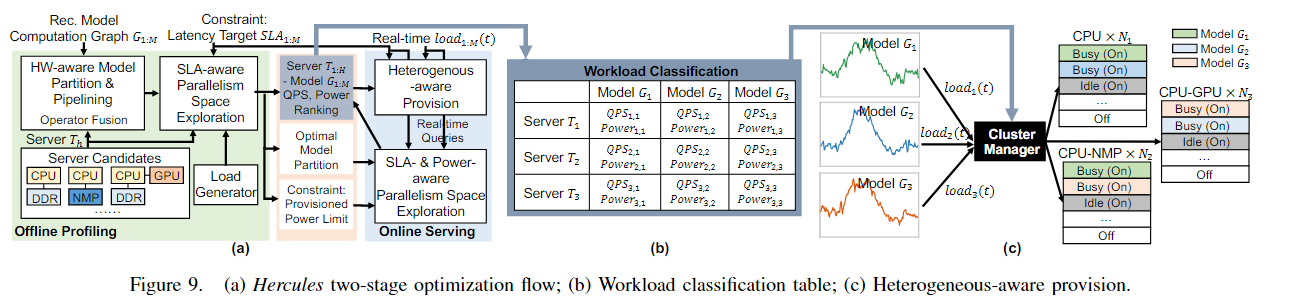
Hercules由两个主要的stage组成:离线分析和在线服务
离线分析:最大化单个服务器上推荐工作负载执行的效率,并为所有工作负载/服务器类型对记录一个效率元组
在线服务:将离线分析的记录输入到集群调度器中,用于调度集群
:将推荐模型形成一个计算图,这个计算图就是
:对应的SLA延迟目标
:的服务器候选集
在离线分析中,首先为每个和对,执行HW-aware Model Partition(图9,a的左上角)使其满足大型推荐模型在硬件上的内存容量约束,然后执行SLA-aware task scheduling exploration(图9,绿色框,第一行,第二个),以获取在满足SLA延迟目标上的最大延迟限制吞吐量。然后以表格的形式(像图9b)记录延迟限制吞吐量和测量的峰值功率。这些记录对每个工作负载的可用服务器体系结构进行定量分类。
在线服务时,首先通过运行SLA- & Power-aware task scheduling exploration(图9,a的蓝色框下面那个)来执行初始化设置,以确保使用实时查询进行准确的分析。这里他必须满足两个条件(图9,a的蓝色框上面那个):SLA延迟目标以及功率开销要在功率预算之内。在离线分析中记录的效率元组也会实时更新,以衡量实时查询负载的性能。
通过定量工作负载分类,将集群提供描述为一个全局资源成本最小化目标的约束优化问题。动态分配适当数量的最佳匹配服务器,以满足传入的每日负载。
梯度引导的任务调度探索
在单个服务器上的推荐推理需要满足三个约束:硬件资源,SLA延迟,满足功率预算。Hercules执行硬件注意模型分区使其满足内存容量,并进行满足SLA延迟和功率预算的并行空间探索。
硬件注意模型分区和流水线
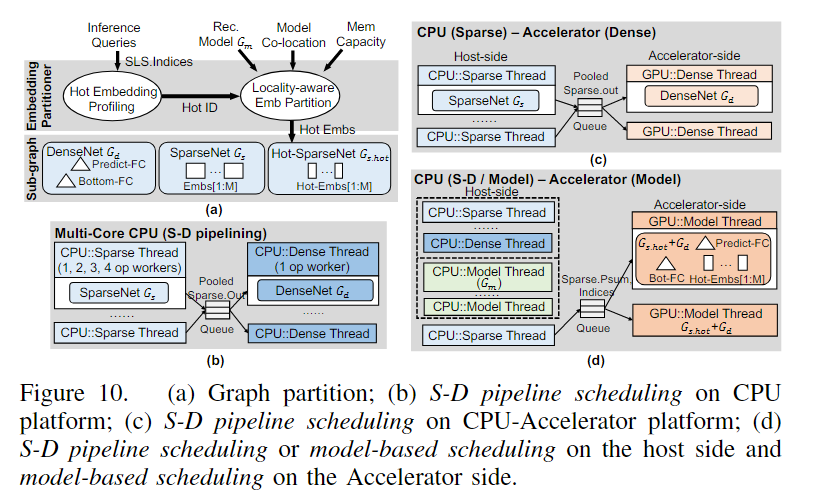
本文观察到95的模型内存占用适用于在稀疏网络的embedding表上,而密集网络的则只有几MB,于是,如图10的a所示,本文提出了局部注意的embedding分区方法去识别hot embedding实例,并通过访问频率去排序他们,形成hot embedding表。hot embedding表的数量又每个线程的容量预算(内存容量和模型共存)决定。原始的模型将被分为3个部分:密集网络,拥有整个embedding表的稀疏网络,拥有hot embedding表的。
这里先要介绍两种调度:
- 基于模型的调度:如图10的b所示,他将CPU资源划分为密集线程和稀疏线程,将没有操作依赖的稀疏网络放入到稀疏线程中,有操作依赖的密集网络放入到密集线程中。
- 稀疏-密集(S-D)流水线调度:如图10c所示,将稀疏网络放入到host端(可以简单认为是CPU),把密集网络放入到加速器端(可以简单认为就是GPU)
而Hercules使用的是交替执行两种调度的方法,如图9d所示,将热稀疏网络和密集网络放入到加速器端,然后host端则是放稀疏网络,这个是不携带部分的。(集合基于模型调度的稀疏线程和密集线程,同时结合S-D流水线调度的host端和加速器端)。
基于梯度的搜索
整个并行空间为,其中是每个线程的共存数,是每个线程的核心数,是batch size。结合所有的并行维度,他等价于。其中表示一个线程可以分配的核心数,因此只用探索的维度即可。
对于一个线程使用i个核心数的情况而言,从最少共存数和最少batch size开始,每次更新有三个选择:
- 增加共存数
- 增加batch size
- 同时增加共存数和batch size
通过这三种方式生成候选三个候选节点,然后计算三个候选点相对于其实点的尾延迟和吞吐量的梯度,分别表示为 和。并且要考虑到候选点必须满足用户设置的SLA延迟和功率的限制。当所有三个候选配置的吞吐结果都比当前配置低时,搜索将停止,并且报告这个配置在当前一个线程使用i个核心数是最优的配置。接着就可以遍历下一个情况。然后再比较和之间更优的选择,作为最终的选择。
伪代码如下:
算法1:基于梯度的搜索
数据:SLA延迟目标,功率预算
结果:调度配置
初始化:batch size, 线程的数量
- for (op-parallelism) in do:
#P(M+D)空间搜索- while do
# 三个候选- = $ \text { Latency }[1: 3] - \text{Latency}_{t-1}$
- if (max() and () and ()) then
# 吞吐量提升- 使用提升最大的候选点进行配置更新
- else
- 结束搜索
- end
- end
- if 操作并行的配置下吞吐量减少 then
- 结束并返回最好的配置信息
- end
- end
面向目标的集群调度优化
由于最先进的贪婪调度器在定量分配竞争最佳匹配服务器的优先级方面存在缺陷,因此需要一个数值优化目标来保证全局集群资源成本最小化。本文将这个问题描述为一个约束优化问题,优化目标是找到的值(公式1),使得整个功率预算最小。是分配给工作负载的服务器类型的数量,是获得率。和$ Power_{h, m}G_mT_h$上的限制延迟吞吐量和限制功率预算。
这里有两个约束需要满足:
- 对于所有的工作负载,分配给工作负载的服务器数量必须满足工作流在时间的收入加载 (公式2)。
- 激活的服务器数量不能超过容量限制(公式3),其中可使用的服务器的数量。
在图9c中,集群管理器为所有的服务器和工作负载对保留最优的限制延迟QPS和功率预算元组,并且知道对于所有工作负载在当前时间t内的。在运行最优的解决方案 后,集群管理器能够激活/释放服务器,并决定那个工作负载在激活的服务器上执行。动态供应以粗略的时间间隔(10秒为分钟)执行,以摊销工作负载设置时间的开销(10秒为秒)。设置超额供应率R以处理此时间间隔内的负载增量。R是通过分析时间间隔长度内的历史负载变化来估计的。







