「论文笔记」JiZhi: A Fast and Cost-Eective Model-As-A-Service System for Web-Scale Online Inference at Baidu
简要
问题:面对数十亿用户的时变网络规模数据,以经济有效的方式将训练有素的深度模型用于在线实时推理服务仍然具有挑战性。
使用DNN进行网页规模的实时在线推理的成本成为大多数公司采用该技术的主要负担
- 在线服务的时间消耗对用户体验至关重要,会影响长期留存率
- 支持DNN的资源消耗将要求大量的服务基础设施投资,并且有时会使系统设计,实现和运行超出预算。
使用GPU,TensorRT等方法可以有效境地DNN的计算延迟,但是这些技术主要针对单个DNN的训练和推理进行优化,忽略了时变网络传输下的在线推理的负载数据和计算依赖关系。因此,实时网页规模的DNN推理服务主要有下面的挑战:
- 巨大且稀疏的DNN模型:需要巨大的空间对他们进行存储,并且检索转换和计算也是比较大的麻烦
- 时变网络尺度传输:推荐系统的推荐请求并发量通常是非常大的
- 多样化的推荐场景:推荐输入可以是图片,文字以及搜索引擎中的用户喜好。
方案:JIZHI——用于网络规模在线推理服务的Model-as-a-Service系统。
- Staged Event-Driven Pipeline(SEDP):基于深度学习的推荐推理工作流都会转化成SEDP,每个节点表示一个分阶段的计算任务,两个节点之间的边表示从一个任务到另一个任务可能的过度。通过这样的方式将负载的计算,以流水线的方式独立运行。
- Heterogeneous and Hierarchical Storage(HHS) module:通过消除荣誉计算和参数访问开销,HHS显著促进了在线推理速度,并提高了吞吐量。
- Intelligent Resource Manager(IRM):自动对系统性能调优,通过自动将任务看成一个约束优化问题,为每一个stage的程序离线时搜索最优的资源分配方案,自适应地基于实时系统反馈控制在线加载分片策略。
贡献:
- 提出了一种基于深度学习推荐的异步在线推理设计,为细粒度资源管理和灵活的工作定制提供了机会
- 针对庞大且超级系数的DNN模型引入了一种具有成本小异的数据放置策略,以轻微的资源开销显著提高了在线推理系统的吞吐量。
- 提出了一种新的只能资源管理模块,以在线和在离线的方式优化系统资源的利用。
系统架构
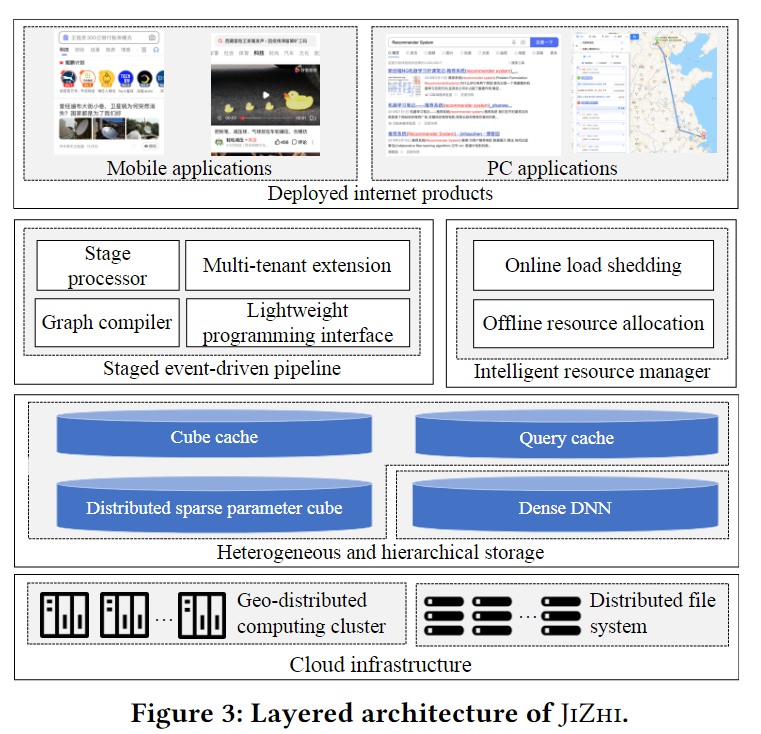
图中展示了JIZHI的结构,他由3个主要的组件组成,Staged event-driven pipeline(SEDP),Heterogeneous and hierarchical storage,Intelligent resource manager。
当收到一个推荐任务时,SEDP首先编译推理工作流成一个有向无环图,然后异步执行图中每一个独立的节点。SEDP能够显著促进基础设施的资源利用率。
HHS是一种基于key-value的数据放置系统,包括分布式稀疏参数cube和异构分层缓存。通过消除不必要的计算和多种I/O开销,存储系统进一步减少在线推理延迟,以开销价值的方式促进系统吞吐量
基于SEDP,IRM通过在线和离线监控以及自动调优服务流水线的计算资源分配,实现准最优资源利用。离线资源管理组件为每个阶段在SEDP和HSS中搜索最优的资源分配方案,以最大化系统的吞吐量。在线资源管理模块实时系统反馈自适应精细调整负载分片策略,保证在负载交大时的服务延迟,同时不牺牲推荐系统的效率。
Staged event-driven pipeline
定义1:阶段处理器:给定一个在线推理工作流,一个阶段处理器被定义为一个元组,其中是特定执行阶段封装功能的单元原语的运算符。是通过共享数据结构将来自上游处理器的时间排队的通道
定义2:阶段事件驱动流水线(SEDP):一个SEDP被定义为一个有向无环图,其中是一个阶段操作,是链接两个阶段处理器和的边。请注意,在一个SED中,所有的边都执行同一阶段的处理器共享同一通道,以提高复杂的时间处理能力,比如aggregation, join and ordering
一个在线推理工作流将被模块化成一个阶段处理器集合阶段处理器可以理解为一个微服务或线程,它是一个可重用和自包含的组件,可以在一个工作中出现一次或多次,依赖于在线推理逻辑。在每个阶段处理器中,操作员同时处理传入的事件,并将完成的事件传递给附加到后续阶段处理器的下一个通道队列。
对于一个预定义好的SEDP,JIZHI可以自动化分析各阶段处理器之间的依赖关系,构造共享通道,并编译完全异构的执行计划。特别是,每一个到达的在线推理请求都被视为一个时间,并被送入下一阶段处理器的队列中。基于图依赖关系,SEDP中的每个阶段处理器都可以按顺序或必行执行。
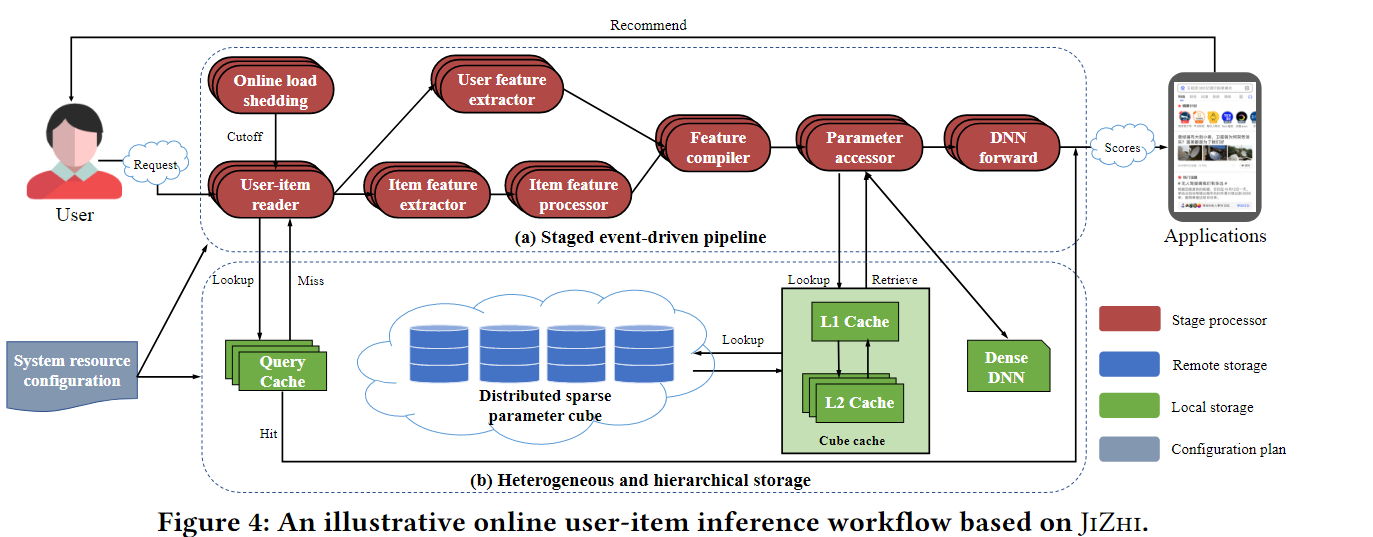
图4 a展示了这个对应的流程,用户和物品信息首先被分别收集并分发到用户特定的处理器和物品特定的处理器中。经过特征过滤,排序等内部操作后,请求的所有原始特征被重新组合以检索相应的特征参数(即余弦计算的embedding和稀疏向量)。最后将蒋所到的系数参数输入DNN网络,得到项目相性评分,进行个性化推荐。
提供多租户的拓展,SEDP可以在单个流水线中同时访问多个DNN。他不仅在单一服务中实现更复杂的推荐策略,还可以实现在线A/B测试的自然支持,有利于推荐系统的迭代。
Heterogeneous and Hierarchical Storage
这里进一步引入了成本小异的数据放置设计,包括分布式稀疏参数cube和异构分级缓存。这两个组件都是为就深度学习的数据推荐方法量身定制的,并可以调用来处理不同的推荐场景。
The Distributed Sparse Parameter Cube
在推荐系统中,DNN通常由巨大的稀疏子网络(TB级)和中等规模的密集网络(MB级),首先引入了分布式稀疏参数cube去管理非常维度很高的稀疏子网络。具体来说,多维数据集是一个只读的分布式K-V存储,其中键被定义为紧凑的特征签名(特征的唯一标识符),值被定义为相应稀疏特征的权重和用户反馈的统计信息。使用通用哈希函数派生特征签名,保证分布式的一致性。在线推理任务可以通过访问cube查询稀疏值。为了降低延迟,key通常放在内存中,value会被组成GB块,可以放置在内存和SSD中,这需要对在线推理和硬件开销进行权衡。通过这样的方式,在异构硬件上运行的多维数据集可以在数据中心以小于10ms的延迟支持10000级并发参数查找。
Heterogeneous and Hierarchical Cache
虽然分布式的稀疏参数cube解决了特征访问延迟的问题,但是在线推理过程仍要进行大量的计算和通信。于是就引入了异构和分层缓存以见底I/O和计算成本。
- Cube Cache:由于稀疏特征的查询具有比较明显的长尾分布,80%的查询只针对1%的数据,于是将hot特征缓存到本地以降低昂贵的网络I/O成本是合理的。cube cache是一个两层的存储结构,持久化存储一小部分在cube中频繁访问的K-V对。这里采用LFU(最小频率使用)的策略去替换cache中的KV对。有两种级别的存储,disk-level用于避免昂贵的网络I/O开销,将1%访问频率最大的k-v对放置在本地的SSD上,memory-level的则是避免disk访问缓慢,将0.1%访问频率最大的k-v放置在内存中。
- Query Cache: 由于在一定时间范围内(2min),同一个用户-物品的分数是不会轻易变化的,因此通过query cache缓存这个分数,将可以避免在模型中进行重新计算。Query Cache被设计为存粹的内存存储,它保存一组最近计算的满足某些条件的用户项得分。为保证推荐的有效性,换出你的分数将在一个固定的时间窗口或用户的反馈之后过期。Query Cache采用LRU(最近最少使用)的替换策略。
Intelligent Resource Manager
Offline Auto-Tuning for Quasi-Optimal Resource Allocation
可以调整的系统参数分为两种
- 系统级的参数——影响全局系统
- 阶段级的参数——在专用的阶段处理器上工作
JIZHI的优化目标为:
其中表示系统中stage处理器的数量, 表示所有可能参数的集合。表示系统级别参数,对于的表示第j个stage处理器的stage级别的参数。和都是参数的默认集。模型 预测基于 and 的参数的第个阶段处理器的资源开销,而模型预测基于 and 的参数的第个阶段处理器的端到端延迟。优化问题的挑战为
- 可行参数应该能够约束每个stage处理器的端到端延迟
- and 是用实际回归模型的集合建立的,这些模型在参数空间上不是自然不可微分的,
- and 的预测结果与真实情况相比,可能是嘈杂和有偏见的
因此,除了常见的基于梯度的方法外,参数搜索还需要全局优化。
JIZHI提出了带约束的协方差矩阵自适应演化策略(CMA-ES),并用于最优计划搜索。目标和约束都编码为黑盒函数,而带约束的CMA-ES以抽样的方式自然地处理这些函数,以实现全局优化。需要注意的是,除了使用CMA-ES得到的最小值外,集智还恢复了CMA-ES的解路径(即已达到的参数),从解路径中提取目标最小的约束满足结果,并在实际系统部署中评估这些结果(即使用总在线请求的5%),以找到全局最优参数。
Online Resource Management for Adaptive Load Shedding
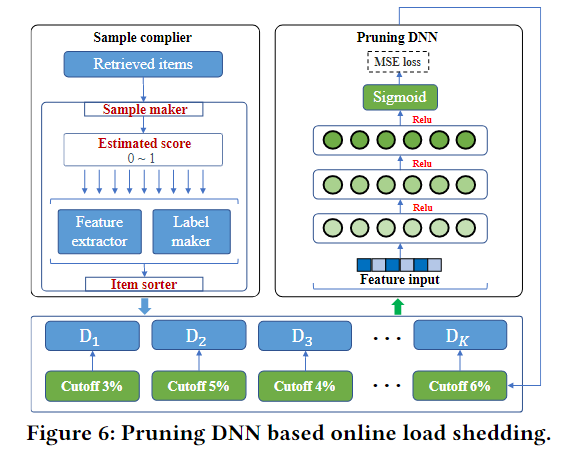
在线资源管理的目标是根据实时的系统反馈,为每个在线推理任务快速推导出新粒度的计算策略,从而处理时变的资源负载。在线资源管理与推荐服务逻辑耦合更紧密,通常需要针对特定任务进行优化。在线减载的关键思想是在推荐效能退化约束最小的情况下,在流量负荷超过系统容量的情况下,自适应地修剪低质量候选节点。形式上,给定一组选定的候选从召回阶段,在线减载组件的目标为:
其中是推荐请求的总数,是计算开销函数,是对应的阶段处理器,是剪枝函数在 上执行剪枝,和 分别为在线减载前后的精度。 是小值界推荐有效性退化。
为了以超高效的方式找到最优修剪策略,我们将约束优化问题转化为回归问题,并使用一个轻量级DNN(又称修剪DNN)来决定候选修剪的数量。具体地说,我们首先通过利用回忆阶段的估计分数对进行排序,然后,我们应用训练良好的DNN来确定每个的cuto线,在cutoff线后面的候选将直接被丢弃,而不经过后续的重新排序阶段处理器。图6描述了在线减载过程的工作过程。基于从上游处理器提取的特征和中间系统延迟等上下文特征,修剪DNN是超轻量的,可以在几十微秒内修剪低质量的候选对象。