「论文笔记」PiPAD: Pipelined and Parallel Dynamic GNN Training on GPUs
简要
背景:
- 图神经网络被广泛应用处理图结构的数据并用于提取多种图相关应用的依赖关系
- GCN是在图(聚合)和神经(更新)操作中普遍使用的方法。
- 图的拓扑结构和节点特征可能随着时间的推移而动态发展,由此衍生出动态图。使用GNN的方法可以从动态图中捕获时间和结构信息。根据分区原则和粒度,可以将动态图分为
- 连续时间动态图(CTDG)
- 离散时间动态图(DTDG):对图进行定期采样的快照序列。一般处理方法是使用静态GNN在所有时间步长上的单个快照进行空间图学习。同时部署RNN来获取不同快照之间的时间特征(本文主要关注DTDG-base的DGNN)
- 滑动窗机制可以将多个连续快照同时输入到模型中,这种方式被广泛用于捕获更好的时间依赖并提高准确率。(本文将每一个滑动窗称为帧)
问题:
- 检索稀疏邻接矩阵通常伴随着不规则的内存访问和稀疏计算,SpMM-like的聚合操作通常被认为是GNN的主要瓶颈。
- DGNN引入时间系列组件处理大量的快照,导致了两个主要为的性能问题:
- DGNN训练时要沿着时间轴不断更新图快照,数据传输时间占据了总体训练时间的大部分,进一步加剧了内存密集型的聚合操作产生的GPU利用率不足。
- 时间无关(GNN)和时间相关(RNN)的组件产生了大量的并行机会(并发地在多个快照上执行独立的操作),同时相邻帧之间的快照重叠提供了大量的数据重用机会。
- 现有的解决方案要么主要关注大型图的缩放和分布式训练,要门通过假设图的拓扑(或节点特征)不随时间变化来限制他们的输入场景,这削弱了DGNN的适应性。
动机:
- 真实世界的动态图通常以缓慢的速度变化,在相邻的快照之间呈现大量的拓扑重叠
- 除了SpMM-like聚合的不规则访问模式外,GNN还存在其他类型的内存效率低下的问题,这些问题源于不同节点的特征维度。
- 单图聚合往往会引入带宽不饱和,低线程利用率以及请求突增的问题。总的来说one-snapshot-at-a-time的训练范式不可避免地造成了大量冗余数据传输和低效的内存访问。这些冗余数据传输的主要来源是规范的邻接矩阵聚合操作。为此,提取重叠的拓扑结构,对多个快照进行单一时间无关的聚合操作,不仅可以减少通信量,而且有更多机会实现合并内存访问,解决带宽利用率低的问题。
方案:PiPAD——Pipelined and PArallel DGNN训练框架,用于从算法和运行时级别优化单个GPU上端到端的性能。PiPAD不假设任何输入场景,其通过从数据组织和传输方法到计算方法,重构整个DGNN的训练过程,使其能够流水并行执行。
- 利用图渐变的特性,提出了基于切片的图表示和重叠感知的多快照传输方法(减少从CPU到GPU的数据加载时间,实现高效的并行计算)
- 设计了帧内并行,帧间重用的机制,充分释放了在DGNN上的加速潜能。
- 帧内并行:通过线程感知的切片合并实现了维度感知的并行GNN,以提高更新的聚合和位置优化权重重用。这个方法支持同时处理多个快照,取得了更好的计算性能,并减少了低效的内存访问。
- 帧间重用:最大限度地减少冗余传输和计算开销
- 为了优化整体训练性能,本文实现了一个流水执行框架来协调CPU端的操作,PCIe数据传输和GPU计算。集成了一个运行时调整器来动态调整DGNN训练的并行性和重用级别,以更好地适应各种数据集。
- 本文目标是减少端到端的执行时间,本文执行额外的在线数据处理(图切片)并避免任何离线的模型规模配置。具体来说,PiPAD只提前配置和分析并行GNN内核,以引导在线的调整。
Motivation
DGNN训练的性能瓶颈
-
数据传输开销:图3展示了与GPU相关的训练时间和SM的利用率,从图中可以看出,传输时间占据总时间的
38.7%左右。因此为了减小这个传输时间,利用CUDA流来实现异步数据传输是一种简单而基本的解决问题的方法。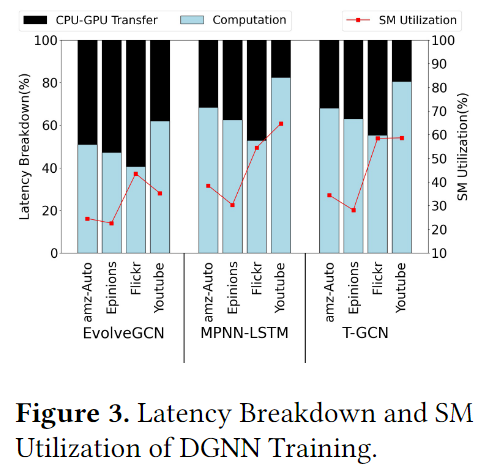
-
拓扑重叠:在实际的动态图中,相邻快照之间的变化率通常在10%左右
GNN中的低效内存访问
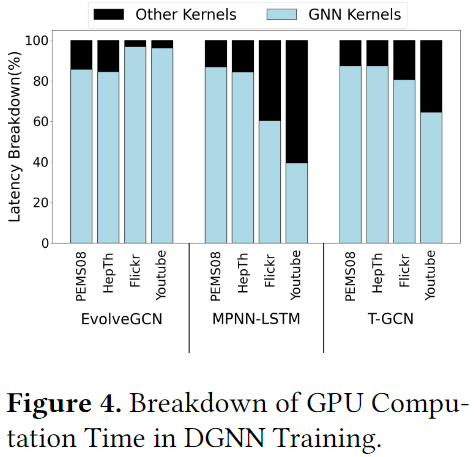
图4展示了GNN kernel的计算是整个DGNN训练的主要负担,因为GNN通常伴随着不规则内存访问的聚合操作(即稀疏矩阵计算相关的内容)。此外,对于不同的输入或聚合特征维度也会导致访存效率低下。在SpMM中,一个warp负责对稀疏矩阵的一个元素与密集矩阵的一行进行计算。为了利用局部性并减小片外访问,GPU核心从全局内存中加载特征,并存储当前迭代的中间结果到共享内存中,在下一次迭代中进行重用。
主流的GPU通常对全局内存访问采用最小32-byte的粒度。单指令多线程(SIMT)中,一个warp由32个线程组成,其在一次请求中最多可以获取128byte(32×4)个字节。考虑到特征矩阵的行长度等于其特征维度数的(F)的4倍,存在两种类型的内存访问低下:
- 当时,带宽未饱和,这意味着有用数据的大小小于单个事物的最小访问粒度
- 当时,请求激增,这意味着访问一行需要对共享内存和全局内存进行多个请求才能完成
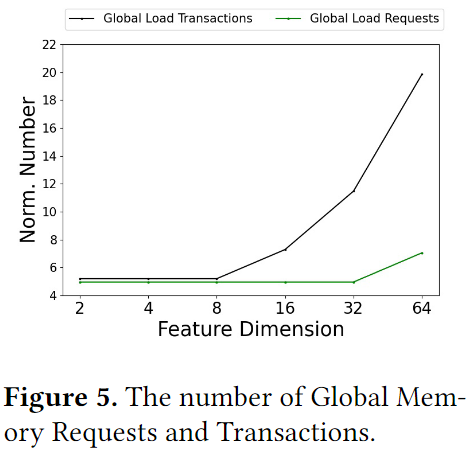
图5中展示了随着特征维度变化,全局加载事务数量和请求数量的变化情况,当F小于8时,事务和请求的数量是一致的,大于8时事务会增加,而请求并不会增加,只有F大于32时,请求才会增加。需要注意的是,在处理F小于32的特征矩阵时,将一行分配给一个warp,意味着warp中的个线程在执行期间会保持空闲状态。
数据重用与并行的机会
- 数据重用:为了在所有快照之间捕获足够的临时交互,时间动态图帧的时间间隔通常设置为1,因此连续帧之间存在大量的重叠,这意味着可以避免一些相关的冗余存储和计算(具体来说就是缓存聚合结果,并在下一帧中进行重用)
- 并行:在之前提到的三种DGNNs中,不同快照中的相同GNN操作能够并行执行。
具体来说,首先考对应的虑拓扑重叠,然后设计了一个新的图形式,他能够有效地提取重叠部分,从而消除冗余存储。然后设计一个并行的GNN计算模式,其可以同时处理多个图。其基本思想是直接在一个带有所有特征矩阵的快照组的重叠拓扑上执行聚合操作。通过这样的方式可以合并多特征的内存访问,并提高带宽利用率。然后进一步使用合适的访问粒度用于避免因大维度情况产生的请求激增的问题。
PiPAD
重叠感知的数据组织
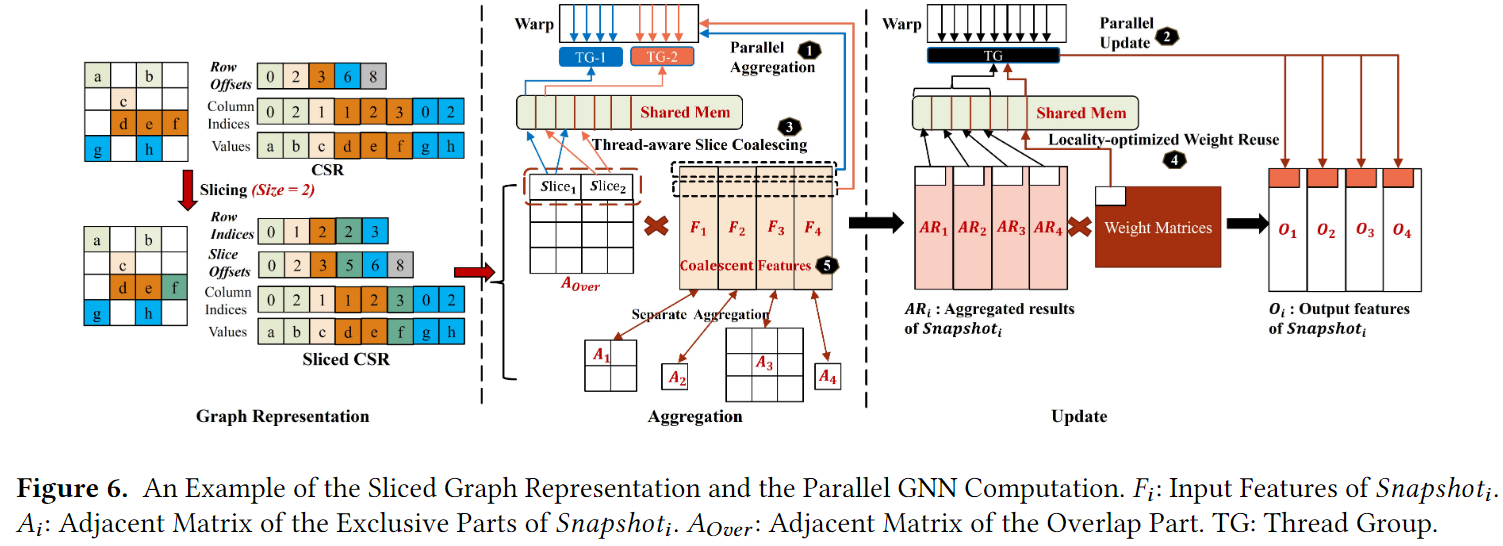
通过提取相邻快照之间的重叠拓扑,并为其构造一个独立的邻接矩阵,能够有效避免不必要的传输,并进一步实现并行计算的思想。传统的CSR存储方式(图6左上角)直接制约了重叠提取的灵活性,导致提取效率低下,此外,在现实世界的图的稀疏性容易导致SpMM的计算不平衡,因为基于CSR表示方式通常将warp设置为处理邻接矩阵的一行或几行。
-
基于切片的图表示:为解决上述问题,通常有二维tile和一维切片来处理,前者将原始矩阵分为更小的多个矩阵,划分每一行并转化整个矩阵为许多切片。前者会由于子矩阵块中nnz的数量不同导致不均匀稀疏,而后者不但能减少空间开销还能通过压缩提供更好的负载均衡。本文就是基于切片的方式进行的,在CSR的基础上将Row offest转化为Row Indices(RI)和Slice Offsets(SO),其他保持不变(图6左下角)。
具体来说:
图中的例子限制了每个切片的NNZ为2,原则上这个切片组织形式,每个要处理一行。
因此RI,用于记录每个切片的行坐标。
而SO则是用于记录每个切片相对于第一个NNZ的偏移量。
比如第一个切片中有两个元素,那么第二个切片对应的SO应该就是第一个切片的NNZ,第三个切片就是第一个切片和第二个切片NNZ之和。
需要注意的是在第三行中分成了两个切片,这主要是图中限制了每个切片的NNZ为2,因此第三行中的三个数据需要分成2个切片。
所以为什么使用这种新的方式就可以感知overlap了呢?
我感觉是因为他采用了比CSR更加细粒度的组织形式,可以控制每次传输的
-
重叠感知的数据传输:拓扑数据(邻接矩阵)被重新组合为所有快照的一个重叠部分和每个快照的几个排他部分,以减少传输量。
-
空间开销:介于CSR和COO之间(系统默认设置每个切片最多包含32个nnz)
- slice CSR:
- CSR:
- COO:
帧内并行
提出了维度感知并行GNN,其同时在多个快照中执行聚合和更新操作(图6的1和2)。进一步设计了三个关键的优化方式
- 基于内存访问的向量内存指令:用于大维度场景
- 线程感知切片合并:用于解决小维度场景下的线程利用率低的问题(图6的3)
- 局部优化的权重重用:以更有效地进行并行更新(图6的4)
维度感知并行GNN
首先合并不同快照的特征矩阵,然后执行一个聚合能够更有效地利用带宽,尤其是对于那些节点特征维度比较小的图中。接着根据重叠感知的数据组织,我们将原始聚合分成两部分:
- 一个快照组中带有所有特征的重叠的邻接矩阵并行聚合(图6的5)
- 每个快照带有各自特征的额外拓扑部分非并行聚合。
利用支持单个请求加载32/64/128浮点数的向量内存指令可以有效解决请求激增的问题。基于这些不同数据获取长度的向量指令,本文在处理具有大维度(大于32)特征的图时,实现了高效的大粒度数据加载。
线程感知切片合并
即使将多个特征矩阵合并成一个,总行数(维度)仍然可能低于32,低线程利用率的问题依然存在。在这种情况下,为了增加每个warp中激活线程的数量,本文合并在邻接矩阵上相邻的线程到一个组中,并设置其作为每个warp基本的处理单元。相应的,同一个warp内的线程被均匀地划分为几个线程组(TGs),每个TG被分配给在一个切片上的单独操作。本文在共享内存上以交互的模式实现切片组布局,以便于从warp的视角出发,单个数据加载访问地址是连续的。在每次计算迭代中,每个TG在对应切片的一个元素和合成特征矩阵的每一行上进行操作。切片组的最大大小(coalesce_num)设置为4,以保证每个TG的数据访问粒度不超过单个内存事务的长度(32bytes)。
算法1展示了并行聚合(在小维度的场景下)的执行细节,输入为:合并的特征,每个切片拥有的nnz的最大数量,以及切片组的最大大小。在具体实现中,每个线程首先以固定的步长将一个特定片中的元素从全局内存加载到共享内存,并且切片索引直接对应线程索引(第4行和,第一个for的内容)。然后,线程获取与分配给它的特征的一个特定维度相对应的数据(第8行和第二个for中用到comp_dim的部分),用相同的步长模式在共享内存能上加载一个目标切片的元素,最后执行计算。(第4行和第二个for和actomicadd)
算法1:并行聚合与切片合并
输入:feature, slice_size, coalesce_num
输出:aggregation_result
- lane_id = getIndexInWarp() // 获取在warp中的id
- // 分别计算分配给当前线程用于加载和计算的特定切片索引
- // 假设有4个TG,那这个共享内存是0,1,2,3,0,1,2,3…排布的,那么下面这一行就是确定要取的是哪一个切片中的元素
- load_index = lane_id % coalesce_num
- // 分母是每个快照的特征dim大小,这个主要用于确定是第几个快照
- comp_index =lane_id/features.dim
- // 计算分配给当前线程的合并特征的特定维度,以进行加载和计算
- comp_dim = lane_id%features.dim // 这个用于确定这个快照的第几个元素
- // 检查当前线程是否被分配了工作
- if comp_index < coalesce_num then: // 这个判断的意思每一个快照进行并行计算
- // 为线程计算具体的工作流大小(每个切片),估计就是每个切片的大小是load_size
- load_size,comp_size = compWork(load_index,comp_index)
- // 加载在切片上的目标元素
- for lane_id to
(slice_size * coalesce_num)do
- // 为加载计算在切片上的元素偏移
- load_offset = nid/coalesce_num
- if load_offset > load_size then:
- break
- end
- LoadSliceToSharedMem(load_offset) // 这个应该就是交替加载的函数
- nid += coalesce_num*features.dim
- end
- // 加载在特征上的目标维度然后计算
- for to comp_size do
- // 计算在切片上的元素偏移并用于计算
- comp_offset = idx*coalese_num+comp_index
- Slice = LoadSliceFromSharedMemToReg(comp_offset) // 加载切片
- Feature = LoadFeatFromGlobalMemToReg(comp_dim) // 加载特征
- MultiplyandACcumulate(Slice,Feature,Partial_result) // 执行一个元素和一行相乘并累加
- idx++ // 所以变动
- end
- automicAdd(aggregation_result, partial_result)
- end
局部优化权重重用
本文保持一个权重tile(图6中更新部分的白框)在共享内存中,然后依次计算所有快照的特征,然后移动到一下权重tile进行相同的迭代。这个局部优化计算范式可以最大程度地重用权重,值得注意的是,这个技术不能在EvolveGCN上使用,因为他是沿着时间轴更新权重的。
对于DGNN的其他内核,则是参考OOB,并利用CUDA Graph API去一起加载这些内核,并减少问题开销。
流水执行框架
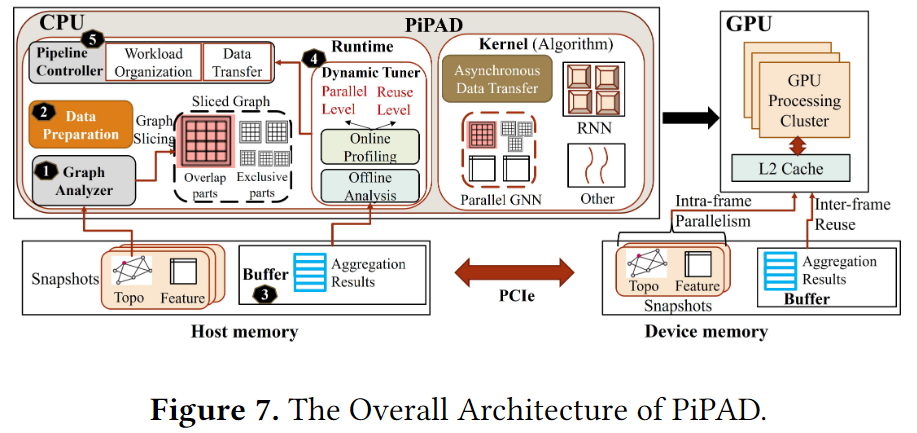
图7展示了PiPAD由算法级别优化和多个运行时级别组件组成,以实现高效的多快照计算和协调一般训练过程。
- 算法级别:设计了切片CSR,以方便地地区图中重叠部分并重构GNN去实现在一个帧上的多个快照的并行计算
- 运行时级别:为了适应新的图格式,首先实现了一个低开销的在线图分析(图7中的1)去有效地将所有的快照格式从原始转化为切片CSR。每个分区的邻接矩阵数据包括公共的重叠和每个快照的单独部分。还设计了一个预处理模块(图7中的2)去执行在所有相邻的快照间提取重叠,为partition-wise的计算方法做准备。上述两个组件只需要在前几个时期(即准备时期)发挥一次作用。为了支持在不同帧之间的数据重用,本文保留了CPU和GPU端的缓存(图7中的3)以缓存聚合结果。基于在准备时期的并行GNN内核和在线配置,在运行时的上层实现了一个动态调整器(图7中的4),用于在线调整并行级别(一个帧内的每个分区中的快照数量)和重用级(缓存在GPU端的聚合结果大小)。最后采用流水线控制器(图7中5)规范了整个训练流程。
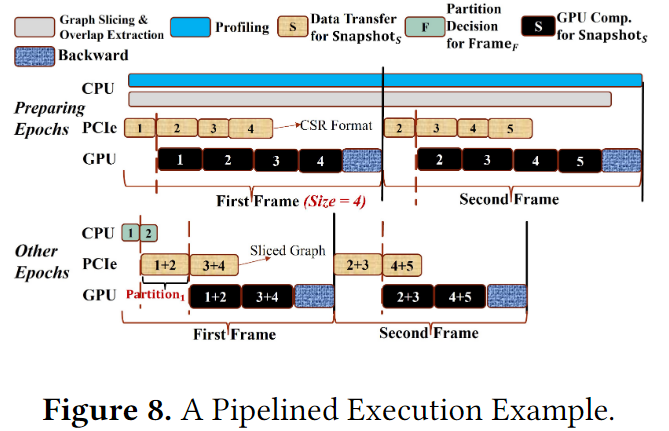
图8展示了一个PiPAD的流水执行示例,其中每个分区设置两个快照,帧的大小为4。在preparing epochs,采用传统的单快照方式,数据进行异步传输。在host端,在在线分析中收集必要的统计数据(每个快照/帧的输入数据大小,执行时间和最大内存消耗)。这些数据用于知道动态调整器选择优化的并行选项,避免出发内存不足的异常。此外由于提取图重叠和准备分区邻接矩阵也需要时间,因此一开始就执行图切片和后续的提取。没给分区的快照数量的配置是一个有限的集合(2,4,8),因此提取开销是可控的,同时还存储了没帧快照之间的图变化率,以便进行在线调优卷册。
对于other epochs,以分区的方式进行训练减少了数据加载开销和提高了计算并行度。首先确定当前帧的并行度,然后传输分区训练数据。由于训练中不同epoch之间的性能相似,本文只执行这个过程一次,并在随后每个epoch中复制到生成的配置中。
开销分析:在preparing epochs中,切片图格式需要额外的空间,还需要辅助图切片的过程。还需要提取重叠的操作分别为每个分区构建基于重叠的邻接矩阵。这些过程可以在前1-2个epochs中完成。此外,在完成分区决策后就可以进行每个分区的数据传输了,由于one-off的操作在CPU中异步执行,并且与前面的分区/帧的其他操作重叠,因此开销也可以平摊。
帧间重用和动态调整
- 帧间重用
GCN的第一层通常是不受时间轴影响的。因此最直接的方法就是存储在preparing epoch中的相关聚合结果到CPU中,并重用这些结果到后续的epoch中。但是这些结果需要传输到GPU并用于下一帧,因此本文设置了GPU端的缓存,基于下一帧的使用顺序缓存一些聚合结果。根据preparing epoch中分析的统计数据,根据需求为每个帧动态分配不同大小的缓冲区。值得注意的是malloc/free函数的执行是耗时的,本文只在先前的内存大小不足以支持新的中间变量存储时才重新分配。
- 动态调整
动态调整器需要为每个帧决定两个关键的参数:每个分区中的快照数量,为下一帧重用所缓存在GPU中的聚合结果大小(由帧间重用提到的GPU内存使用方式决定)。
对于则是有3个影响因子:
- 内存开销:多快照的方法会由于要处理每个分区中相关的快照数据而出现GPU内存使用率增加的情况,因此需要避免OOM的异常。
- 并行GNN的计算加速:帧内并行的加速效果会随着不同的输入图和的值而变化
- 计算和数据传输之间的重叠级别:多快照处理不仅促进了计算阶段的性能还会增加单次传输的数据大小,这可能会拖后流水线的执行并导致GPU利用率较低。
决定的步骤如下:
-
由于采用的是重叠感知的数据组织方法,所以N个快照并不需要N倍的内存,本文利用在线分析的统计数据,可以推导出一个上界以确保不会出发MMO
-
,单图节点的维度以及每个分区中所有快照的重叠率(OR)都会影响计算加速的效率。图9展示了不同重叠率,不同以及不同维度对加速的影响。从图中可以看出,在相同的OR或者特征维度下,越大,表现越好。本文利用离线分析的结果和在preparing epoch中获得的实际逐帧拓扑变化率统计数据得出所有可用的选项
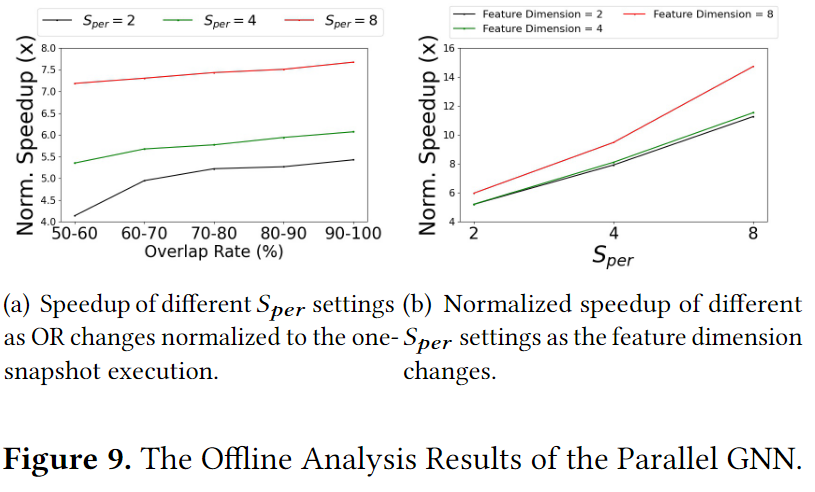
-
然后使用之前分析的数据大小信息分析了每个选项的数据传输延迟,不采用所有会使流水线延后的方案,并从剩下的方案中选出计算加速最高的一个。通过对每个帧使用特定的并行性和重用选项,我们的管道控制器协调整个训练。
讨论
虽然PiPAD采用pytorch顶层结合C++,CUDA C和python实现,但是这个方法是通用的,独立于任何特定的深度学习或GNN框架。
限制:多快照的训练会不可避免地阶段性增加内存开销,造成大规模图固有的缩放问题。这个限制将会在PiPAD支持多GPU训练后被解决。
Evalueation
PyGT->PyTorch Geometric Temporal
PyGT-A:添加了异步数据传输
PyGT-R:使用帧间重用机制
PyGT-G:比PyGT-R多使用了GE-SpMM替换原始的GCN模块
| name | PyGT-A | PyGT-R | PyGT-G |
|---|---|---|---|
| Asynchronous data transfer | √ | √ | √ |
| Inter-frame reuse | √ | √ | |
| GE-SpMM | √ |
大型数据集:amz-Auto,Epinions,Flickr,Youtube
小型数据集:HepTh,Covid19,PEMS08
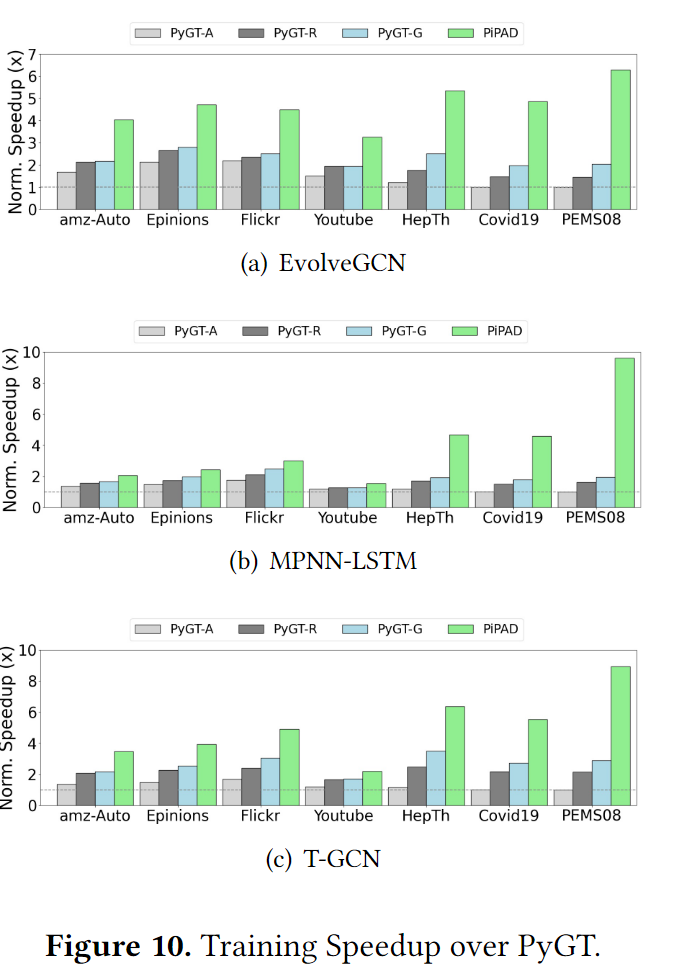
实验结果的总览如图10所示,PiPAD比其他的方法总是取得最佳的结果,并且在小型数据集上的提速更多,因为在大型数据集上帧内包含的快照数比较少,帧内并行的优势无法充分发挥。次优的是PyGT-G,与PiPAD的差距就在于帧内并行。图11展示了GPU利用率,PyGT-R和PyGT-A的GPU利用率更高,这是因为PiPAD和PyGT-G的GPU计算时间大大减少,扩大了CPU端操作所需要的时间占总时间的百分比。并行的GNN减少了发布的内核数量,所以PiPAD的性能由于PyGT-G。

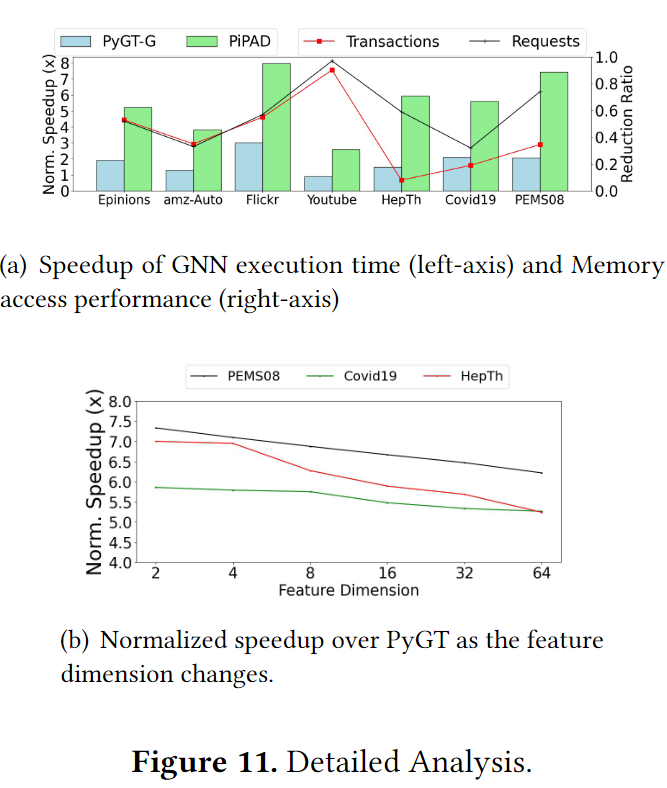
图11(a)的左轴展示了只用一个GNN模块,分别采用GE-SpMM和并行GNN方法计算的加速比。从速度上后者使用的是低效的单快照处理方法,后者则是同时处理多个快照。显然是后者取得了更快的速度。右轴则是,事务和请求的减少率,两者都使用了共享内存来优化邻接矩阵的访存,而后者采用了合并的内存访问获取多个特征矩阵。对于大规模数据集,加载16byte的特征,并行GNN只用一个事务同时处理两个图,而GE-SpMM则需要两个独立的事务去处理这两个图。对于小规模数据集,GE-SpMM加载64byte的数据会产生一个内存访问请求和两个事务去处理一个图,而PiPAD加载256byte的数据只使用一个内存请求和8个事务同时处理4张图。大粒度的访存避免了请求激增的问题。在Youtube中减少最大,是因为其过于稀疏,需要大量冗余的访存,但是PiPAD中的sliced CSR避免了这个问题。图11(b)则进行了维度的敏感度分析,随着维度的改变PiPAD仍然能取得至少5.2倍的加速
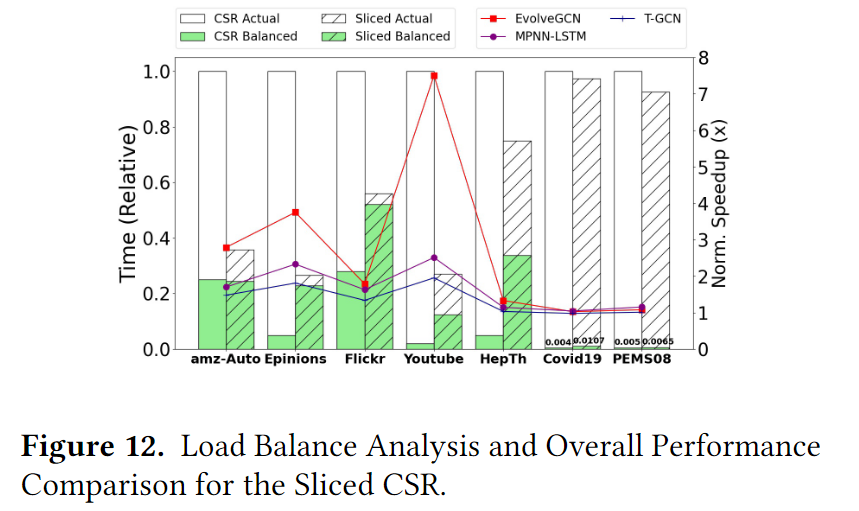
这里采用了csr和切片CSR两种存储格式对PiPAD进行改造。图12的左轴展示了相对执行时间,其中绿色的条形图表示在完全理想的负载均衡下,执行计算所需的时间,而白色的条形图则是实际的执行情况。从图中可以看出切片CSR的使用显著减少了模型的执行时间,尤其是在大型数据集中,在小型数据不明显的原因主要是其没有太多的冗余数据可以消除(密集的部分太多),同时也可以观察到,采用切片的CSR后在大型数据集中负载均衡的时间基本上是总时间的一半以上。右轴则是表示在不同模型下采用CSR和切片CSR的加速比,表现与负载均衡的结果基本一致。RMM




