「论文笔记」Fleche: An Efficient GPU Embedding Cache for Personalized Recommendations
简要
问题:
- CPU端的DRAM数据访问与GPU处理之间的差距成为深度embedding模型推理性能的阻碍,用GPU-resident cache缓存embedding表可以解决这个差距,但是这个方案并没有被完全探索。
- 现有的缓存方案为每个embedding表维护一个固定大小的cache表,防止在表重分区期间发生大量的数据移动。这样的设计有两个重要的影响因素:缓存利用率低(静态单表缓存的结构缺陷)和内核维护开销(过多的小缓存查询内核)
方案:FLECHE——用于有效GPU-resident embedding caching的新颖缓存机制
- 主要思想:联合设计缓存结构和工作流,从而促进缓存利用率并减少缓存查询时间。
- 结构:GPU-HBM层用于缓存hot embedding,CPU-DRAM层存储所有的embedding(这里只考虑了模型能完全放入内存中的情况,大型模型会另外讨论)
- 为了解决缓存利用率低的问题,提出了flat cache(FC)。其通过将所有的embedding表输入id重新编码为统一格式的flat key,让所有embedding table共享一个全局缓存后端。此外还使用size-aware-coding,为FC量身定制了flat key的格式,减少重新编码带来的key冲突和精度损失
- 为了解决内核维护开销的问题,提出了self-identified kernel fusion。其将小的内核调用合并为一个统一的调用,并让内核中的每个线程确定它最初应该为那个内核调用服务。FLACHE将命中embedding的拷贝和索引FC解耦(FLACHE可以提前查询CPU-DRAM层中丢失的embedding,无需等待复制命中的embedding完成),采用统一索引技术将CPU-DRAM层的部分索引卸载给GPU。
Design
Flat Cache(FC)
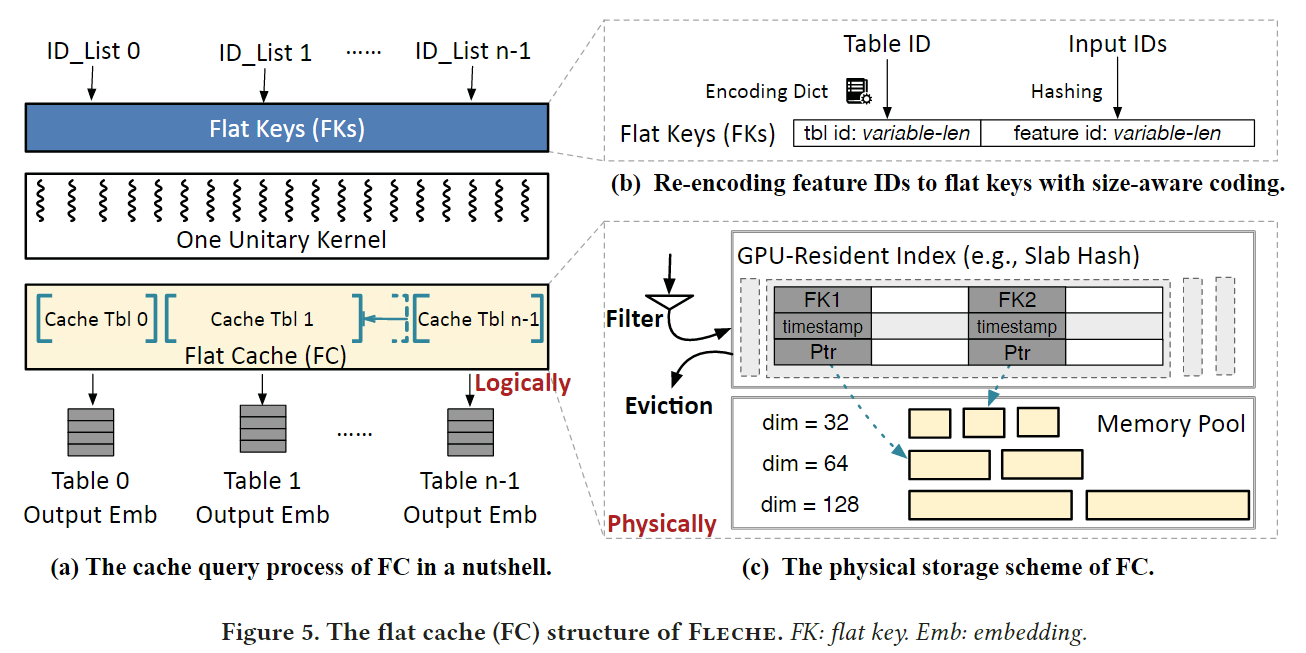
上图简单描述了FLECHE使用FC查询的过程,当收到查询GPU-resident cahce的请求时,想将所有的特征ID转化为统一格式的Flat Keys,然后启动一个在GPU上的统一的Kernel查询cache后端。
Cache table structure
FC使用键值分离的方式进行组织,使用内存池存储来自不同缓存表的embedding(值),使用GPU-resident index维护从flat keys到内存池的映射关系。FLECHE通过根据embedding尺寸预先定义每个slab的大小来避免内存碎片,因为embedding table中的所有embedding都共吸纳预先已知的相同大小。GPU-resident index可以使用任意的GPU哈希索引方法(MegaKV,SlabHash)。FC为每个slot的index引入了时间戳,以近似LRU算法。
FC使用主要知识最小化了metadata的大小,以此来节省HBM的容量。FC不需要像传统KV存储一样保存embedding大小的信息,因为ID与一个特定的embedding表绑定(可以通过embedding表获取其大小),此外每个slot的时间戳可以表示为版本数,以此检测并发读写冲突。在这里,本文使用deduplicating & restoring机制来解决write-write冲突。
Re-encoding IDs to flat keys with size-aware coding
为了区别不同表的同一个ID(城市表ID=13表示北京,用户表ID=13表示小明),需要对ID进行编码,传统采用的定长编码方式只是简单地为所有embedding表保留相同的空间,尽管他们的语料库大小不同,这造成了关键空间利用的不平衡。
为了解决这个问题,本文提出了size-aware encoding方法,关键思想是分配更短的表ID给更大的表,以便于为特征压缩更多的空间。flat key结构被分离为表ID为和特征ID位。每个embedding表(按余量库大小升序排序),为其分配最长的表ID位,剩余的特征ID为足以容纳该embedding表的关键特征。一旦分配了一个表ID,将来应该禁止使用以他为前缀的所有位,以避免表之间的冲突。如果某些嵌入表没有可用的表ID为,本文会保留几个位并按语料库大小的比例分配,这可能会导致表内冲突。
Cache replacement & eviction
FLECHE为这些缺失的embedding执行cache复制操作。为了减少FC因过多的低频率ID而产生的交换开销,本文提出了基于概率的过滤策略。每个embedding都以一定的概率p交换到缓存中,所以小于的时间会在数学期望上绕过缓存。
当内存池的利用率超过一个确定的阈值时,FC采用全表扫描和驱逐cold embeddings执行缓存驱逐,知道内存利用率比另一个阈值低。在这期间可能会遇到读后删除的情况,这意味着要被释放的embedding正在被其他线程读取。FC引入基于批次的空间回收来保证一致性,其首先在逻辑上标记要被驱逐的embedding为deleted,在一个保证其范围内(不在有reader访问这个embedding),延迟其真实回收过程。
Self-identified Kernel Fusion
自主识别的kernel融合可以将cache查询kernel的数量压缩到1,同时支持多cache查询的原生接口。具体来说他由三个阶段组成。假设原生的第i个kernel包含有个线程
-
初始化阶段:CPU初始一个数组(Args Array)来存储原始n个kernel的参数,并计算一个前缀和数组,每个元素包含前i个kernel线程数的和。用公式表示如下,然后我们发出一个有个线程的内核。
-
识别阶段:在这个阶段,每个GPU线程需要识别它在原始的多核场景下的位置。具体来说,对于ID为的线程,他通过在scan上执行一个二元搜索找到小于的最大元素,其索引表示为。这意味着线程对应第个kernel的第个线程。因为所有的线程共享相同的和Args Array,FLECHA能够使用低延迟的GPU流多线程处理器(SMs)的共享内存去加速重复的访问。尽管二分搜索似乎引入了分支分歧(导致性能较差),但在例子中它实际上并不存在。理解它的一个重要性质是,因为是连续的,每32个线程(一个warp)走过的分支条件完全相同,如果每个内核中的线程数四舍五入为warp大小的倍数。
-
执行阶段:现在每个线程能够从Args Array中取出对应kernel的参数,并使用像multi-kernel一样的方式执行相应的job。
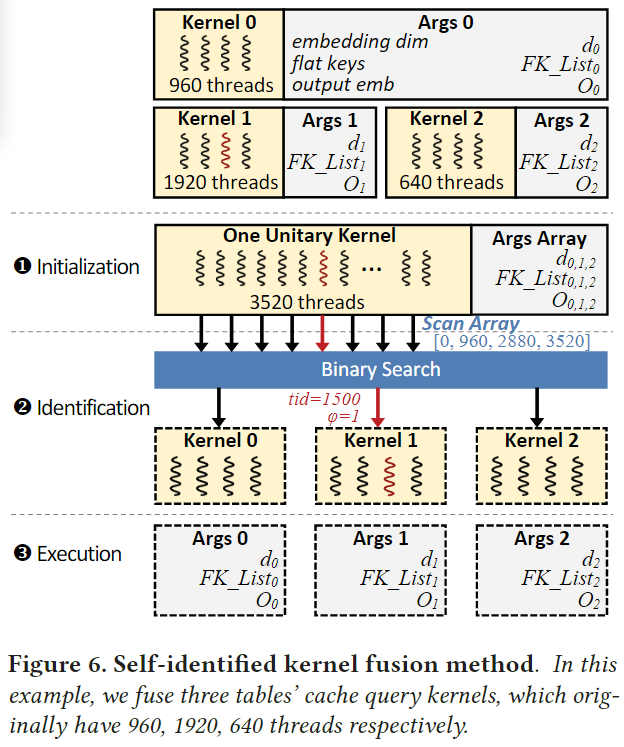
图6展示了一个融合了三个cache查询kernel的例子,最初的三个内核分别由960、1920和640个线程组成。使用前面提到的融合方法,我们只需要启动一次3520个线程的内核,从而减少了维护开销。融合过程在计算图的构建过程中进行。由于DLRM首先使用嵌入转换特性ID,因此所有嵌入表的查询都是同时启动的。它帮助我们找到所有缓存查询操作符,并轻松地融合它们。
Optimizing the Workflow of Cache Query
Decoupling copying from indexing
为了减少kernel数量,现有的每个表缓存方案将索引和复制融合在一个紧密耦合的内核中,但会受到关键路径复制的影响。图7展示了一个例子:
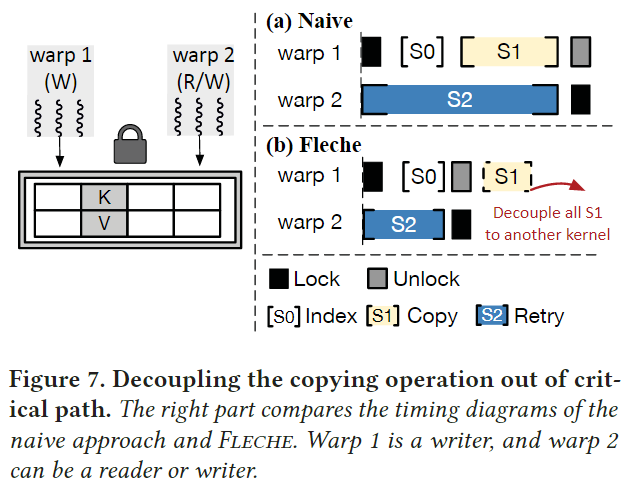
假设有两个warp试图访问某个KV对,如果warp1首先上锁,warp2将重试到warp1结束复制过程并释放锁为止。由于全局内存访问的高延迟,这个复制的时间在GPU中不短。由于缓存通常只使用一次warp(32个线程)来查询一个键并复制所需的embedding,如果embedding的维度大于32,则该warp需要执行更多轮全局内存访问,进一步加剧了锁的时间。
FLECHE的解耦设计适应了缓存操作的工作流。对于查询来说,复制中的kernel从这些地址复制到输出矩阵中。收益于基于批次的空间回收机制,复制中的kernel不需要考虑线程安全。对于回收来说,本文首先运行一个复制中的kernel去从内存池子中复制embedding到已经分配的地址中,然后启动一个索引kernel去修改FC的映射。这是可以实现的,因为复制embedding的过程是不可见的索引。
这种解耦设计有三个好处。首先,将复制操作移出关键路径。其次,我们缩短了复制时间。我们的拷贝kernel不再局限于对整个embedding进行一次warp拷贝,而是可以根据embedding的尺寸启动更多的线程,提高GPU的SM利用率。第三,无需等待kernel拷贝完成,Fleche可以提前查询CPU-DRAM层;见图8b。这是因为一旦索引内核完成了它的执行,我们就已经知道缺少了哪个键。
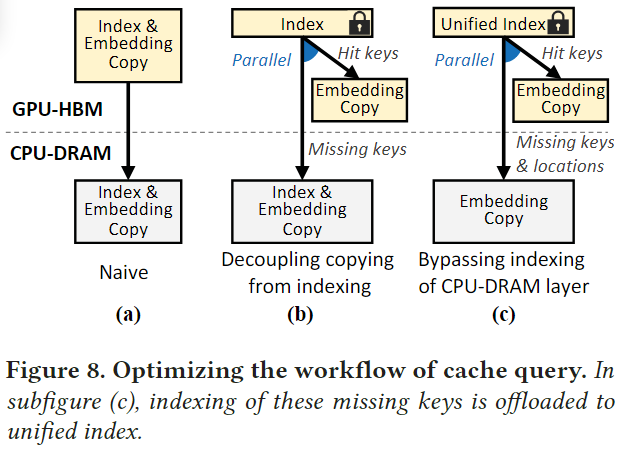
Bypassing indexing of CPU-DRAM layer
Fleche提出了一种统一索引技术(图8c),以进一步缩短缓存查询工作流。该技术将存储在CPU-DRAM层的部分embedding的查找卸载给GPU。具体来说,我们记录这些embedding在FC中的位置,并设置指针的最低有效位来指示CPU-DRAM指针。因此,对DRAM中某些缺失键的缓慢索引被绕过,取而代之的是极其快速的并行GPU查询。虽然在GPU中为CPU-DRAM层维护索引可以提高性能,但它需要额外的内存空间,而这些空间本可以用于缓存embedding。因此,我们需要仔细考虑权衡。
本文给出了一种简单的统一索引内存容量调优方法。我们从一个空的统一索引开始,通过用CPU-DRAM指针替换code embedding的缓存来逐渐增加它的容量。我们暂停增加,直到达到性能峰值。如果检测到显著的性能下降(这意味着工作负载发生了变化),则清除统一索引并重复上述过程。







