「论文笔记」PetPS: Supporting Huge Embedding Models with Persistent Memory
简要
问题:随着embedding模型容量的不断增大,使用传统的参数服务器的存储成本高,在遇到宕机后重启的回复时间也很长。于是考虑使用持久性内存来拓展内存容量,但是持久性内存也面临两个挑战:高读取延迟和较重的CPU负担。
使用DRAM的参数服务器存储大型模型有两方面的缺点
- 造成了比较高的存储开销:DRAM是昂贵的媒介,同时DRAM几乎占整个系统功耗的一半
- 在参数服务器宕机后,将参数重新加载到DRAM中需要相当长的恢复时间,违反了在线推理的服务级协议(SLA)
持久化内存(也称非易失内存,PM)也支持像DRAM字节地址,但多提供了8倍的容量,同时提供了数据持久化的功能,并且可以提供更快的恢复和更少的停机时间。但仍然存在两个挑战
- 较高的持久化内存读取延迟(PM的延迟比DRAM高3倍)
- 较高的CPU负担(在和DRAM相同的CPU下,但是要处理8倍的数据空间)
方案:PetPS(Persistent Embedding Table Parameter Server)
- PetHash:最大程度优化PM哈希索引,以便于更好地减少PM的访问
- 使用单级结构来定位只读取一个PM的存储桶。
- 对于hot参数,利用hotness-aware放置来避免探测哈希索引,从而提供对他们的快速访问
- 其适当地预存可能访问的位置,以进一步隐藏高读写延迟
- NIC Gathering:将CPU的采集操作卸载给网卡。
- NIC的分散-收集直接内存访问(DMA)功能可以被重新利用到PM的参数收集上。于是在NIC中进行参数收集,CPU在读取参数时不需要再等待缓慢的PM了。
- 同时还结合了copy-on-write机制和本文提出的epoch-list-based space reclamation机制,解决DMA参数进行并发操作时产生的参数不一致问题,更好地保护DMA下的参数。
系统设计和实现
PetPS的结构
PetPS提供两个使用RPC暴露的接口
- Pull(IDs):用于获取 batch IDs的对应参数(在推理服务器上使用)
- Push(IDs, embeddings):用于更新batch的参数(用在模型更新上)
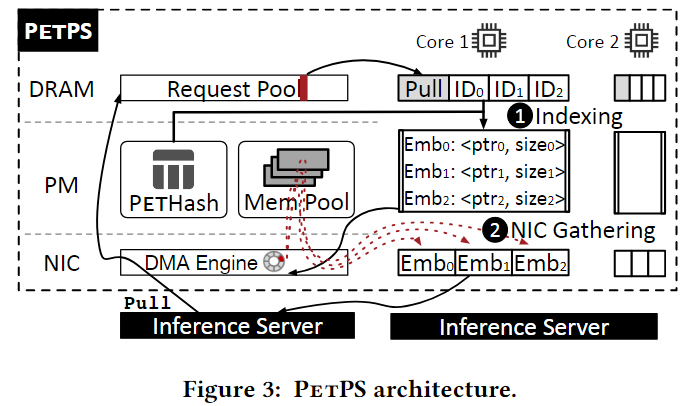
- PetHash是用在参数服务器上的一个高度优化的持久性哈希表,key是特征IDs,value是embedding 参数对应的内存地址。
- NIC Gathing是用于收集参数和将这些参数反馈给客户端的一个机制,他是NIC的DMA引擎的改进版本。
此外,PetPS包含一个基于slab的内存分配器(Memory Pool),管理用于存储embedding的PM空间。图中野展示了Pull请求的工作流,首先收到一个从推理服务器发来的Pull请求,PetPS首先在PetHash中查询在Memory Pool中的参数地址,然后利用NIC Gathering机制,从Memory Pool中收集参数,并返回给推理服务器。
PetHash
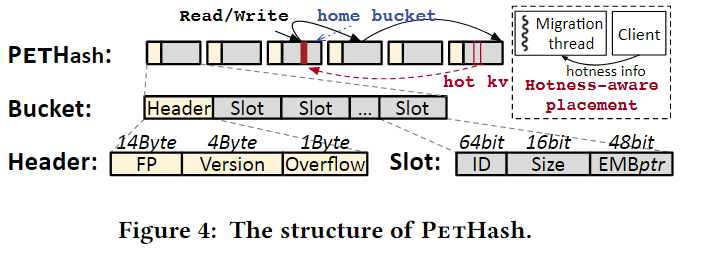
单级结构
PetHash选择了经典哈希表的单级结构,以降低读取成本。这种方法最明显的好处在于通过桶号直接定位桶,只读取一次PM。如上图所示,这里使用开放寻址的方法解决冲突。每个KV对都有一个对应的桶称为主桶(home bucket),由键的哈希值决定。KV对最好放在主桶中,但当主桶满时可以被移到其他桶中。
桶的头部由下面的元数据组成
- 14字节的fingerprint:用于加快桶内搜索
- 4字节的版本:启用桶级写锁和无锁搜索
- 1字节的溢出计数器:表示本应该放在这个桶中的数据,但由于这个桶已经慢了而被转移到其他桶中的KV数
对于插入操作,PetHash首先关联到主桶,如果主桶还有空间,就直接将KV对插入到其中,如果没有空间了,就使用线性探测的方法向后寻找合适的桶。探测的步长根据哈希值设定,避免连续桶满。
对于查询/删除/更新操作,PetHash会探测桶直到找到对应的key,或者遇到一个没有满的桶,但是key不在里面(意味着key不在里面)。然后在这个桶中执行对应的查询/删除/更新操作。对于删除操作,PetHash需要减少溢出计数器的数量。
Hotness-aware放置
核心思想是尝试将hot KV对放置在他们的主桶中,以便于找到他们时只用进行一次PM读取。PetPS使用客户端识别hot sets,应为PS的CPU资源是非常珍贵的,而客户端通常有控线的CPU资源。每个客户端会定期生成他的hot set(通过采样的方式),然后发送他们到对应的PS中,作为最终的hot set。
HetPS使用一个专用的迁移线程去移动hot keys。一旦收到一个新的hot set,PetPS调用迁移线程去检查,每个hot key是否在他们的主桶中,如果不在,就会先将hot key放入到主桶中,然后多出来的cold key会通过递归的方式寻找合适的桶进行放置,最后会把多余的cold key删除。
预取
pull请求通常包含成百上千个key,他们通常是按顺序进行索引的。因此在索引当前key之前,对下一个key进行的主桶启动预取指令。对于下一个键的索引,CPU缓存很有可能完全满足PM访问。通过这种方式,索引和PM读取是流水线化的,这样就可以在PetHash中隐藏大多数的PM读取延迟了。
NIC Gathering
NIC Gathering就是将采集工作从原本的使用CPU采集(Naive)转化成使用NIC的SG-DMA进行采集(PetPS)。下图是两种方法的直观展示。
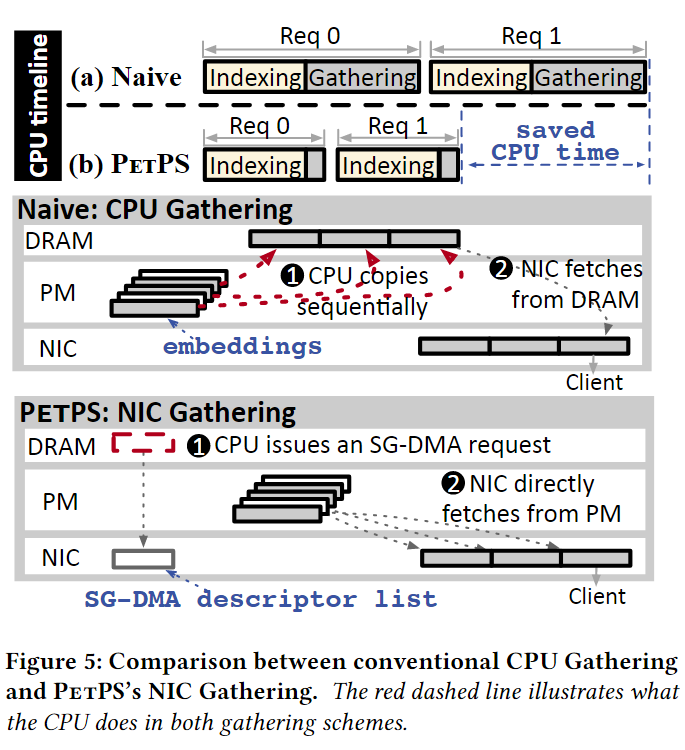
卸载embedding收集到NIC中
PetPS提供一个压缩DMA能力的消息布局。每个消息包含两个字段:
- header:确实embedding的数量和他们的特征IDs
- payload:压缩所欲在这个PS中可用的请求embedding
如果有n个embedding在payload中,在PetPS中组装的一个信息需要1+n个DMAS,多出来的一个用于获取消息header(header在预分配的页锁定DRAM缓冲区中初始化)。利用doorbell batch机制,PetPS只用通知NIC一次就可以启动这些DMA。
在客户端请求中按照特征ID的顺序组织embedding,这一位这id和embedding之间有映射信息。这样可以为每个embedding节省特征ID的空间。
消息布局是不包含embedding的大小的,因为相同类型特征共享相同的embedding大小,可以使用一个type-to-size的表进行记录,在需要大小时可以在这个表中进行快速查找即可。
保护由DMA收集的embedding
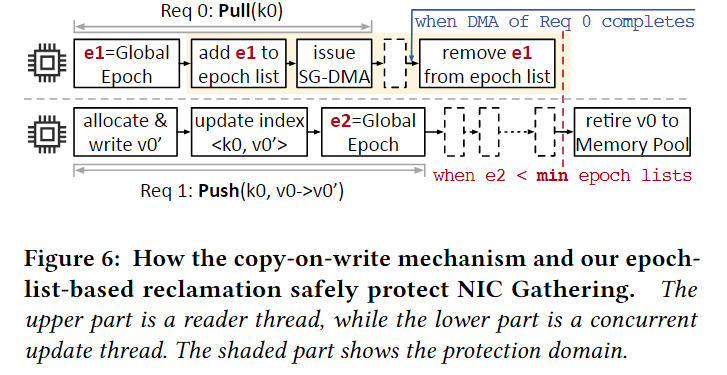
因为DMA是由NIC进行异步执行的,因此PetPS必须保证在DMA执行期间(1)原始的embedding不被修改,并且(2)原始的embedding不能被释放。否则部分更新或者错误的embedding将被发送到客户端。
对于第一点:可以采用copy-on-write机制确保没有原地写(当收到Push请求时,PetPS首先从Memory Pool中分配一个batch的缓存,这个缓存和将被更新的embedding大小相同。然后在按这个缓存中进行更新,然后将这个缓存中embedding原子地更新到PetHash中)
对于第二点:提出了epoch-list-based space reclamation机制。具体来说,对于读取线程,每当它开始处理一个Pull请求时,它都会获取一个全局epoch,并将该epoch添加到其epoch列表中。在完成分散-聚集DMA之后,该列表将删除该epoch。对于更新线程,它首先在逻辑上释放旧版本的嵌入(即,仅更新索引),并将当前全局epoch记录为e. 只有当所有线程的epoch列表中最小的一个大于e,旧版本的嵌入可以被物理释放(即,回收到内存池),在这种情况下,所有读线程和DMA请求都没有对它的引用。如下图所示:
Recovery
PetPS的恢复有两个阶段
- 恢复本地的PM:与现有的PM和KV存储相似
- 从训练集群中跟进未完成的模型更新:像Kafka消息队列一样记录当前模型更新,并周期性地读取每个PS的状态,因此在重新启动之后,停机的PS能够继续使用模型进行更新。







