「论文笔记」DeepRecSys: A System for Optimizing End-To-End At-Scale Neural Recommendation Inference
简要
现象or问题:在Facebook的数据中心中,超过百分之80的机器学习推理周期都用于推荐和排名推理。
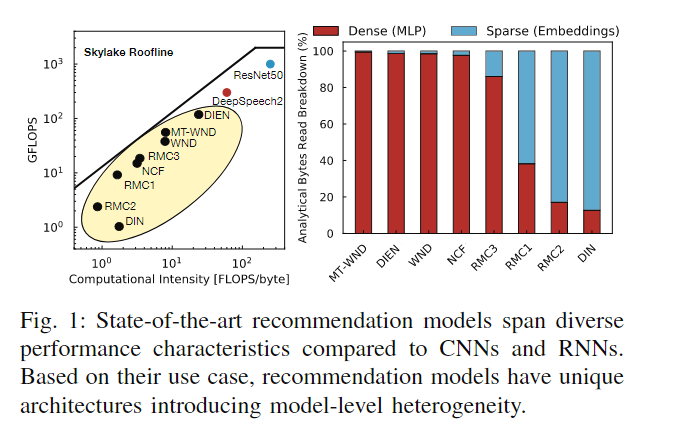
-
不同的模型表现出对计算量和内存访问量不同的特性,图中左边黄色部分的模型更多倾向于计算密集型。
-
从图中右边展示了不同推荐模型,密集特征处理过程通常伴随着规则的内存访问,而稀疏特征则是不规则的内存访问。
-
推荐系统的查询工作集大小遵循一个明显的分布具有较重的尾部效应,这种查询大小分布的差异,导致了不同的规模推理优化策略。
方案:基于hill-climbing的调度器——DeepRecSched——根据查询大小和到达的模式,推荐模型和硬件底层平台将查询分成小批次。DeepRecSched在严格的尾部延迟目标下,通过权衡请求和批处理级并行性,最大化系统负载。
同时设计了DeepRecInfra(端到端的基础设施,用于研究查询大小和到达模式的大规模影响)。
贡献:
- 设计了一个端到端的基础设施——DeepRecInfra,能够通过多种推荐模型进行系统设计和优化。其结合了在产品数据中心上观测到的查询到达模式以及大小分布。
- 提出DeepRecSched——首个批处理调度器,考虑了动态查询到达模式,推荐模型结构以及服务级别延迟目标而量身设计的。
- 跨CPU或者加速器(GPU)的工作分区
- 权衡批处理(数据) 和请求(任务)的并行性
- 证明了GPU计算器可以加速推荐推理,鉴于并非所有查询在推荐推理中都是平等的,本文表明CPU和GPU执行之间的延迟和吞吐量权衡在不同的模型,系统负载和延迟目标之间有所不同,突出了DeepRecSched的动态调度对确定最佳配置的重要性。
DeepRecSched的设计
DeepRecSched是一种推荐推理调度器,为大规模执行优化有延迟限制的吞吐量。其核心是观察到推荐查询的工作集大小遵循一个具有重尾的独特分布。给定严格的延迟目标,大型查询限制了系统可以处理的吞吐量(QPS)。DeepRecSched首先利用批处理(数据)和请求(任务)级别的并行性(将大型查询拆分为多个较小批处理大小的请求。请求由并行核处理,这需要谨慎地平衡批处理级别和SIMD级别的并行性、缓存征用以及由于大量较小请求而可能增加的队列延迟)。此外,大型查询被卸载到专用的人工智能硬件上,以加速大规模推荐推理。
模型多样性要求灵活的优化
首先是不同推荐模型的特征,他们大致可以分为三类,Embedding主导的模型(embedding查找占总运行时间的大部分),MLP主导的模型(全连接计算占总运行时间的大部分),注意力主导的(通常都比较平均或者,循环执行过程不计较长)。如下图所示:
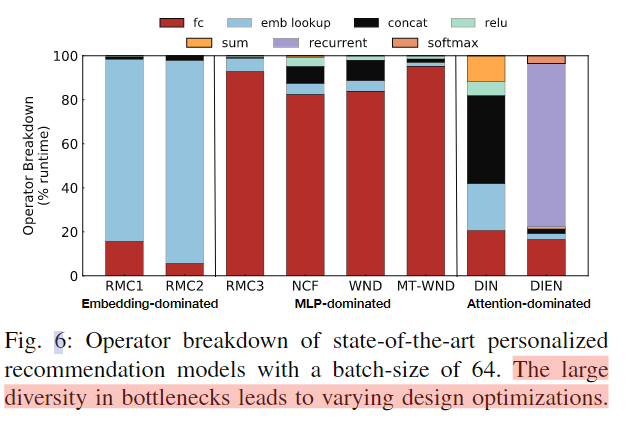
同时不同CPU微架构对推荐模型推理性能也有一定的影响,下图展示了BDW,DIN,DLRM-RMC2三个模型在BDW和SKL的AVX2和AVX512三种不同微架构的CPU上的执行表现:
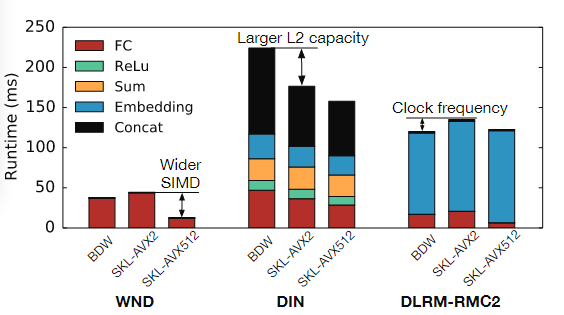
最佳批处理大小不同
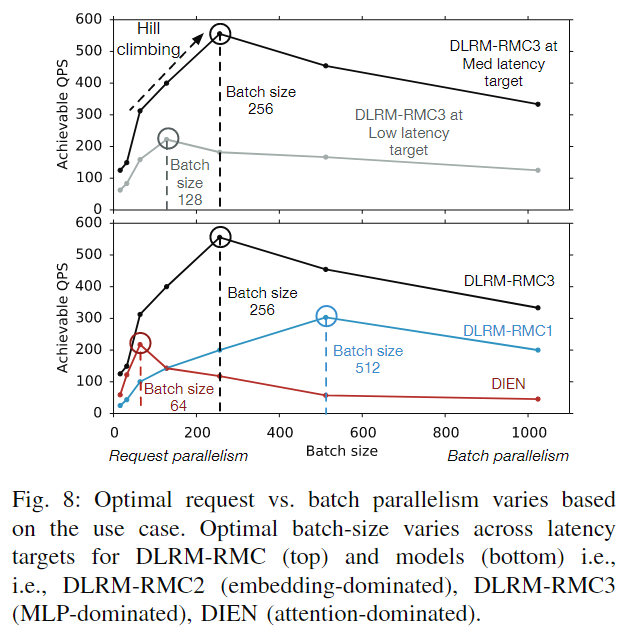
虽然所有查询都可以由单个核心处理,但将查询拆分到多个核心以利用硬件并行性通常是有利的。使系统QPS吞吐量最大化的最佳批处理大小根据尾部延迟目标和推荐模型而变化。图8展示了不同模型,在不同的批次大小下的QPS。回想一下,小批次(请求并行)在多个核上本性处理单个查询,而大批处理(批处理并行)在单个核上处理查询。因此需要在请求并行和批处理并行中进行一个权衡。
利用专用硬件的并行性
DeepRecSched通过卸载能够最好地利用可用专用硬件中的并行性的查询来提高系统吞吐量。图9展示了各个推荐模型在单核CPU下,使用GPU加速的情况。(batch size是条形图上的数字,分别表示最小batch size和GPU能够给模型提升的batch size和最大batch size)
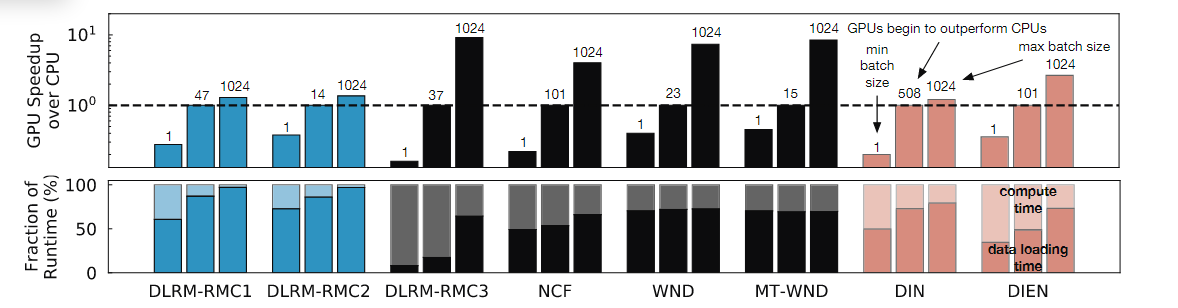
考虑到更高的计算强度和内存带宽,gpu在更高的批处理大小下提供了显著的性能优势——特别是对于计算密集型模型。图中也可以看出,GPU对不同模型性能提升都不尽相同。这是由于将输入从CPU传输到GPU的开销,这消耗了大量的时间。图的下方表示的是数据计算和加载占整体时间的百分比,从图上看,数据挤在时间平均小号GPU端到端推理时间的60%~80%。
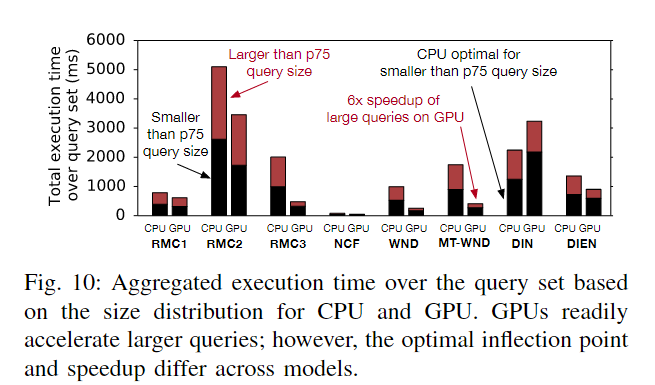
从图10中可以看出,小型查询占大了CPU执行时间的一半以上,25的大型查询占了总执行时间的近50%。在所有模型中,GPU可以有效地加快大型查询的执行时间。虽然卸载大型查询可以减少执行时间,但加速的程度因模型架构而异。卸载的最佳阈值因模型而异,这促使设计能够自动调整卸载决策以进行推荐推断。
将查询卸载到GPU会导致大量的数据传输开销。为了摊销这个成本,GPU通常需要更大的批处理大小来显示cpu的加速因此,DeepRecSched通过将推荐推理的最大查询卸载给GPU来提高系统吞吐量。这可以通过调优查询大小阈值来实现。大于这个阈值的查询将被卸载到GPU上,而较小的查询将在CPU内核上处理。
总结
给定一个特定的推荐模型、硬件平台和尾部延迟目标,DeepRecSched首先调整批处理级和请求级并行性之间的权衡。从单位批处理大小开始,DeepRecSched逐渐增加每个核心批处理大小,以优化系统吞吐量。请注意,DeepRecSched设计用于在启动服务的初始热身期间执行基于爬坡的优化。然后,DeepRecSched调整查询大小阈值,将查询卸载到专门的硬件。从一个单元查询大小的阈值开始(即,所有查询都在加速器上处理),DeepRecSched再次应用爬坡来逐渐增加阈值,直到可实现的QPS降低为止。通过自动调整每个请求的批处理大小和GPU查询大小阈值,DeepRecSched优化了跨各种不同模型架构、尾部延迟目标、查询大小分布和底层硬件的大规模推荐的基础设施效率
方法
DeepRecInfra:
-
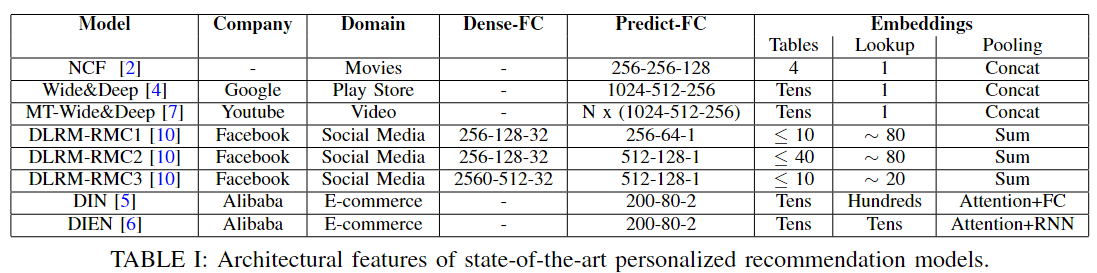
模型实现:在Caffe2中实现了所有推荐模型(表1),英特尔MKL作为CPU的后端库,CUDA/cuDNN 10.1用于GPU。所有的CPU实验都是通过一个Caffe2 worker和Intel MKL线程进行的。
-
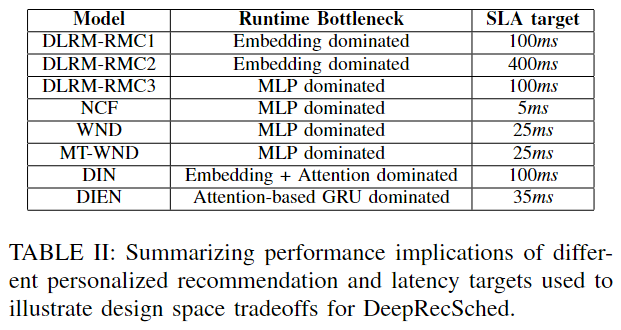
SLA延迟目标:表2个出了每个模型的延迟目标。为了探索一系列延迟目标的设计权衡,本文考虑了每个模型的三个延迟目标(低、中、高)。其中低尾延迟和高尾延迟目标设置为比中尾延迟低50%和高50%
-
实时查询模式:DeepRecInfra中的查询模式可以在两个轴上配置:到达率和大小。到达模式符合泊松分布,而尺寸则来自生产分布。
ps:感觉没有get到这篇文章的点
 微信
微信 支付宝
支付宝







